Numba چیست؟
Numba چیست؟ Numba یک کامپایلر متنباز و درجا یا JIT برای کدهای پایتون است که توسعهدهندگان میتوانند از آن برای تسریع اجرای توابع عددی در CPUها و GPUها با استفاده از توابع استاندارد پایتون استفاده کنند. نامبا بایتکد پایتون را مستقیما قبل از اجرا به کد ماشین ترجمه میکند تا سرعت اجرا افزایش یابد.
از Numba میتوان برای بهینهسازی عملکردهای CPU و GPU با استفاده از آبجکتهای قابل فراخوانی پایتون به نام دکوراتور استفاده کرد. دکوراتور تابعی است که تابع دیگری را به عنوان ورودی میگیرد، آن را اصلاح میکند و تابع اصلاح شده را به کاربر باز میگرداند. این مدولار زمان برنامه نویسی را کاهش و توسعه پایتون را افزایش میدهد.
هم رویش منتشر کرده است:
آموزش سایتون -- افزایش سرعت اجرای پایتون با کتابخانه Cython
Numba میتواند با NumPy نیز کار کند. نامپای یک کتابخانه متنباز پایتون برای عملیات پیچیده ریاضی در پردازش دادههای آماری است. هنگامی که شما Numba را به صورت یک دکوریتور (decorator) به یک تکه کد Python و یا NumPy اضافه میشود، آن را به بایتکدی مناسب محیط اجرا ترجمه میکند.
نامبا از LLVM استفاده میکند که یک کتابخانه متنباز و API محور برای ایجاد کد بومی (Native) است. گاهی اوقات Numba فقط با یک فرمان چندین گزینه را برای موازیسازی سریع کد پایتون برای پیکربندیهای مختلف CPU و GPU ارائه میدهد. هنگامی که Numba همراه با NumPy استفاده میشود، کدی ویژه را برای انواع مختلف دادهها و طرحبندی آرایه ایجاد میکند تا عملکرد را بهینه کند.
چرا Numba ؟ __ Numba یا Cython ؟
پایتون یک زبان برنامهنویسی پویا با بهرهوری بالا است که به طور گسترده در علم داده استفاده میشود. به دلیل سینتکس تمیز و رسا، ساختار دادههای استاندارد، کتابخانه استاندارد جامع، اسناد عالی، اکوسیستم وسیع کتابخانهها و ابزارها، و جامعه بزرگ و باز، بسیار محبوب است. با این حال، شاید مهمترین ویژگی یک زبان پویا و تفسیرشده مانند پایتون بهرهوری بالای آن باشد.
اما بزرگترین نقطه قوت پایتون میتواند بزرگترین نقطه ضعف آن نیز باشد. انعطافپذیری و سینتکس بدون نوع (Type)، سطح بالا میتواند منجر به عملکرد ضعیف برای برنامههای پرمصرف داده و محاسباتی شود. زیرا اجرای کد بومی (Native) و کامپایل شده چندین برابر سریعتر از اجرای کد پویا و تفسیر شده است.
به همین دلیل، برنامهنویسان پایتون که نگران کارایی هستند، اغلب حلقههای برنامه خود را در C بازنویسی میکنند و توابع C کامپایل شده را از پایتون فراخوانی میکنند. تعدادی پروژه مانند Cython با هدف سهولت در بهینهسازی وجود دارد، اما اغلب نیاز به یادگیری سینتکس جدید دارند. Cython عملکرد را به میزان قابل توجهی بهبود میبخشد، اما ممکن است نیاز به اصلاح دستی در کد پایتون داشته باشد.
هم رویش منتشر کرده است:
آموزش NumPy --- دانشمند داده شوید!
Numba جایگزین بسیار سادهتری برای Cython است. یکی از جذابترین ویژگیهای آن این است که نیازی به یادگیری سینتکس جدید، جایگزینی مفسر پایتون، اجرای مرحله کامپایل جداگانه یا نصب کامپایلر C++/C ندارد. فقط استفاده از دکوراتور jit@ در Numba روی عملکرد پایتون کافی است. این کار کامپایل را در زمان اجرا فعال میکند.
توانایی Numba برای کامپایل کد پویا به این معنی است که نباید از انعطافپذیری پایتون دست بکشید. همچنین، الگوریتمهای عددی در برنامههای پایتون که توسط Numba گردآوری شدهاند میتوانند به سرعتِ برنامههای نوشته شده در زبانهای کامپایل شده C یا FORTRAN نزدیک شده و تا 100برابر سریعتر از همان روشهایی که توسط مفسر بومی (Native) پایتون اجرا شده است، اجرا شوند. این حالت یک گام بزرگ در جهت ارائه ترکیب ایدهآل برنامهنویسی با بهرهوری بالا و محاسبات با عملکرد بالا است.
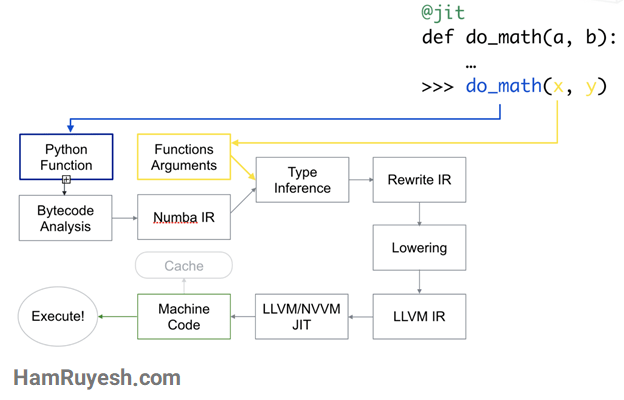
Numba برای کارهای محاسباتی آرایه محور طراحی شده است. موازیسازی دادهها در کارهای محاسباتی آرایهگرا برای شتاب دهندههایی مانند GPU مناسب است. Numba انواع آرایه NumPy را درک می کند و از آنها برای تولید کد کامپایل شده کارآمد، برای اجرا در GPUها یا CPUهای چندهستهای استفاده میکند.
برنامهنویس میتواند به سادگی یک دکوراتور تابع vectorize@ را اضافه کند که به Numba دستور میدهد نسخه کامپایلشده و بردار تابع را در زمان اجرا ایجاد کند، سپس این امکان را میدهد تا آرایههای داده را به طور موازی در GPU پردازش کنید.
علاوه بر JIT کد آرایه NumPy برای CPU یا GPU ،Numba کودا پایتون (CUDA Python) را معرفی میکند:
یک مدل برنامهنویسی NVIDIA CUDA برای پردازندههای گرافیکی انویدیا در سینتکس پایتون است. با افزایش سرعت پایتون، توانایی آن از یک زبان چسبنده به یک محیط برنامهنویسی کامل گسترش مییابد که میتواند کد عددی را به طور کارآمد اجرا کند.
ترکیب Numba با ابزارهای دیگر در اکوسیستم علم داده پایتون ، تجربه محاسباتی GPU را متحول میکند. Jupyter Notebook یک محیط ایجاد سند مبتنی بر مرورگر را فراهم میکند که امکان ترکیب متن نشانهگذاری شده، کد اجرایی و خروجی نمودارها بصورت گرافیکی و تصاویر را فراهم میکند. Jupyter برای آموزش، مستندسازی تحلیلهای علمی و نمونهسازی اولیه تعاملی بسیار محبوب است.
پیکربندی Numba روی بیش از 200 پلتفرم مختلف آزمایش شده است. Numba بر روی سیستمعاملهای ویندوز، اپل مکینتاش و لینوکس روی پردازندههای Intel و AMD x86 ، POWER8/9 و ARM و همچنین GPUهای انویدیا و AMD اجرا میشود. همچنین فایلهای باینری پیشکامپایل شده برای اکثر سیستمها در دسترس هستند.
موارد استفاده از Numba
محاسبات علمی
پردازش آرایهها در سیستم اطلاعات جغرافیایی گرفته تا محاسبه اشکال پیچیده هندسی کاربردهای زیادی دارد. آرایهها توسط شرکتهای مخابراتی برای بهینهسازی طراحی شبکههای بیسیم و محققان مراقبتهای بهداشتی برای تجزیه و تحلیل شکل موجهایی که اطلاعاتی در مورد اندامهای داخلی دارند استفاده میشود. از آرایهها میتوان برای کاهش نویز خارجی در پردازش زبان، تصویربرداری نجومی و رادار/سونار استفاده کرد.
زبانهایی مانند پایتون برنامههای کاربردی در این زمینهها را بدون آموزش گسترده ریاضی در اختیار توسعهدهندگان قرار داده است. با این حال، کاستیهای عملکرد پایتون در محاسبات فشرده عددی میتواند بر سرعت پردازش در برخی از کاربردها به شدت تأثیر بگذارد. Numba یکی از چندین راه حل است و توسط بسیاری به عنوان یک روش سادهتر برای استفاده درنظر گرفته شده است. این امر برای توسعهدهندگان بدون تجربه در زبانهای پیچیدهتر مانند C بسیار ارزشمند است.
چرا Numba برای دانشمندان داده اهمیت دارد؟
توسعه تکراری یک ابزار مفید صرفهجویی زمان، در علم داده است. زیرا توسعهدهندگان را قادر میسازد تا برنامهها را بر اساس مشاهده نتایج به طور مداوم بهبود بخشند. زبانهای مفسری مانند پایتون در این زمینه بسیار مفید هستند. با این حال، محدودیتهای عملکرد پایتون در عملیات بالای ریاضی میتواند تنگناهایی ایجاد کند که سرعت کلی پردازش را کند کرده و بهرهوری توسعهدهندگان را محدود میکند.
فراخوانی یک تابع کامپایلر که میتواند عملکرد را در محاسبات و آرایههای بزرگ بهصورت چشمگیری بهبود بخشد، راهحلی است که Numba برای حل این مشکل درنظر گرفته است. یادگیری Numba آسان است و دانشمندان داده را از انجام کارهای پیچیده مانند نوشتن زیر روالها در زبانهای کامپایلری برای بهینهسازی سرعت، نجات میدهد.
چرا Numba در GPUها بهتر است
از نظر معماری، CPU فقط از چند هسته با حافظه پنهان زیاد تشکیل شده که میتواند همزمان چند نخ (thread) نرمافزار را اداره کند. در مقابل، GPU از صدها هسته تشکیل شده که میتوانند هزاران نخ (thread) را به طور همزمان اداره کنند.

Numba از برنامهنویسی GPU CUDA با کامپایل مستقیم زیرمجموعه محدود کد پایتون به هسته CUDA و عملکردهای دستگاه پس از مدل اجرای CUDA، پشتیبانی میکند. هستههای نوشته شده در Numba دسترسی مستقیم به آرایههای NumPy دارند که به طور خودکار بین CPU و GPU منتقل میشوند. این امر به توسعهدهندگان پایتون امکان ورود آسان به محاسبات با سرعت GPU و راهی برای یادگیری نحوه اعمال کد پیچیده CUDA بدون فراگیری سينتکس یا زبانهای جدید را میدهد.
با CUDA Python و Numba، بهترینها را از هر دو جهان بدست میآورید:
توسعه سریع تکراری با Python همراه با سرعت یک زبان کامپایلشده که CPUها و GPUهای انویدیا را هدف قرار میدهد.
یک آزمایش با استفاده از سرور با پردازنده گرافیکی NVIDIA P100 و پردازنده Intel Xeon E5-2698 v3 نشان داد که کد CUDA Python Mandelbrot که در Numba کامپایل شده است. 1700 بار سریعتر از نسخه خالص پایتون اجرا میشود. بهبود عملکرد نتیجه چندین عامل، از جمله کامپایل، موازیسازی و شتاب GPU در مقایسه با کد پایتون تکنخی در CPU بود. با این حال، این عملکرد نشان میدهد که شتاب را میتوان با افزودن تنها یک واحد GPU به دست آورد.
شتاب دهنده GPU انویدیا، علم داده سربهسر
مجموعه کتابخانههای نرمافزاری متنباز NVIDIA RAPIDS که بر اساس CUDA-X AI ساخته شده است، توانایی اجرای سربهسر خط لوله (Pipline) و تجزیه و تحلیل را به طور کامل بر روی پردازندههای گرافیکی فراهم میکند. این دستگاه برای بهینهسازی محاسبات سطح پایین به NVIDIA CUDA متکی است، اما موازیکاری GPU و سرعت بالای پهنای باند حافظه را از طریق رابطهای پایتون نشان میدهد.
با ديتافريم RAPIDS GPU، دادهها را میتوان با استفاده از رابط کاربری شبیه Pandas در GPUها بارگذاری کرد. سپس برای یادگیری ماشین و الگوریتمهای تجزیه و تحلیل نمودار، بدون خروج از GPU استفاده کرد. این سطح از قابلیت همکاری از طریق کتابخانههایی مانند Apache Arrow امکانپذیر است و اجازه میدهد تا برای خطوط لوله (Piplines) سربهسر از آمادهسازی دادهها تا یادگیری ماشین تا یادگیری عمیق، شتاب ایجاد شود.
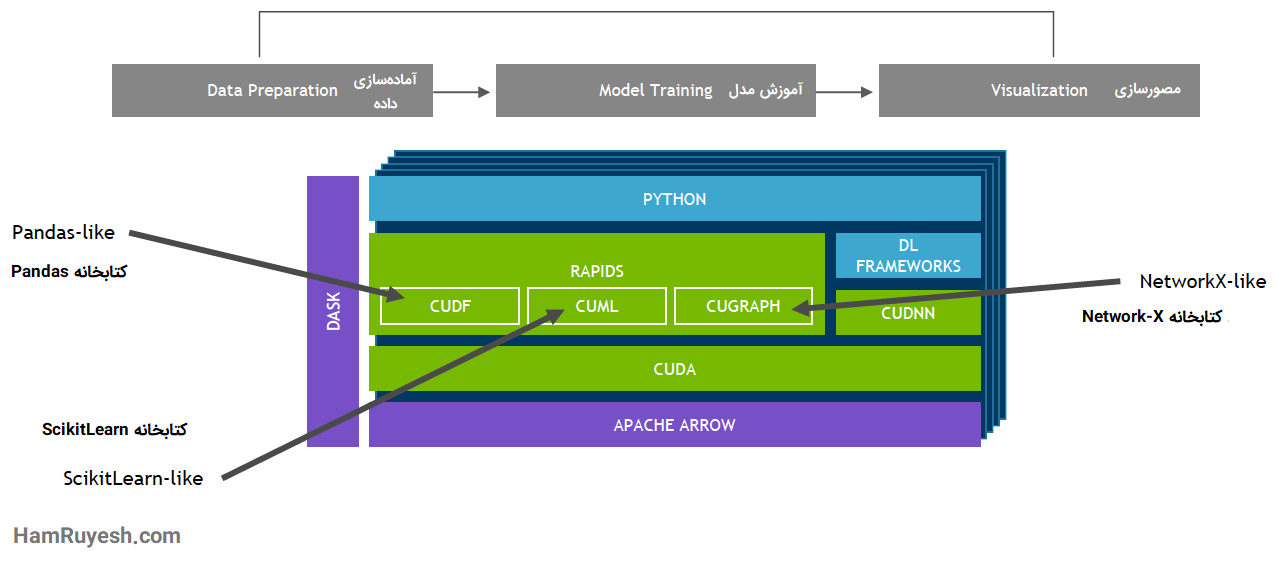
RAPIDS از اشتراکگذاری حافظه دستگاه بین بسیاری از کتابخانههای محبوب علم داده پشتیبانی میکند. دادهها را بر روی GPU نگه میدارد و از کپی پرهزینه در حافظه میزبان جلوگیری میکند.
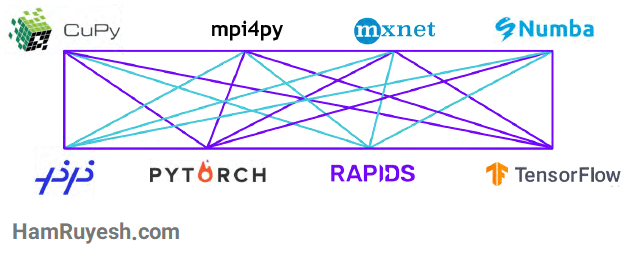
تیم RAPIDS در حال توسعه، مشارکت و همکاری نزدیک با پروژههای متعدد متنباز از جمله Apache Arrow ، Numba ، XGBoost ، Apache Spark ، scikit-learn و بقیه است تا اطمینان حاصل شود که همه اجزای اکوسیستم علم داده با سرعت GPU با یکدیگر بدون مشکل کار میکنند.
در آخر اگر خودتان و یا اطرافیانتان به دنبال یک آموزش پایتون از مقدماتی تا پیشرفته هستید پیشنهاد میکنم فیلم معرفی دوره پایتون را در ادامه ببینید:
برای دریافت کامل بسته آموزش پایتون (+) کلیک کنید.
کلیدواژگان
Numba – نامبا – نامبا چیست – دانشمندان داده – دانشمند داده – دانشمند داده چیست – دانشمندان داده چیست – دانشمند داده ها – دانشمند علم داده – data science چیست – افزایش سرعت پایتون – افزایش سرعت پایتون با numba – سرعت پایتون – Numba در GPU – numba در جی پی یو – نامبا در چی پی یو – gpu – Numba چیست – تفاوت بین cpu و gpu – معنی GPU – مقایسه GPU – مقایسه CPU و GPU – نامبا یا سایتون








