
آیا میدانید scrapy چیست ؟ پیش از این آموزش وب اسکریپینگ، به صورت مقدماتی و پیشرفته در همرویش منتشر شد. حال در این آموزش اسکریپی قصد داریم در قالب یک پروژه جذاب (با طعم فیلم و سریال!) به شما آموزش دهیم که چگونه با امکانات فریمورک scrapy یک وب اسکرپینگ راحت را تجربه کنید.
scrapy چیست ؟
فریمورک اسکریپی به انگلیسی Scrapy (که به صورت skrey-pee تلفظ میشود) یک فریمورک متن باز و رایگان پایتون در حوزه وب اسکریپینگ و وب کراولینگ است. این فریمورک یک ابزار محبوب، ساده و در عین حال قدرتمند برای استخراج اطلاعات به صورت ساختاریافته از وبسایتهای گوناگون به شمار میآید.
در واقع Scrapy مانند یک ربات گنج یاب، آماده استخراج دادههایی ارزشمند برای شماست! کافیست به او بگویید از کدام وبسایت یا صفحه اینترنتی، میخواهید چه اطلاعاتی را استخراج کنید. پس از گذشت چند ثانیه، اطلاعات موردنظرتان در اختیار شماست!
سپس میتوانید این دادههای استخراج شده را پردازش کنید. در ادامه دادههای پردازش شده را به صورت ساختاریافته در یک فایل با فرمتهایی نظیر csv و json یا حتی در پایگاه داده ذخیره کنید.
بنابراین به جای اینکه از صفر شروع کنید و زحمت استفاده از کتابخانههایی نظیر BeautifulSoup و requests را به خودتان بدهید و پس از نوشتن چندین خط کد، تازه به کد html وبسایت مدنظرتان دست پیدا کنید، کار را به scrapy بسپارید. (اصطلاحا نیازی نیست که چرخ را مجددا اختراع کنید!)

هدف نهایی این پروژه:
استخراج اطلاعات فیلمها (نظیر عنوان فیلم، نام کارگردان و بازیگر، امتیاز فیلم و ..) از وبسایت مشهور imdb است.
پیشنیازهای این دوره:
آشنایی مقدماتی با زبان برنامه نویسی پایتون و مفاهیم اولیه وب اسکریپینگ و وب کراولینگ است. همچنین این آموزش، در محیط پایچارم (pycharm) انجام می شود.
این آموزش در یک نگاه:
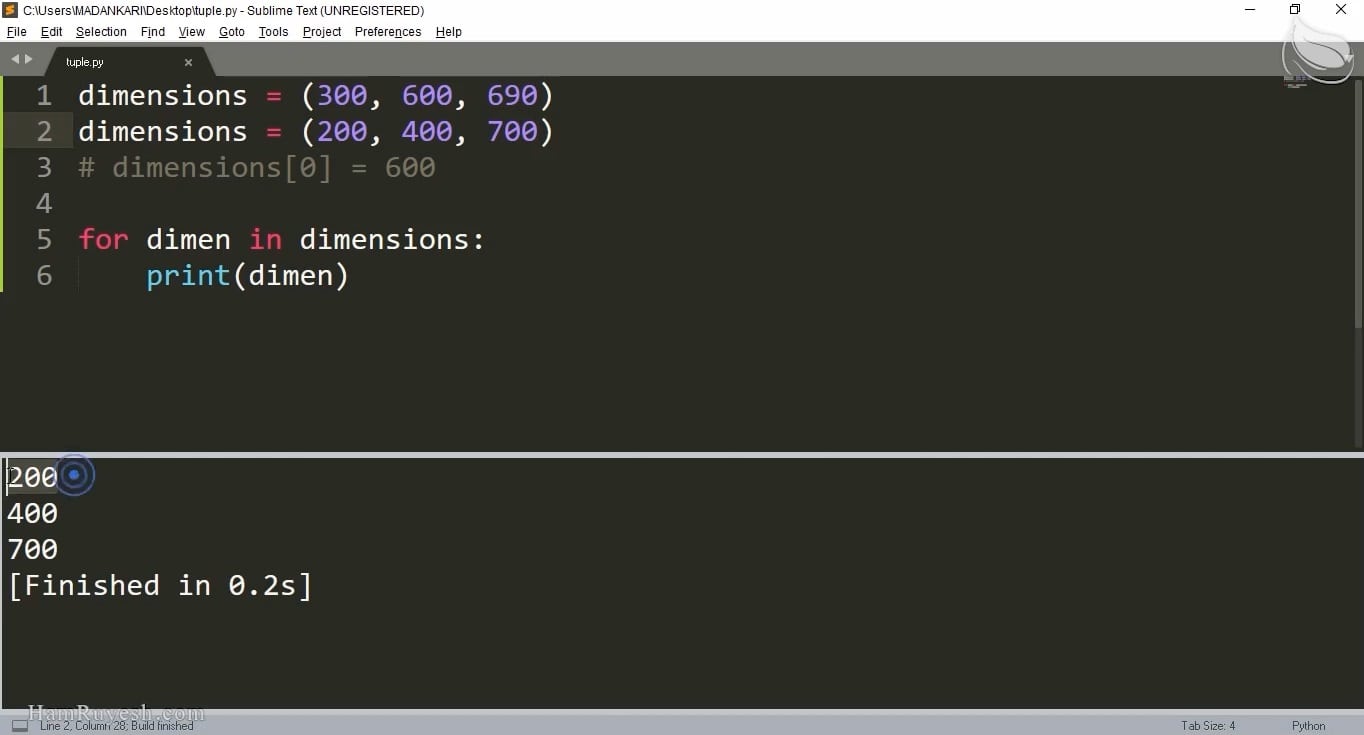
پس از نصب scrapy در محیط پایچارم، اولین پروژه و برنامه خود را ایجاد میکنیم. این برنامه (که در scrapy به آنها اسپایدر گفته میشود)، عنوان یک فیلم را از وبسایت imdb استخراج کرده و نمایش میدهد.
در ادامه با استفاده از مفهوم قانون (Rule) بر روی لینکهای مختلف وبسایت imdb خزش میکنیم. یعنی رباتی طراحی میکنیم که به دنبال لینکهای مختلف در وبسایت imdb بگردد و سپس، عنوان هر فیلم را از درون این لینکها استخراج کند.
سپس با محیط shell در scrapy آشنا میشویم. این محیط چیزی شبیه به کامندلاین ویندوز است. این امکان را به ما میدهد تا دستورات را بلافاصله اجرا کنیم. دیگر نیازی به نوشتن چندین خط برنامه نیست.
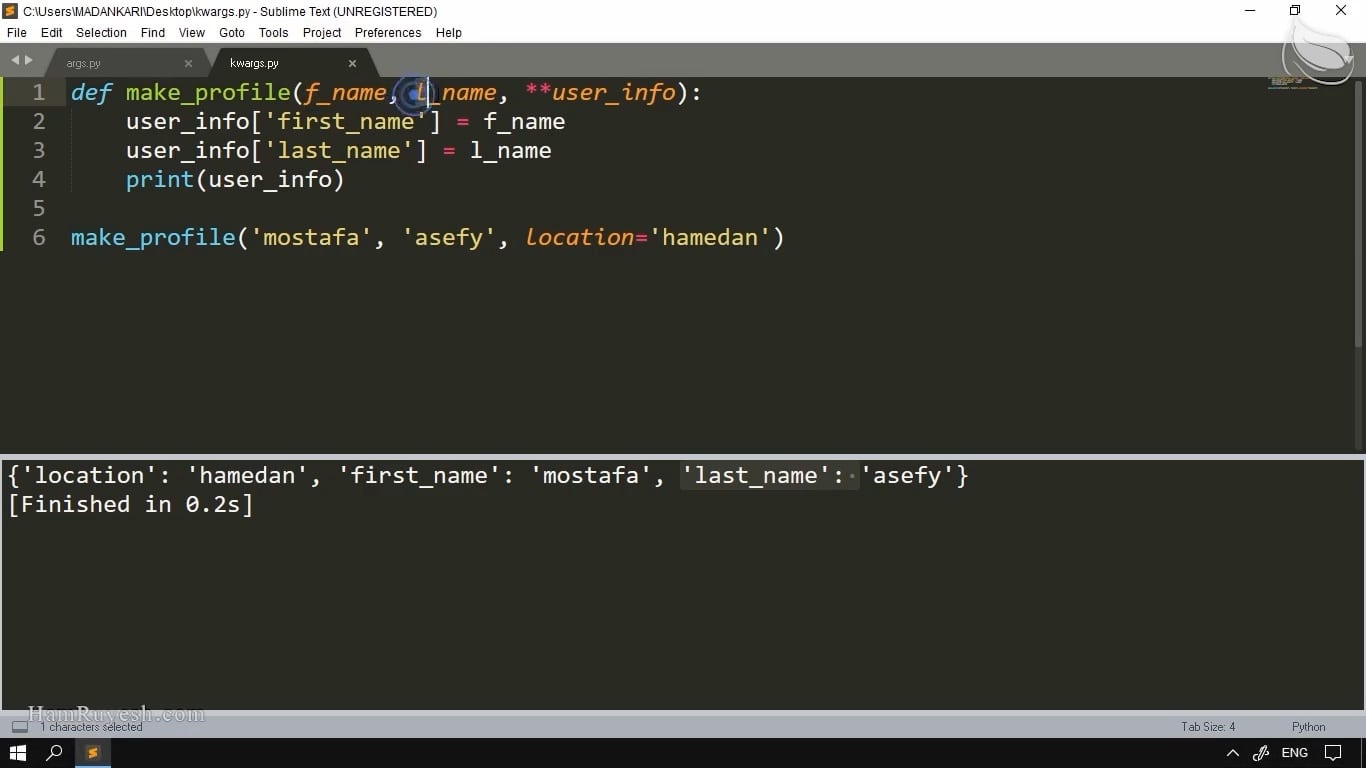
در ادامه، با css سلکتورها و xpath سلکتورها آشنا میشویم. مهمترین و پرکاربردترین سلکتورها را به صورت عملی با هم مرور میکنیم. با استفاده از این سلکتورها میتوانیم اطلاعات مختلف را از دل وبسایتها استخراج کنیم. اکنون پس از آشنایی با این سلکتورها، میتوانیم اطلاعات مختلف هر فیلم (نظیر نام کارگردان و بازیگر و … ) را استخراج کنیم.
سپس با مفهوم آیتم در scrapy آشنا میشویم. دادههای استخراج شده را آیتم بندی میکنیم.
پس از آن، دادههای خود را به صورت ساختاریافته در قالبهای مختلف نظیر csv و json و xml ذخیره میکنیم.
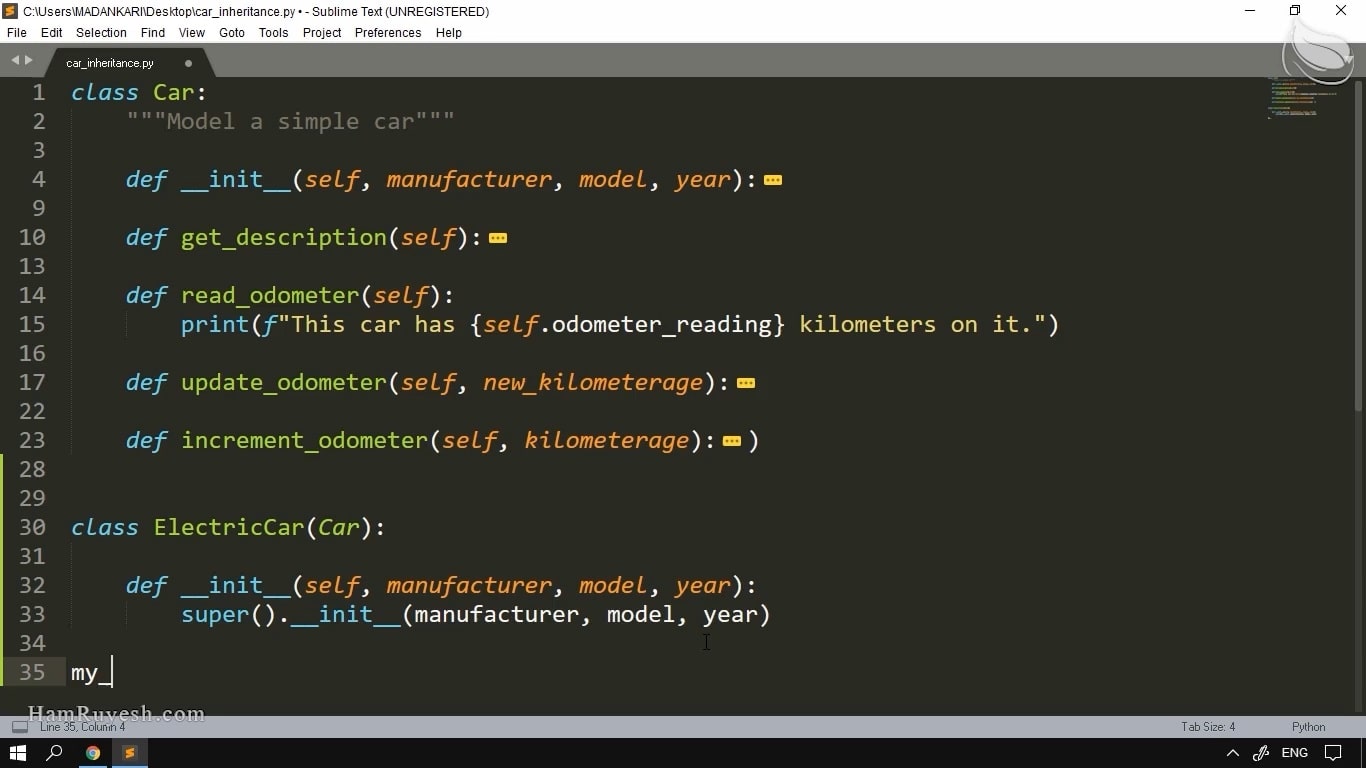
در ادامه، با مفهوم پایپ لاین در scrapy آشنا میشویم. با استفاده از این مفهوم و به کمک برخی کتابخانههای پایتون، عنوان انگلیسی فیلمها را به فارسی ترجمه میکنیم. در نهایت نیز با گزارش گیری از روند اجرای برنامه یا لاگینگ و سطوح مختلف آن آشنا میشویم.
نکته پایانی:
سرفصلهای این آموزش، با الهام گیری از فصل پنجم کتاب web scraping with python، نوشته Ryan Mitchell تدوین شده است. در صورت علاقه، می توانید به این منبع مراجعه کنید.
این آموزش بی نظیر است زیرا:
- کاملا پروژه محور است.
- در کنار آموزش فریمورک، به استخراج داده از وبسایت imdb پرداختیم.
- پروژه آموزش بسیار جذاب و کاربردی است چرا که در نهایت شما میتوانید اطلاعات مختلفی را از دل فیلمهای وبسایت imdb (نظیر نام کارگردان، بازیگر، سال تولید و امتیاز فیلم ها) استخراج کرده، به فارسی ترجمه و در یک فایل مجزا ذخیره کنید.
- با روشی جدید و به صورت کاملا بهینه تهیه و تدوین شده است.
- در کنار توضیحات اولیه مدرس، در طول هر درس، توضیحات به صورت متنی همراه با جلوههای بصری دیگر، در حین کدزنی برای شما نمایش داده میشود که فرایند یادگیری را برایتان جذاب و بهینه میکند.
- مطالب بیان شده، قابل تعمیم به سایر وبسایتهای داخلی و خارجی و بسیاری ایدههای جذاب دیگر است.
کلیدواژگان
آموزش scrapy پروژه محور | scrapy در پایتون | اسکرپی پایتون | دانلود scrapy | آموزش python scrapy | scrapy چیست | فریمورک scrapy | ساخت خزنده وب با پایتون | آموزش crawler با پایتون | کتابخانه scrapy | نصب scrapy | اسکریپی در پایتون | آموزش پروژه محور scrapy | Scrapy | یادگیری پروژه محور اسکریپی | Scrapy in python | آموزش اسکریپی | scrapy چیست









S.Mojtaba (خریدار محصول) –
سلام روزتون بخیر
در درس پنجم که درمورد کراول کردن روی 250 فیلم برتر IMDB آموزش دادید
هیچ لینک تکراری نبود و دقیقا 250 لینک خروجی داشتید
اما برای من این اتفاق نمیفته و لینک های تکراری برگشت داده میشوند
حتی اسپایدر خودتون رو اجرا میکنم، بازهم این مشکل وجود داره
سعی کردم با قرار دادن یک set() جلوی بررسی لینک های تکراری رو بگیرم
اما تاثیری نداشت
برای رفع این مشکل پیشنهادی دارید؟
S.Mojtaba (خریدار محصول) –
مسئله اینجاست که در اولین تلاش این خطا رخ داد
از دیروز تا امروز صبر کردم و مجددا با همون خطا مواجه شدم
روی سایت های دیگه ای تست کردم و نتیجه گرفتم
اما روی سایت IMDB همچنان این خطا رو نمایش میده
پیشنهادی برای رفع خطا دارید؟
محمدحسین ماجدی نیا –
چند تا راه حل وجود داره. مثل استفاده از user agent فیک. پیشنهاد میکنم نگاهی به این لینک بیندازید:
https://www.zenrows.com/blog/403-web-scraping#seven-easy-ways-to-bypass-error-403
S.Mojtaba (خریدار محصول) –
سلام
بعد از توضیحات ویدیوی جلسه سوم این دستور رو run کردم:
*******************************************************
import scrapy
class ExampleSpider(scrapy.Spider):
name = “example”
# allowed_domains = [“example.com”]
start_urls = [“https://www.imdb.com/title/tt1375666/”]
def parse(self, response):
print(response.css(‘h1’).extract_first())
*******************************************************
و با این خطا روبرو شدم
2024-03-17 11:01:38 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2024-03-17 11:01:38 [scrapy.core.engine] DEBUG: Crawled (403) (referer: None)
2024-03-17 11:01:38 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response : HTTP status code is not handled or not allowed
اینطور که من متوجه شدم IMDB برای ربات ها محدودیت ایجاد کرده و سرور پاسخ نمیده
اگر اینطور هست چه راهی پیشنهاد میدید تا این محدودیت رو دور بزنیم؟
محمدحسین ماجدی نیا –
سلام وقت بخیر. یک احتمال این هست که گاهی اوقات وقتی در یک بازه زمانی تعداد ریکوئست های ربات به یک وبسایتی زیاد میشه، اون دامنه بطور موقت ربات رو مسدود میکنه. مدتی صبر کنید و بعد دوباره اقدام کنید.
محمد –
سلام ایا اموزش میدید چه طوری خروجی رو روی وب قرار بدیم ؟ مثلا json چه طور این کار انجام میشه ؟
محمدحسین ماجدی نیا –
سلام به شما. توی این آموزش نحوه استخراج داده ها و ذخیره اونها به فرمت های مختلف (از جمله json) آموزش داده شده ولی روی وب قرار دادن خروجی جزو این آموزش نیست.
محمد (خریدار محصول) –
عالی عالی
از این دست ویدیوهای اموزشی بیشتر بسازید واقعا متشکرم ازتون
محمدحسین ماجدی نیا –
سلام. خواهش میکنم! ممنون از شما که این همه انرژی مثبت فرستادید و نشون دادید ارزش وقتی که برای آموزش گذاشته شده رو درک کردید 🙂 .
rezbba2@yahoo.com (خریدار محصول) –
شما که کار را با این گرافیک زیبا در آوردید . یک آموزش اسکرپی پیشرفته سایت های جاوااسکریپتی
برای splash، سلنیوم و playwright هم بزنید
اولین خریدار منم
رضا علیزاده (خریدار محصول) –
سلام
ممنون از تدریس عالی به ویژه برای استفاده از توضیحات گرافیکی در حین اجرای ویدیوها ،
لطفا بفرمایید برای حل مشکل واکشی اطلاعات فارسی (که در ترمینال و یا فایل های خروجی برعکس چاپ میشود ) از چه کتابخانه و چه روش بهینه ای میتوان استفاده کرد
با تشکر
محمدحسین ماجدی نیا –
سلام و ممنون از انرژی مثبت و حال خوبی که منتقل کردید و ظرافت های آموزش و زحمتی که برای تهیه اون کشیده شده رو درک میکنید! در فایل های خروجی معمولا این مشکل نمایش وارونه کلمات فارسی کمتر وجود داره ولی بطور کلی یکسری کتابخانه ها مثل arabic_reshaper و python-bidi برای نمایش صحیح عبارات فارسی (در صورت بروز مشکل) وجود داره . اما در مورد ترمینال پایچارم، گویا کلا با فونت فارسی و عربی مشکل داره و تا این لحظه من به راهکاری برای این قضیه نرسیدم (با اینکه روش های مختلفی که در برخی سایت ها گفته شده رو هم امتحان کردم). اگر راه حل دقیق و مناسبی پیدا کردم حتما بهتون اطلاع میدم.
هومن (خریدار محصول) –
سلام وقت بخیر من میخواستم خصوصیت title تگ a مربوط به رنگ های محصول رو در صفحه زیر بخونم لطفا راهنمایی کنید
https://www.trendyol.com/hummel/guile-kisa-kollu-tisort-p-32094870
محمدحسین ماجدی نیا –
سلام وقت شما هم بخیر.
لطفا رجوع کنید به پاسخی که در دیدگاه قبلی نوشتم و راهکارهایی رو معرفی کردم.
HAMID (خریدار محصول) –
با سلام
من هر کاری می کنم روی سایت bama. ir نمی توانم خزش کنم. ظاهرا اونا کاری کردن که اجازه خزش رو به روبات های پایتونی ندن. شما در مورد این قبیل سایتها راهکاری رو دارید؟
محمدحسین ماجدی نیا –
سلام
چندتا رفرنس بهتون معرفی میکنم که بطور کلی برای استخراج داده از سایت هایی که یا بر مبنای جاوااسکریپت هستند یا اطلاعات داخل تگ script یا nonscript قرار گرفته که یه مقدار مسیر وب اسکریپینگ رو پیچیده تر میکنند، مفید هستند:
مورد اول بر اساس مستندات خود اسکریپی هست:
https://docs.scrapy.org/en/latest/topics/dynamic-content.html#parsing-javascript-code
مورد بعدی استفاده از برخی ابزارهای کمکی مثل splash، سلنیوم و playwright هست که میتونید با سرچ بیشتر، در موردشون اطلاعات کسب کنید. شاید در اینده، اموزش هایی در این زمینه منتشر کنیم.
صابر (خریدار محصول) –
سلام. در ابتدا ممنون بابت این دوره فوق العاده.
میخواستم بپرسم چطور میشه اسپایدر خودمون رو از طریق یک آپ با کیوی و یا مخصوصا از طریق جنگو run کنیم و از نتایج آن در وب سایت خودمون استفاده کنیم
محمدحسین ماجدی نیا –
سلام و تشکر از شما!
فکر میکنم لینک زیر، دقیقا مرتبط با ایده ای هست که شما در ذهن دارید:
https://scrapy-django-dashboard.readthedocs.io/en/latest/introduction.html
(داخل پرانتز! در کنار کیوی و جنگو، پیشنهاد میکنم سری هم به آموزشی که درباره streamlit هست بزنید. این آموزش ایشالا به زودی در همرویش منتشر میشه و چارچوبی هست برای توسعه ساده و سریع یک وب اپلیکیشن پایتونی.)
Parmis (خریدار محصول) –
سلام اگه بخوایم تو محیط colab اجرا کنیم امکانش هست؟ و چطور از ترمینال استفاده کنیم در colab
محمدحسین ماجدی نیا –
سلام وقت بخیر
در کل پیشنهاد نمیشه که توی محیط کولب یا نوت بوک اجرا کنید چون شاید یک مقدار اذیت کننده بشه ولی امکانش هست.
اگر از نسخه colab pro استفاده کنید، خودش امکان استفاده از ترمینال رو براتون فراهم میکنه (یه گزینه داره سمت چپ پایین صفحه)
ولی به طور کلی، میتونید ترمینال رو شبیه سازی کنید. سایت های مختلف کدهای مختلفی رو برای این کار ارئه کردن. من پیشنهاد میکنم سری به کدهای موجود در این صفحه بزنید.
البته نباید انتظار یه ترمینال صددرصدی مشابه ترمینال پایچارم رو ازش داشته باشید ولی فکر کنم کار راه انداز باشند.
محمد وحید کوه کن (خریدار محصول) –
سلام استاد سوالی داشتم من میخوام اطلاعات جدولی که در این url هست رو استخراج کنم اما به هیچ شکلی نتونستم نه با css selector نه xpath ممنون میشم مشکل رو بفرمایید:
https://codal.ir/Reports/Decision.aspx?LetterSerial=cmjQJt%2Bh5QxBpUMcT8rfPA%3D%3D&rt=0&let=6&ct=0&ft=-1&sheetId=1
مثلا اطلاعات تگ h1 صفحه به راحتی استخراج میشه اما برای جدول به هر طریقی چه تگ های والد چه فرزند و … امتحان کردم یک لیست خالی برمیگردونه
محمدحسین ماجدی نیا –
سلام به شما
برخی از سایت ها، همه یا قسمتی از ساختار وبسایت خودشون با استفاده از جاوا اسکریپت اجرا می کنن (از تگ های script مثلا استفاده می کنن) که وب اسکریپینگ اینجور صفحات دیگه به سادگی با استفاده صرف از css و xpath ممکن نیست و مثلا نیاز هست به اون تگ های اسکریپتی دسترسی پیدا کنید و بعد المان های مدنظرتون رو بیرون بکشید.
لینک زیر یک راه حل برای این موضوع ارائه داده که مشابه مشکل شماست. بعد از دسترسی به تگ اسکریپت، با استفاده از جیسون و ریجکس، به المان های موجود در رشته دسترسی پیدا میکنه. پیشنهاد میکنم مطالعه بفرمایید و خودتون با کمی تغییرات میتونید به نتیجه برسید. (مثلا بجای استفاده از بیوتیفول سوپ برای دسترسی به کد صفحه، میتونید توی شل اسکریپی و از response هم استفاده کنید)
https://stackoverflow.com/questions/66753132/scraping-table-from-a-website-result-as-empty
نفیسه زوارئیان (خریدار محصول) –
سلام. من میخام از scrapy در اسپایدر استفاده کنم (منظورم ای دی ای spyder در اناکوندا). برنامه های شما کلاس هست چطور باید تغییرش بدم تا بتونم استفاده کنم؟ متشکرم.
محمدحسین ماجدی نیا –
سلام به شما
لطفا مشکلتون رو دقیق تر مطرح بفرمایید
در نصب اسکریپی در spyder مشکل وجود داره؟ یا مثلا اجرای کدها با خطا مواجه میشه؟
مصطفی محمدی –
میخواستم بدونم امکان ذخیره اطلاعات در یک دیتابیس هم وجود داره؟
یعنی اگر ما یک سایت داشته باشیم که بخوایم اطلاعات سایت imdb رو در دیتابیس ذخیره کنیم (دریک بازه زمانی خاص) و در سایت خودمون (که با جنگو برنامه نویسی میشه) نمایش بدیم تا بتونیم بعدا هم در سایت خودمون اطلاعات رو ویرایش کنیم؟
محمدحسین ماجدی نیا –
سلام
این امکان به طور کلی وجود داره ولی فعلا در این آموزش به اون نمی پردازیم
در این آموزش، ما اطلاعات در یک فایل (مثلا با فرمت csv) ذخیره می کنیم.
حمید –
سلام. تشکر بابت مجموعه شما. چه طور میتونم با مدرس دوره ارتباط بگیرم برای کلاس خصوصی ؟
محمدحسین ماجدی نیا –
سلام به شما
از قسمت پروفایل کاربری و گزینه “ارتباط با مدرس” میتونید با بنده در ارتباط باشید
مصطفی آصفی –
بهترین آموزشی که می تونست تولید بشه. واقعا دست مریزاد..