پایگاه دادههایی با 200 میلیون رکود را با Vaex پردازش کنید.
با کتابخانه Vaex و دیتافریمهایی که وکس میسازد، میتوانید کلان دادهها را پردازش کنید. میتوانید تحلیل کلان داده ها با پایتون را تا حد زیادی شبیه پانداس تجربه کنید اما با سرعت بیشتر!

Pandas چیست ؟
Pandas یکی از محبوبترین کتابخانههای مورد استفاده، برای مطالعات موردی علم داده است.که یکی از بهترین ابزارها برای تحلیل دادههای اکتشافی و آمادهسازی دادهها است. Pandas به خوبی با مجموعه دادههای کوچک یا متوسط که به بهترین شکل در حافظه جای میگیرند، کار میکند این کتابخانه برای پردازش دادهای بر روی مجموعه دادههای بزرگ، ناکارآمد است. در استفاده از دیتافریمهای Pandas برای تحلیل دادههای اکتشافی روی کلان دادهها زمان زیادی صرف میشود.
در اینجاست که Vaex وارد عملیات نجات میشود که یک API مشابه با Pandas دارد و برای انجام پردازش دادهای بر روی مجموعه دادههایی که برزگتر از حافظه سیستم هستند بسیار کارآمد است.
هم رویش منتشر کرده است:
آموزش پانداس PANDAS پروژه محور __ تحلیل داده با پایتون (پروژه سفر به ماه)
Vaex چیست ؟
Vaex یک کتابخانه پایتون برای بیگ دیتا با کارایی بالا برای جایگزینی pandas است که از سیستم عبارت (expression system) و نگاشت حافظه (memory mapping) استفاده میکند. بر این اساس، توسعه دهندگان قادر خواهند بود که پردازشهای کلان داده را با کامپیوترهای معمولی نیز انجام دهند. Vaex برخی از APIهای Pandas را پوشش میدهد و بیشتر بر اکتشاف و تجسم دادهها متمرکز است.
Vaex به طور کامل با Pandas API سازگار نیست، اما بسیاری از قابلیتهای آمادهسازی و اکتشاف داده با Vaex نیز در دسترس است. تصویرسازی ویژگیهای مجموعه داده با استفاده از هیستوگرامها، نمودارهای تراکم و رندرینگ سهبعدی حجم انجام میشود.
Vaex چقدر کارآمد است ؟
Vaex در مقایسه با Pandas برای پردازش مجموعه دادههای بزرگ بسیار کارآمد است. در ادامه معیارهای آزمایشهای مربوط به آمادهسازی دادههای بزرگ با استفاده از Vaex را مشاهده خواهیم کرد. برخی از ویژگیهای مثبت Vaex به لحاظ کارایی (سرعت عمل) عبارتند از:
- قادر به خواندن سریع حدود 1.2 ترابایت داده است.
- به راحتی میتواند پردازش دادهای را بر روی بیش از ۱ میلیارد رکورد داده، روی لپتاپ شما انجام دهد .
- قابلیت افزایش ۱۰ تا ۱۰۰۰ برابری سرعت پردازش رشتهای در مقایسه با Pandas دارد.
چگونه Vaex اینقدر کارآمد است ؟
Vaex میتواند مجموعه داده با اندازهی بسیار بزرگ (تقریبا 1.2 ترابایت) را بارگذاری کند و قابلیت انجام اکتشاف و تصویرسازی بر روی دستگاه شما را دارد. به جای بارگذاری کل دادهها در حافظه، Vaex فقط دادهها را به حافظه نگاشت کرده و یک سیستم عبارت ایجاد میکند.
از مستندات Vaex:
Vaex از نگاشت حافظه، سیاست کپی حافظه صفر (zero memory copy policy) و محاسبات کند (lazy computations) برای انجام بهترین عملکرد خود استفاده میکند در نتیجه حافظهای هدر نمیرود. در واقع هر زمان که شما تغییری در دیتافریم داده ایجاد میکنید، یک عبارت جدید به این سیستم اضافه میشود.
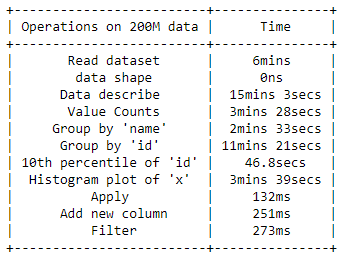
آزمایشها:

من یک مجموعه داده مصنوعی کلان (Big Data) با ۲۰۰ میلیون رکورد و ۴ ستون (”id”، “name”، “x”، “y”) با شاخص ” timestamp ” ایجاد کردم (یک نمونه فرضی برای تحلیل کلان داده با پایتون). اندازه کل مجموعه داده ۱۲ گیگابایت است.

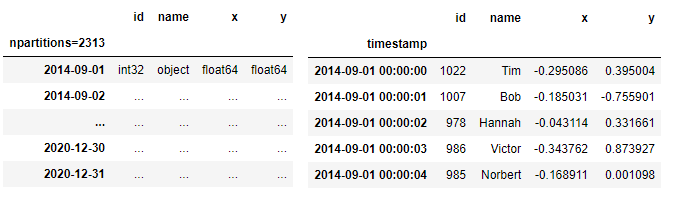
برخی از آزمایشهای اکتشاف دادهای برای ۲۰۰ میلیون رکورد داده، روی سیستم عامل ویندوز با ۸ گیگابایت رم انجام شدهاست.
- خواندن دادهها
- شکل داده
- توصیف دادهها
- شمارش مقادیر
- گروهبندی با ستون و تجمیع
- محاسبه صدک دهم
- تصویرسازی یک ستون
- اعمال یک تابع
- اضافه کردن یک ستون جدید
- فیلتر کردن دیتافریم
خواندن دادهها
این آزمایش به گونهای طراحی شدهاست که بهترین روشها را برای هر ابزار دنبال میکند (مهیا میکند) و از فرمت باینری HDF۵ برای Vaex استفاده میکند. باید فایل CSV را به فرمت HDF۵ تبدیل کرد تا Vaex بتواند بهترین عملکرد را داشته باشد. Vaex برای تبدیل ۲۳۱۳ قسمت از فایل CSV به قالب HDF۵ خود به ۳۳ دقیقه زمان نیاز دارد.
حالا نوبت به خواندن دادههای HDF۵ از دیسک میرسد:

Vaex برای خواندن کل مجموعه داده به ۶ دقیقه زمان نیاز دارد.
هم رویش منتشر کرده است:
آموزش تحلیل داده با جولیا از صفر ___ شروع سریع داده کاوی با زبان Julia
شکل داده:
برای محاسبه تعداد رکوردها در مجموعه داده با استفاده از Vaex نیازی به هیچ زمانی نیست.
(۰ نانو ثانیه). کل دادهها حدود ۲۰۰ میلیون رکورد است.
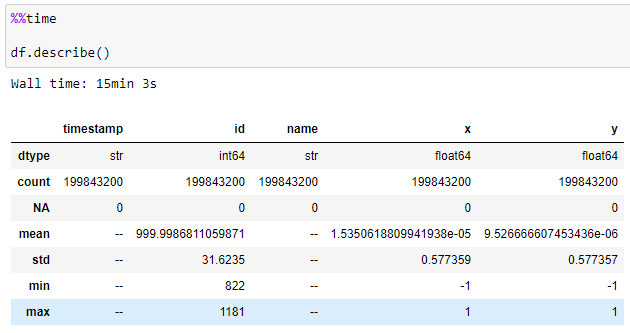
توصیف دادهها:
برای تولید آمار توصیفی شامل شاخصهای مرکزی، پراکندگی و شکل توزیع یک مجموعه داده، به استثنای مقادیر NaN از تابع .describe() استفاده میشود.
حدود ۱۵ دقیقه طول کشید تا Vaex آمار توصیفی هر ستون را محاسبه کند.
شمارش مقادیر:
برای محاسبه توزیع فراوانی ستون “name” در دیتافریم Vaex از تابع .value_counts() استفاده میشود.

حدود ۳.۵ دقیقه طول کشید تا Vaex توزیع فراوانی ستون “name” را حساب کند.
گروه بندی :
وکس هم مشابه pandas تابعی برای محاسبه گروهبندی و تجمیع ارائه میکند. دستور زیر، ستون “name” را گروهبندی میکند و میانگین ستون “x” برای هر گروه را محاسبه میکند.
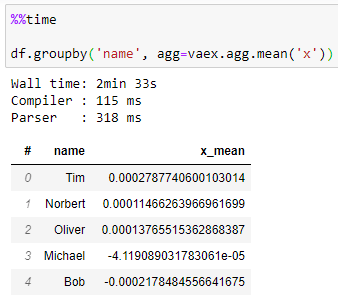
حدود ۲.۵ دقیقه طول کشید تا Vaex دستور گروهبندی وتجمیع فوق را محاسبه کند.
اگر برای محاسبه گروهبندی از ستون “id” و تجمیع میانگین از دو ستون “x” و “y” استفاده نماییم.
حدود ۱۱.۵ دقیقه طول کشید تا Vaex دستور گروهبندی وتجمیع فوق را محاسبه کند.
محاسبه صدک دهم:
Vaex دارای تابع percentile_approx برای محاسبه تقریبی یک صدک معین است.
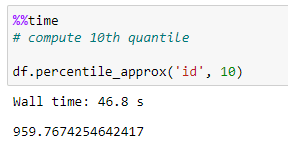
۴۶.۸ ثانیه طول کشید تا Vaex دهمین صدک ستون “id” را محاسبه کند.
ترسیم دادههای یک ستون:
ترسیم هیستوگرام (بافت نگار) کلان دادهها همواره مشکلساز است زیرا ابزارهای سنتی برای تجزیه و تحلیل این نوع دادهها بهینهسازی نشدهاند.
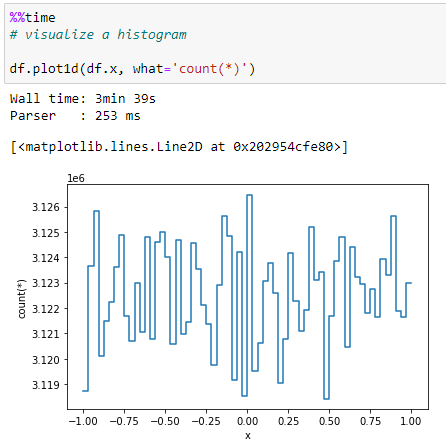
از تابع plot1d در Vaex برای ترسیم هیستوگرام بردارهای عددی استفاده میشود، ترسیم نمودار ۳.۵ دقیقه طول کشید.
اعمال یک تابع:
مشابه با pandas API، Vaex با استفاده از تابع apply عملکردی را روی دیتافریمها اعمال میکند. تابعی که لیستی از واکههای ستون ” name” را برمیگرداند:

استفاده از Vaex برای پردازش ۲۰۰ میلیون رکورد از ستون name، تقریبا زمانی طول نکشید.
(۱۳۲ میلی ثانیه)
اضافه کردن یک ستون جدید:
در واقع Vaex زمانی را برای اضافه کردن یک ستون به مجموعه داده صرف نمیکند، زیرا آن ستون جدید را بلافاصله اضافه نمیکند، بلکه فقط از یک سیستم بیانی (expression system) برای تولید عبارت برای ستون جدید استفاده میکند.

Vaex برای اضافه کردن یک ستون جدید، تقریبا ۲۵۱ میلی ثانیه زمان نیاز دارد.
فیلتر کردن دیتافریمها:
وکس همانند پانداس یک سیستم API مشابه برای گزینش داده دارد تا دادهها را براساس شرایط خاصی فیلتر کند. Vaex بلافاصله دیتافریمها را فیلتر نمیکند، بلکه یک عبارت تولید میکند.
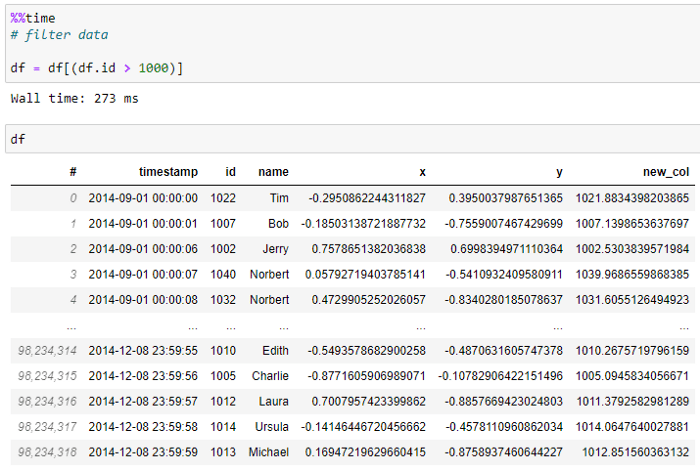
استفاده از Vaex برای اعمال فیلتر تقریبا زمانی طول نمیکشد (۲۷۳ میلی ثانیه)، و همانطور که از تصویر بالا مشاهده میشود، شکل قاب داده از ۲۰۰ میلیون به ۹۸ میلیون کاهش مییابد.
نتیجه گیری:
در این مقاله، ما ۲۰۰ میلیون رکورد از یک کلان داده فرضی سری زمانی با ۴ ستون در اندازه تقریبی ۱۲ گیگابایت تولید کردیم. استفاده از کتابخانه Pandas برای خواندن این مجموعه دادهها و انجام اکتشاف و تصویرسازی بر روی آن غیر ممکن بود.
به کمک کتابخانه Vaex و ایجاد دیتافریم وکس به راحتی میتوان دادهها خواند و اکتشاف و ترسیم نمودار و تصویرسازیهای مورد نیاز را انجام داد. تنها شرط دیتافریمهای Vaex، این است که با دادههای HDF5 به خوبی کار میکنند. بنابراین فایلهای CSV باید به فرمت HDF5 مورد نیاز تبدیل شوند.
همچنین، بیشتر Pandas APIها در کتابخانه Vaex دردسترس هستند بنابراین وکس برای پانداس کارها آشناست. این موضوع به همراه سرعت خوب، وکس را به مفیدترین کتابخانه برای کار با کلان داده (Big Data) تبدیل میکنند.
کلیدواژگان
کلان داده با پایتون – big data در پایتون – دیتافریم vaex – vaex چیست – وکس چیست – وکس چی هست – vaex pandas – کتابخانه vaex – pandas چیست – pandas چیست – پانداس چیست – پانداس چی هست – فرق vaxe با pandas – تفاوت vaex با pandas – مقایسه pandas با vaex – مزایای vaex – مزایا vaex – مزایا و معایب vaex – مزایا وکس – دیتافریم vaex – vaex dataframe – vaex sql – درآمد vaex – بیگ دیتا با پایتون – تحلیل کلان داده با پایتون – مقایسه vaex با pandas
منبع
Process Dataset with 200 Million Rows using Vaex
دوره های آموزشی مرتبط
-
 آموزش Matplotlib در ۱ ساعت ـــــ رسم نمودار با پایتون
۵۸,۰۰۰ تومان
آموزش Matplotlib در ۱ ساعت ـــــ رسم نمودار با پایتون
۵۸,۰۰۰ تومان -
 آموزش نامپای NumPy --- دانشمند داده شوید!
۹۲,۰۰۰ تومان
آموزش نامپای NumPy --- دانشمند داده شوید!
۹۲,۰۰۰ تومان












1 دیدگاه برای “Vaex چیست ؟ __ تحلیل کلان داده (Big Data) با پایتون و طعم پانداس ”
بسیار عالی. ممنون از متن روان و گویای شما.