
یک بار برای همیشه ساخت شبکه عصبی مصنوعی (Artificial Neural Network یا به اختصار ANN) را عمیق بیاموزید. خوشحالیم که امروز پس از گذشت ۹ ماه سرانجام این آموزش شبکه عصبی از صفر آماده هدیه به علاقهمندان شد. این آموزش علاوه بر تجربه مدرس، وامدار محبوبترین کتاب آموزش شبکه عصبی مصنوعی است. استفاده از این مرجع با اجازه رسمی از مؤلف آن صورت پذیرفته است (فیلم معرفی بسته را حتما ببینید).
علم و عمل
پس از دیدن این آموزش میتوانید با درکی درست و عمیق به ساخت شبکه های عصبی مصنوعی بپردازید. ما در همرویش این دوره را نیز تهیه کردهایم. برای دیدن آموزش ساخت شبکه عصبی با پایتون (قابل تعمیم به زبانهای دیگر) روی عکس زیر کلیک کنید:

هدیه ویژه
مدرس این دوره به تهیه کنندگان قبلی و بعدی این دوره یک نسخه از کتاب شبکه عصبی به زبان آدمیزاد (+) را هدیه کرده است. این کتاب در واقع چکیده روزآمدشده مطالب این دوره است که میتوانید برای یادآوری آن را دم دست داشته باشید.

فایل این کتاب به فایلهای دانلودی این دوره پیوست شد. همچنین شما میتوانید این کتاب را این این لینک در فیدیبو (+) جداگانه تهیه کنید. عایدات کتاب صرف امور خیریه و در اینستاگرام شخصی مدرس (+) اطلاع رسانی خواهد شد.
داستان این آموزش
پس از تألیف کتاب مهندسی انفجار با هوش مصنوعی متوجه شدیم اغلب کسانی که از این کتاب استفاده میکنند نگاه عمیقی به کاری که میکنند، ندارند. دانشجویان اغلب هنگام استفاده از کتابخانههای پایتون یا رابط کاربری متلب برای ساخت یک شبکه عصبی، از مقادیر پیشفرض بدون آگاهی لازم استفاده میکنند. دانشجویان متعددی تماس میگرفتند که در فلان زمینه فلان مدل را ساختیم ولی نتیجه خوب نیست. حالا کدام پارامتر را بالا و پایین کنیم تا خروجی بهتر شود؟! تصمیم گرفتم یک آموزش ساخت شبکه عصبی از صفر و عمیق تولید کنم. شما باید عمیقا بیاموزید که شبکههای عصبی مصنوعی چگونه رفتار میکنند! آموزشی به زبان ساده که اتفاقاً به جای پرش سریع به یک سورس کد یا کتابخانه و ایجاد یک شبکه به صورت ناآگاهانه، به بیان عمیق مفاهیم بپردازد.
یک سال پیش با کتاب Make Your Own Neural Network نوشته Tariq Rashid برخورد کردم. نویسنده این کتاب چقدر ساده مطالب پیچیده را باز میکند. آیا من باید چرخ را از نو اختراع میکردم؟ با ایشان تماس گرفتم. اجازه خواستم تا از سرفصل و محتوای کتاب خوبشان به عنوان مرجع اصلی در تولید یک مجموعه فیلمهای آموزشی در ایران استفاده کنم. ایشان با آغوش باز پذیرفتند.

شروع کردم. درس به درس مطالعه میکردم. مطالب لازم را اضافه میکردم. ضبط و سپس در شبکههای آپارات و اینستاگرام همرویش منتشر میکردم. در نیمه راه (شاید پس از انتشار درس ۱۱) متوجه شدم که روند انتشار تدریجی باعث آزار مخاطبان شده و مخاطبان مشتاق هستند که آموزش را یکباره بگذرانند تا بخشهای قبلی را فراموش نکنند. پس یک فرآیند مطالعه و ضبط فشرده در همرویش آغاز شد. و اکنون این آموزش به صورت یکجا از طریق سرورهای همرویش به شما تقدیم میشود.
هدف ما آموزش شبکه عصبی از صفر بود تا حتی مخاطبان نوجوان، با سوادی در حد دوره اول متوسطه هم بتوانند استفاده کنند. بنابراین مفاهیم ریاضی و محاسباتی گاه تا حد بسیار پایهای شکافته شدهاند. لطفاً اگر مشکلی در بیان مفاهیم نظری مشاهده کردید در بخش نظرات آموزش اطلاع دهید تا بررسی کنیم.
شبکه های عصبی مصنوعی، دستاورد تلاش یک قرن!
رامون کاخال (Ramón y Cajal) زیستشناس در ۱۸۹۹ تصویری از ساختار شبکه عصبی مغز کبوتر را منتشر کرد. یک تحول بنیادی! کاخال اعلام کرد که توانایی یادگیری موجود زنده به دلیل اتصالهای تازهای است که نورونها (سلولهای عصبی) با هم ایجاد میکنند.
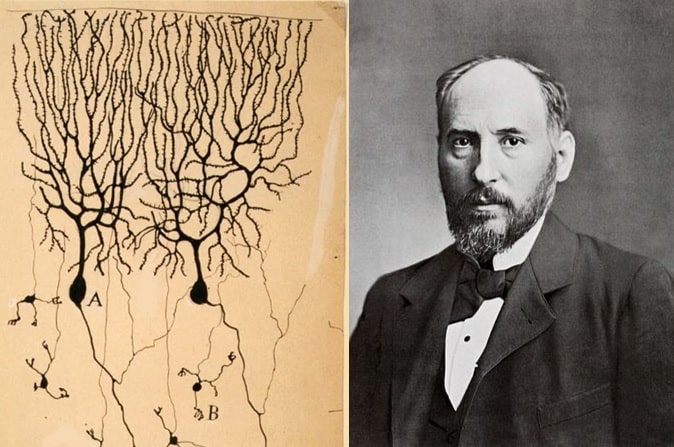
حدود نیم قرن بعد، فرانک روزنبلات (Frank Rosenblatt) روانشناس، یک مدل ریاضی ساده از عملکرد نورونها به نام پرسپترون (Perceptron) پیشنهاد کرد.

پس از کار روزنبلات، حدود سه دهه زمان برد تا یک شبکه عصبی مصنوعی چندلایه از اتصالات نورونی بتواند یادگیری را تجربه کند. الگوریتم پس-انتشار خطا که در این آموزش شبکه عصبی هم به صورت ژرف به آن پرداختیم این معجزه را محقق کرد.
البته فرآیند تولید علم معمولاً گسسته نیست. هر کس چوب را از دیگری میگیرد و پیش میبرد. در این حوزه هم محققان بسیاری نقش داشتند که در اینجا مجال معرفی آنها را نداریم. برای اطلاع بیشتر توصیه میکنیم مجموعه مقالات تاریخچه شبکه عصبی (+) را بخوانید.
امروز به لطف تلاش این محققان، ما شاهد شبکههای عصبی عمیق و متنوع هستیم. بینایی کامپیوتر را هم حتی با شبیهسازی اعصاب بینایی ممکن کردهایم. اکنون کامپیوترها حتی بهتر از انسانها میبینند و چهرهها را تشخیص میدهند. هوش مصنوعی و در قلب آن شبکههای عصبی مصنوعی به دست راست انسانها تبدیل میشوند.
به یاد داشته باشید که همه این پیشرفتها را کسانی به بار آوردند که موضوع را عمیق بررسی میکردند. شما نیز با درک شبکههای عصبی به صورت عمیق شاید از کاشفان نسلهای بعدی شبکههای عصبی مصنوعی باشید.
آموزش شبکه عصبی در یک نگاه
ما از صفر شروع کردیم و سعی کردیم مفاهیم پیچیده را آسان بیان کنیم. در درس ۱ فهمیدیم که کامپیوترها لزوما هوشمند نیستند.
درسهای ۲ تا ۵ آموختیم که اگر بنا باشد یک ماشین یادگیرنده داشته باشیم باید چه کنیم. ماشینی که بتوانید پیشبینی خطی انجام دهد. یا ماشینی که بتواند کلاسبندی دادهها بیاموزد.
از درس ۶ وارد بحث اصلی شدیم. نخست با هم دیدیم که نورونها و ساختار شبکه عصبی موجود زنده چه نقشی در یادگیری دارد. سپس یک مدل ریاضی از نورون ساختیم. این یعنی یک نورون مصنوعی!
در درسهای ۸ تا ۱۰ توانستیم نورونها را به هم وصل کنیم. شبکه ما اکنون میتوانست یک ورودی بگیرد و آن را به خروجی تبدیل کند. در اینجا نیاز به مبانی محاسبات ماتریسی داشتیم. به زبان ساده دیدیم که ماتریس چیست و چه نقشی در ساده شدن محاسبات شبکه عصبی دارد.
از درس ۱۱ تا ۱۴ به خطای شبکه پرداختیم. از الگوریتم پس انتشار خطا (Back-propagation) گفتیم. اینکه اگر خروجی شبکه ما نسبت به خروجی مورد انتظار دارای خطا باشد، چگونه این خطا باید در شبکه تسهیم شود. یعنی سهم هر نورون و هر اتصال از خطای ایجاد شده چقدر است؟
درسهای ۱۵ تا ۲۱ به راهکار اصلاح وزن در شبکه عصبی پرداختیم. پس از آنکه هر نورون سهم خود را از خطا گردن گرفت، حالا اتصالهای خود را باید با چه وزنی تصحیح کند که خروجی بهتر شود؟ در اینجا به مبانی حسابان و مشتق نیاز داشتیم. توضیح دادیم. سپس به شرح الگوریتم گرادیان کاهشی (Gradient Descent) پرداختیم. روشی که سه دهه شبکههای عصبی منتظر آن در زمستان هوش مصنوعی در حال فراموشی بودند.
سرانجام در درس ۲۲ حالا که ریاضیات شبکه را آموخته بودیم، به خودمان تلنگر زدیم که مغرور نشویم. ما به سادگی نمیتوانیم هر مسالهای و هر دادهای را به شبکه عصبی بدهیم و انتظار نتیجه خوب داشته باشیم. در این درس از اصول تعریف مساله و انتخاب متغیرها و مقدار دادهها و وزنها گفتیم.
شما در پایان این دوره شما آماده ساخت هوشمندانه شبکههای عصبی هستید. ما در بستهای جداگانه به ساخت یک شبکه عصبی با کدنویسی از صفر میپردازیم. همچنین شما ممکن است بخواهید از سورس کدهای آماده استفاده کنید. یا شاید بخواهید با یک کتابخانه پایتون یا رابط کاربری در متلب اقدام به ساخت شبکه کنید. مهم این است که شما آگاهانه و با درک عمیق شبکه عصبی خواهید ساخت!
آموزههای اصلی
- الگوریتم پیشخور یا Feed Forward را میآموزید.
- با الگوریتم پس انتشار خطا یا Backpropagation آشنا میشوید.
- الگوریتم گرادیان کاهشی یا Gradient Descent را عمیق میآموزید.
- مهمترین روشهای نرمالسازی دادهها را خواهید دید.
- نکتههای مهمی در انتخاب وزنهای آغازین شبکه میآموزید.
- تابع مجموع مربعات خطارا خواهید شناخت.
- با تابعهای سیگمویید logistic و tanh آشنا میشوید.
- مشتقگیری از تابع خطا با قاعده زنجیری را میآموزید.
- مفاهیم پایه مورد نیاز مانند مشتق و ماتریس هم شرح دادهایم.
چرا دیدن آموزش شبکه عصبی لازم است؟
- شبکههای عصبی مصنوعی (ANNs) امروز در هر جایی کاربرد دارند.
- شما برای ساخت مدلهای موفق یادگیری ماشین به درک عمیق ANN نیاز دارید.
- شما برای استفاده درست از کتابخانههای هوش مصنوعی به درک عمیق ANN نیاز دارید.
- شاید شما با درک عمیق ANN بتوانید سازنده یکی از نسلهای بعدی آن باشید!
آموزشهای رایگان مربوط به این دوره
مشتق چیست و چه کاربردی دارد؟ — مفهوم حسابان از صفر
گرادیان کاهشی چیست؟ — مفهوم و اجرا در توابع تک متغیره تا چند متغیره
پیشنیاز
ندارد
** پیش از این در همرویش فیلم شبکه عصبی کانولوشنی به زبان ساده منتشر شد. برای دیدن فیلم معرفی این آموزش بر روی این لینک (+) و یا پخش کننده پایین کلیک کنید:
برای دریافت بسته کامل این آموزش بر روی لینک زیر کلیک کنید:
شبکه عصبی کانولوشن به زبان ساده
+ حال نوبت آن رسیده است که آموزش کدنویسی کانولوشن (+) که فصل دوم از آموزش بینایی کامپیوتر با تنسورفلو (+) است را ببینید.
کلیدواژگان
فیلم آموزش شبکه عصبی از صفر | شبکه عصبی از صفر | شبکه عصبی به زبان ساده | شبکه عصبی مصنوعی | artificial neural networks | آموزش ساخت شبکه عصبی چندلایه | کتاب make your own neural networks | شبکه عصبی پیشخور | الگوریتم پس انتشار خطا | روش گرادیان کاهشی | مبانی نظری ANN | مفهوم نورون | ساختمان شبکه عصبی مصنوعی | نرمال سازی و استانداردسازی | طراحی و پردازش NN









افسانه اصغری (خریدار محصول) –
سلام با تشکر از تدریس عالی شما
بنده دانشجوی مقطع ارشد هستم و موضوع پایان نامه ام پیش بینی قیمت سهام هست .امکانش هست اسم دوره هایی که به من کمک میکنه را بفرمایید تا از مجموعه هم رویش خریداری کنم ؟
مصطفی آصفی –
سلام وقتتون بخیر.ممنونم از لطفتون. اگه با مفهوم شبکه های عصبی و پیاده سازی اون ها به خوبی آشنا شدین به نظرم نگاه سریعی به دوره تنسورفلو (+) و دوره پیش بینی بازار با LSTM (+) داشته باشین. البته هر دو دوره صرفا پرش سریع و بیان ایده هستن و عمیق شدن در تنسورفلو و بهینه یابی چنین شبکه هایی به پژوهش بیشتری نیاز داره. سرنخ ها رو ولی با این دو خواهین داشت.
همچنین این کتاب از جنسن (+) رو هم توصیه می کنم.
الهام نصرالهی –
سلام عالی هست استاد اگه براتون مقدور هست دوره رو رایگان برای بنده بفرستید مرسی
مصطفی آصفی –
سلام ممنونم. تو فیلم معرفی توضیح دادم که چطور نسخه رایگان رو دریافت کنید.
امیر –
عالیییییی
استاد خواهش میکنم همین روند رو پیش برید با اینکه هنوز وارد دانشگاه نشدم اما همه چیز رو خوب یاد گرفتم و عمیییییقققققق و در عین حال ساده
مصطفی آصفی –
سلام وقت بخیر. خوشحالم که آموزش براتون انگیزه بخش بوده و ممنونم که برای ارسال انرژی خوبتون وقت گذاشتین. شناسه AsefyCom رو در اینستاگرام دنبال کنید تا از کارهای بعدی بنده آگاه بشین.
امید قاسمی –
سلام خسته نباشید.
بسیار دوره ی عالی بود لذت بردم.
پروژه ی پایانی بنده در مورد یافتن بهترین مسیر برای حمل و نقل است که در آن ابتدا تمامی گره ها به خوشه های کوچکتر تقسیم میشوند سپس برای هر خوشه انبار تعیین میشود سپس مسیریابی برای هر خوشه با توجه به تقاضاهای گره های هر خوشه که ۴ دوره تقاضا میباشد انجام میشود که بهترین مسیر و کوتاه ترین مسیر با توجه به خودروهای ناهمگن برای ۴ دوره ی موجود باید بدست آید.این فرایند باید به صورت پردازش موازی باشد و همزمان ۴ دوره را اجرا کرده و تعیین کند برای هر ۴ دوره ی موجود در هر خوشه بهترین مسیر کدام خواهدبود
میخواهم جهت یافتن مسیرهای بهینه و کوتاه در هر خوشه از شبکه های عصبی عمیق استفاده نمایم.
آیا این الگوریتم توانایی حل آن را دارد؟؟؟یا از الگوریتم دیگری استفاده نمایم.
ممنون میشم راهنمایی کنید
the problem is:
a new mathematical model for stochastic heterogeneous request and heterogeneous capacity vehicle and p_median location store routing problem and it’s related solution based on clustering and deep neural network
مصطفی آصفی –
سلام آقای قاسمی عزیز. راستش من نتونستم مساله ای که گفتین رو درک کنم. اما با توجه به این که اشاره کردین قصد استفاده از شبکه های عمیق دارین باید بگم اصولا ما اینجا شبکه های عصبی پس انتشار ساده رو ساختیم و بحث شبکه های عمیق متفاوته. البته مبنای شبکه های عصبی همینه ولی نحوه ارتباط و وسعت و مدیریت لایه ها تو انواع الگوریتم های یادگیری عمیق متفاوته.
پینوشت: برای ساخت شبکه های عمیق توصیه نمی کنم که این کدی که اینجا داریم رو معیار بگیرین. راحت تر اینه که با تنسورفلو و کراس یا پای تورچ پیش برین. این کدی که اینجا نویشتیم یک کد پایه برای اجرا و لمس شبکه های عصبی هست.
سهیل سلطانی (خریدار محصول) –
واقعا لذت بردم خیلی آموزش عالی بود امیدوارم جناب آصفی بازم مجموعه های جدیدی رو منتشر کنن
مصطفی آصفی –
سلام و سپاس از این که برای ارسال انرژی و محبتتون وقت گذاشتین. دیدم شما فراگیر دوره ساخت شبکه عصبی با پایتون (+) هم هستین که امیدوارم از اونم استفاده کافی ببرید.
در مورد آموزش جدید این آموزش رایگان یادگیری ماشین (+) رو توصیه می کنم دنبال کنید. البته سرعت پیشرویش بالا نیست ولی مطالب مفیدی هست که سعی می کنم اونجا منتقل کنم.
یا می تونید نسخه رایگان اون رو تو لیست پخش یوتیوب (+) یا آپارات (+) تماشا کنید.
منصور احمدیان (خریدار محصول) –
با عرض سلام خدمت استاد ارجمندم جناب آصفی و هم رویشی های عزیز
بسیار خوشحالم که بعد از مدت ها با یک آموزش عمیق و در عین حال روان شبکه عصبی مصنوعی و مجموعه هم رویش آشنا شدم. انصافا دروه ی بسیار جالبی بود که از صفر مبانی اصلی شبکه عصبی رو آموزش میداد و در عین حال اون مطالب عمیقی که شاید سال ها باید در یک زمینه کار کنیم تا به اون بینش برسیم رو هم به این بسته آموزشی اضافه کرده بود که ارزش این آموزش رو صدها برابر بیشتر کرد. همچنین از مجموعه هم رویش ممنونم که این بسته رو با قیمت بسیار مناسب عرضه می کنند.
مصطفی آصفی –
سلام و سپاس که برای ارسال بازخوردتون وقت گذاشتین. خوشحالم که نتیجه کار براتون مفید بوده و سپاس از انرژی خوبتون که توشه مهمی برای ادامه این مسیره.
maryam (خریدار محصول) –
سلام وقت بخیر. آموزش خیلی عالی و با زبان ساده بود. واقعا ارزش مالی این آموزش خیلی بیشتر از اینهاست. امیدوارم جناب آصفی هر جا هستند موفق و سلامت باشن و انرژی مثبت کسانی که از این آموزش بهره مند شدن در زندگی و کارشون اثرگذار و جاری باشه.
مصطفی آصفی –
سلام و سپاس از این که وقت گذاشتین و انرژی خوب خودتون رو برای بنده فرستادین. خوشحالم که کار رو مفید دیدین.
علیرضا قایدیان –
سلام و ارادت.
جناب مهندس با عرض معذرت سوالی خدمتتون داشتم.
در دوره جایی اشاره میکنید که برای تفکیک داده آموزش از دیتای جامعه باید توزیع اماری شبیه به هم داشته باشند.
من چندین مقاله و مطلب دیگه هم خوندم اما کسی از این نکته حرفی نزده بود!
در نگاه کلی بنظر منطقی میاد این کار ولی اکثر مقاله هایی که خوندم من این تقسیم بندی داده هارو رندوم انجام داده اند.
آیا شما رفرنسی برای این نکته دارید؟؟
مصطفی آصفی –
سلام به شما. خیلی سوال خوبیه. ببینید راهکارهای متعددی در این زمینه هست. شما می تونید به این مقاله علمی (+) مراجعه کنید که در اون یکی از رویکردها رو حفظ توزیع در نظر گرفته.
پینوشت ۱: من احتمالا سال ها پیش در این مورد به نتیجه ای رسیدم و بعد از تجربه خودم و بدون اشاره به منبع این رو تو آموزش گفتم. به همین دلیل خاطرم نیست که منبع اصلیم در اون زمان چی بوده.
پی نوشت ۲: یه نکته ای هم تو ادبیات این موضوع دقت کنید. ببینید ما در واقع داده های جامعه رو نداریم. داده های نمونه ای (دیتاستی) از جامعه رو داریم که فرض می کنیم نماینده جامعه هست. حالا وقتی داده های پرت رو از این دیتاست حذف کردیم فرض می کنیم که این دیتاست توزیع آماریش نماینده توزیع آماری جامعه هست.
پی نوشت ۳: به طور کلی رویکردهای گوناگونی در تفکیک نمونه ها وجود داره که من همه به همه اون ها آشنایی ندارم. ممکنه رویکردی هم در جایی باشه که نیازی به حفظ توزیع درش نباشه و نتایج خاصی هم گرفته باشه. به نظر من منطقی نیست ولی ممکنه! تو حوزه روش های ابتکاری در کل همین موضوعه که کار رو سخت می کنه. ما یه ریاضیات قطعی و یه حکم قطعی نداریم.
پی نوشت ۴: تو دوره تندخوانی کتاب جرون، بخش آخر این فیلم به تفکیک داده های آزمایش (+) رو ببینید. اینجا از کتاب جرون دار نقل می کنم و نکته هایی که در تفکیک داده ها گفته شده بسیار مهم هستن. تفکیک نمونه ها به شیوه لایه لایه که تو همین فیلم اشاره کردم هم، نمودی از حفظ توزیع جامعه هست.
پی نوشت ۵: این گفتگو استک اکسچنج (+) هم نکته های خوبی در خودش داره. به خصوص پاسخ اول.
روح اله زارعی (خریدار محصول) –
ببخشید دوباره مزاحم شدم. یک روشی برای مقیاسبندی داده هایی که بازه بی نهایت دارن به ذهنم رسید نمی دونم ممکنه یانه؟ مثلاً لگاریتم بگیریم ازشون. البته خب جواب لگاریتم عددی که به سمت بی نهایت میره، خودش هم بی نهایت میشه البته با یک رشد بسیار کُند.
ببخشید اگه خنگ بازی در میارم و صبر نکردم تا جوابتون رو ببینم
مصطفی آصفی –
سلام دوباره. ببینید حتی اگه بدونیم محدوده تغییرات یک متغیر در یک جامعه می تونه بی نهایت باشه بازم نمونه هایی که می گیریم در عمل بی نهایت نیستن. یک تعداد ویژگی رو برای یک تعداد به هر حال محدود از داده ها برداشت می کنیم. اما سوال شما رو می تونم دو جور تفسیر کنم:
۱- فرض کنید نمونه هایی داریم که با افزایش یک ویژگی می بینیم که یک ویژگی دیگه مثلا انتها نداره (فرض کنید اون ویژگی قابل پیش بینی زمان باشه مثلا). در این صورت بازم شما تو اون محدوده که نمونه ها رو تهیه می کنید یک حد پایین و بالا دارینو پس مقیاس بندی به همون شیوه معمول هست و مدلی برای این محدوده در میارین. حالا این مدل قادر هست که این رفتار رو هر چقدر که ویژگی مستقل افزایش پیدا کنه تعمیم بده و ویژگی وابسته (اینجا زمان) رو تو خروجی، بزرگتر پیش بینی کنه.
۲- فرض کنیم تعداد داده های مرتب داره زیاد میشه و مرتب داده های جدیدی اضافه میشن. مثلا اگه مدلی که تعلیم میبینه یک شبکه عصبی مثل GPT پشت ChatGPT باشه هر ثانیه یا حجم جدیدی از داده های زبانی تولید شده در وب مواجه هست. اینجا مرتب داده های با محدوده جدید وارد میشن و مدل به طور کلی اصلاح میشه. دقت کنین که شبکه های عصبی پیش خور معمولا برای چنین مسائلی بهینه نیستن و می ریم سراغ یادگیری عمیق با شبکه های عصبی مثل پیجشی (CNN) با پارامترهای بسیار زیاد که بتونن این تغییر گسترده در داده ها رو مدل کنن.
پی نوشت۱ – در مورد روش نرمال سازی دسته ای یا Batch normalization (+) هم بخونید.
پی نوشت ۲- تبدیل لگاریتمی برای محدوده بی نهایت کمکی نمی کنه چون باز هم محدوده بی نهایت داره.
پی نوشت ۳- پرسشای عجیب که ممکنه خیلی ساده به نظر برسن نشونه خنگ بازی نیستن. سوال های ذهنی ریشه ای رو باید جدی گرفت.
روح اله زارعی (خریدار محصول) –
با سلام مجدد به آقای آصفی عزیز
ممنون از راهنمایی های خوبتون. من اون قسمت ها رو خوب دیدم و متوجه شدم برای مقیاس کردن باید مینیمم و ماکزیمم داده ها مشخص باشن و احتمالاً برای داده های بی نهایت مثل توالی اعداد، راهی دیگه رو باید پیش گرفت.
راستی این کامنت در اصل برای این گذاشتم که تشکر ویژه ای از شما داشته باشم و اون هم به خاطر جلسات آخر شبکه عصبی با پایتونه.
تو یکی از این جلسات ابزاری رو در یکی از کتابخونه های پایتون معرفی کردید که ماتریسی از اعداد رو مثلا بر مبنایRGB میگرفت و تصویر معادل اون ماتریس رو برمی گردوند.
مدتها بود دنبال نوشتن کدی در پایتون بودم که بتونم بخش خام دیتای یک فایل در فرمت مثلاً صوتی رو بگیرم و اون دیتا رو در ایجاد فایل تصویری در اندازه ای مشخص استفاده کنم.
حالا که این توابع رو دیدم فکر کنم کارم رو ساده تر کرده. البته اون داده های خام، کدهای هگزادسمیال هستن و باید این وسط یه تبدیل انجام بدم.
به هرحال خواستم تشکر ویژه ای ازتون داشته باشم.
انگار هیچ آشنا شدنی، اتفاقی نیست 🙂
مصطفی آصفی –
سلام مجدد. چه خوب. ممنونم که گفتین و ممنونم برای لطفتون. آره منم حس می کنم (البته صرفا یه حس ثابت نشده هست) که رخدادهای تصادفی این دنیا از قواعدی پیروی می کنن که شاید روزی با روش علمی آشکار بشن.
روح اله زارعی (خریدار محصول) –
به نام خدا
باز هم سلام خدمت شما آقای آصفی عزیز و تشکر از پاسخگویی و تشویقتون به پرسشگری
در مورد دو سوال قبلی مسئله خوب برام جا افتاد.
اما دوره آموزش شبکه عصبی رو که تا انتها دیدم، متوجه شدم باید داده ها رو نرمالیزه کرد.
در مورد مثال هایی شبیه تشخیص عدد، هم لرزومشو و هم امکانشو متوجه شدم.
اما اگر مسئله ای داشته باشیم که ورودی با سرعت یکنواختی رشد کنه. مثلاً رابطه تعداد کربن و حالا چند پارامتر دیگه، با مثلا دمای جوش ترکیبات شیمیایی
تو این مسئله تعداد اتم کربن از 1 تا 100 ها و هزاران ممکنه زیاد بشه. این رو چطور میشه نرمالیزه کرد؟ اصلاً تو این مسئله نرمالیزه کردن لازمه؟
در مورد خروجیش چطور؟ چون تابع سیگموئید بین 0 و یک هست
آیا باید فرض کنیم مثلاً تعداد ارقام عدد دمای جوش سه رقم بیشتر نیست و بعد اون مقادیر واقعی رو در 0.001 ضرب کنیم تا بازه خروجی بین صفر و یک بشه و سیگموئید بتونه تولیدشون کنه یا اینکه تابع رو باید عوض کرد و یک تابع بدون محدودیت براش در نظر گرفت؟
از اینکه با صبر و علاقه به سوالاتم جواب میدید خیلی ممنونم
مصطفی آصفی –
سلام و ممنون از انرژی خوبتون. ببینید شما میتونید به روش min-max scaling دادهها رو به مقیاس صفر تا ۱ ببرید. اگه کمترین مقدار دادهها رو با min و بیشترین مقدار رو با max نشون بدیم هر داده x رو میتونید با رابطه پایین مقیاس کنید که میشه عددی بین ۰ تا ۱:
X(scaled) = X – min / max – min
یه حلقه for بنویسید و تک تک دادهها رو با این رابطه مقیاس کنید یا از توابع آماده کتابخانههای پایتون مثل sci-kit learn استفاده کنید.
پینوشت ۱: توصیه می کنم درسهای پایانی دوره رو با دقت بیشتری تماشا کنید. اونجا از نظر ویژگی های تابع فعال سازی توضیح دادم که به چه دلایلی مقیاس کردن دادهها لازمه. متغیر هدف هم گفتم چرا باید مقیاس کنید.
پینوشت ۲: توصیه میکنم این آموزش رایگان یادگیری ماشین رو هم دنبال کنید. تو فصل دوم در مورد مقیاسسازی میگم.
روح اله زارعی (خریدار محصول) –
با سلام مجدد سوال دومم اینه که
اگه تک نورون من برای یک مسئله که حدس یه رابطه خطیه، فقط با ورودی و وزنی که مرتب اصلاح میشه (بدون تابع فعالسازی) بتونه درست عمل کنه، باز هم لازمه تابع فعال ساز هم تعریف کنم؟ تاکید می کنم که فقط یک تک نورون هست و نه شبکه ای از چند نورون.
(البته من این رو برای یک کار واقعی نمی خوام و چون می خوام شبکه عصبی رو از پایه و ساده ترین حالت ها برای خودم و بقیه توضیح بدم، این تک نورون رو با این شرایط ایجاد کردم.)
در واقع یک جورایی رگرسیون خطی یک متغیره میشه
آیا می تونم از چنین مثالی رو برای ابتدای راه یادگیری شبکه عصبی، استفاده کنم؟ یعنی انقلتی به یادگیرنده بودن این تک نورون وارده یا نه؟
باز هم خیلی خیلی ممونم از شما
مصطفی آصفی –
سلام مجدد. اگه درست متوجه شده باشم شما یک مساله رگرسیون خطی تک متغیره (univariate linear regression) دارید و قصد دارین با شبکه عصبی مدلسازی کنید برای اهداف آموزشی.
دقت کنید که نحوه یادگیری وزن در شبکه عصبی پرسپترون (گرادیان کاهشی) اصولا با نحوه یادگیری ضریب در مساله رگرسیون بیگانه نیست و ریشه های مشترک دارن. شما به هر حال تعدادی ورودی دارید و از مجموع رفتار اون ها (جذر مربع خطای اون ها تا ضریب یا وزنی که در لحظه در نظر می گیرین) قصد دارین به یک ضریب یا ورن (یا ضرایب یا وزنهای) بهینه برسین.
من توصیه می کنم این لینک (+) و معادله های اون برای پیدا کردن ضرایب رگرسیون خطی (آلفا و بتا) رو با اونچه در مورد گرادیان کاهشی گفتیم مقایسه کنید.
همین طور توصیه می کنم ایده شبکه عصبی تک نورونی پرسپترون (+) رو هم بخونید تا متوجه ایده وجود تابع فعال ساز بشین.
روح اله زارعی (خریدار محصول) –
با سلام خدمت آقای آصفی
و با تشکر از آموزش بسیار عالی تون
ببخشید من چنتا سوال دارم از خدمتتون
اما شاید تک تک بپرسم بهتر باشه و امیدوارم با سوالاتم شما رو خسته نکنم.
برای اولین سوال: شما در قسمتی که کلاسیفیکیشن رو توضیح می دادید (ویدیوی شماره 4) برای تصحیح خطای شبکه نهایتا به این رابطه رسیدید( مقدار هدف، منهای مقدار نتیجه شبکه، تقسیم بر ورودی شبکه؛ که جوابش رو با وزن اولیه جمع می کنید.
می خواستم بگم من از همین روش برای تصحیح خطای یک نورون که قراره یه مسئله تقریبا خطی (رابطه تعداد اتم های کربن با وزن موکلولی ترکیبات ساده کربنی) رو حل کنه استفاده می کنم و درست هم کار میکنه. سوالم اینه که چرا در دروس بعدی و ادامه آموزش، از روش گرادیان کاهشی برای تصحیح خطا استفاده کردید؟ آیا این روش نقص یا ضعفی داره؟ اگه داره این ضعف و نقصش چیه؟
با تشکر از صبر و حوصله شما
مصطفی آصفی –
سلام و سپاس از انرژی خوبتون. ببینید روشی که قسمت چهارم گفتم صرفا برای خلق ایده اولیه بود اما روش گرادیان کاهشی برای حل مساله در حالتهای مختلف طراحی شده. توصیه می کنم درس ۱۵ رو با دقت ببینید چون جوابم اینجا در واقع چکیده و بیان کوتاهی از همون درسه.
ببینید ما اگه یک نورون داشته باشیم که صرفا یک رابطه «خطی ساده» رو قراره درش مدلسازی کنیم اونوقت اون رابطه ساده شده هم جواب میده. البته باید تو تعریف خطا اونجا دقت کنید. قدرمطلق یا جذر مجموع مربعات رو باید در نظر بگیرید که مقدارهای منفی و مثبت هر دو به عنوان عدد مطلق خطا تو مقدار نهایی خطا تاثیر بگذارن (درس ۱۸). و اگه قدر مطلق یا رادیکال وارد اون رابطه بشه یه مقدار جبرش سخت تر میشه.
از طرف دیگه ما معمولا در یک شبکه چند نورون و چند لایه داریم. در این صورت همون طور که تو درس ۱۵ هم تصویری نشون دادم y یعنی خروجی محاسبه شده اگه قرار باشه وارد محاسبه جبری بشه باید تابعی از چندین و چند وزن نوشته بشه که این کار محاسبههای جبری رو سخت و سخت تر می کنه.
گرادیان کاهشی میاد که با چالش سخت شدن جبر قضیه یه دلیل نحوه محاسبه خطا (تابع خطا از جنس قدر مطلق یا رادیکال) یا به دلیل افزایش تعداد پارامترهای موثر در محاسبه y مبارزه کنه.
اینجا چون امکانات کمه من هر چی بیشتر توضیح بدم درکش سخت تر میشه. شما درس های ۱۵ به بعد دوره رو با دقت بیشتری ببینید بهتر متوجه میشین.
ramin (خریدار محصول) –
سلام وقت بخیر ما بعد تموم کردن این دوره و دوه شبکه عصبی با پایتون باید چکار کنیم تا بیشتر یاد بگیریم؟؟ فکر نکنم این دوتا دوره کفایت کنه
مصطفی آصفی –
سلام وقت بخیر. به مسیرتون بستگی داره. بستگی داره که قصد چه کاری دارین؟ چه حوزه ای؟ امروز مباحث خیلی تخصصی گسترش پیدا کردن و باید هدفتون رو اعلام کنید تا بشه بهتر نظر داد.
thmatrix2 (خریدار محصول) –
با سلام خدمت شما من از سایتهای مختلفی آموزش هوش مصنوعی و برنامه نویسی با پایتون رو تهیه کرده بودم ولی هیچ کدوم به قابل فهم بودن توضیحات شما نمی رسه بسیار از شیوه تدریس شما لذت بردم. امیدوارم همیشه موفق و پیروز باشید
مصطفی آصفی –
سلام و ممنون از لطف شما و سپاس که برای ارسال انرژی خوبتون وقت گذاشتین. خوشحالم که کارم مفید بوده.
مهدی (خریدار محصول) –
بسیار عالی و دقیق، هر کسی توانایی تدریس با این ریزبینی و دقت رو نداره، صمیمانه به شما تبریک میگم و بی صبرانه منتظر آموزشهای جدید شما هستم
مصطفی آصفی –
سلام و سپاس از این که وقت گذاشتین و برای ارسال انرژی مثبتتون! ادامه مباحث رو می تونید تو پیج AsefyCom (+) دنبال کنید.
محمد رشادی (خریدار محصول) –
با سلام و خسته نباشید اول تشکر میکنم بابت زحمتی که در تهیه این مجموعه کشیدید , بسیار عالی بود.
4 سوال برای من مطرح شده
سوال 1 : در بست مشتق ارور لایه آخر نسبت به وزن های وارد شده به لایه آخر (مشتق تابع ارور رو با ضریب 2- محاسبه کردید چرا منفی و 2 رو در لایه خروجی در نظر نگرفتید و همینطور عدد 2 رو در لایه مخفی)
سوال 2:در محاسبه دلتا Wjk که حاصلضرب آلفا در مشتق خطای لایه آخر نسبت به وزن های وارد شده به لایه آخر میباشد ( شما آلفا رو دیگه ضرب نکردید! یعنی نرخ یادگیری فقط در لایه های میانی ضرب میشود؟)
سوال 3:پس از باز کردن فرمول محاسبه دلتا Wjk شما برای تبدیل به ماتریس آمدید مشتق خطا به وزن ها را در خروجی لایه آخر ضرب کردید! (طبق سوال قبلی مگر نباید در نرخ یادگیری ضرب بشود؟ و اینکه چرا Oj=1 v رو انتخاب کردید؟)
مصطفی آصفی –
سلام سلامت باشید. ممنونم از انرژي خوبی که فرستادین. اگه ممکنه تو متن سوالاتتون اشاره کنید که تو کدوم درس و کدوم دقیقه هستن که بتونم دقیق تر به سوالتون جواب بدم.
فرزانه علیزاده (خریدار محصول) –
سلام . در فیلم شماره 13 من به عدد 0.42 برای e1 نمیرسم. 0.32*0.8 + 0.1*0.5 رو مگه محاسبه نمیکنید؟ و همین طور برای لایه بعدی هم با فرض درست بودن اعداد به جواب نمیرسم.
مصطفی آصفی –
سلام به شما. ببینید برای محاسبه اون ۰.۴۲ ما ۰.۱ رو به علاوه ۰.۳۲ کردیم. این ها خطاهایی هستند که از پس انتشار قبلی روی این دو یال محاسبه شدن.
یه نکته ریز وجود داره که باید خیلی دقت کنید. من وقتی داریم پس انتشار خطا از یک لایه به سمت عقب رو محاسبه می کنیم، نگاه می کنیم که چه اتصال هایی وارد اون نورون خطاکار شدن. اما وقتی داریم مجموع خطای نورون تو لایه قبلی رو حساب می کنیم اتصال هایی رو در نظر می گیریم که از اون نورون خارج شدن.
به بیان دیگه بگم (که البته اگه شما با تمرکز خوب فیلم ها رو گوش کنید خیلی بهتره از این توضیح بنده):
ما اول با پس انتشار خطا، خطای هر نورون تو لایه خروجی رو تقسیم می کنیم بین اتصال هایی که بهش وصل شدن. این طوری وقتی برای همه نورون های لایه خروجی این کار رو انجام بدیم همه اتصال های متصل به اون ها در لایه قبلی یه مقدار خطا می گیرن.
تو گام دوم قراره خطای هر نورون تو لایه مخفی رو محاسبه کنیم. این جا نگاه می کنیم که هر نورون سازنده کدوم اتصال هاست و خطای اون اتصال ها رو جمع می کنیم.
m.j.pazhand@gmail.com (خریدار محصول) –
بیان شما بسیار شیواست و محتوای سخت با این بیان راحت تر به ذهن میشینه
مصطفی آصفی –
سلام و سپاس از لطف شما. خوشحالم که براتون مفید بوده. این مفاهیم هر کدوم البته دنیایی دارن که به اقتضای هر مسالهای که برخوردین باید عمیق بشین.
cawsooar@gmail.com –
سلام وقتتون بخیر خیلی ممنون از مجموعه باکیفیت و بسیار مفیدتون
بنده پروژه ای رو با عنوان پیش بینی قیمت بازار فارکس با استفاده از یادگیری ماشین آغاز کرده ام و برای بخش یادگیری ماشین لطفا راهنمایی بفرمایید کدام از آموزش ها استفاده کنم(مسیر آموزش دوره ها)رو لطفا بفرمایید .باتشکر
مصطفی آصفی –
سلام و ممنون از لطف شما. خوشحالم که محصولات براتون مفید بوده. ببینید برای مساله پیش بینی (prediction) روش های زیادی وجود داره و از الگوریتم های زیادی میشه استفاده کرد. یکی از روشهای برای مثال استفاده از شبکه عصبی پس انتشار هست که با مسیر پایین میتونید پیش برید:
آموزش شبکه عصبی از صفر (+)
آموزش ساخت شبکه عصبی با پایتون (+)
آموزش تنسورفلو برای ایجاد شبکه های عصبی متنوع (+)
تو این حالت شما تعدادی متغیر به عنوان ورودی (اثرگذار روی قیمت) در نظر می گیرید و خود قیمت هم متغیر خروجی شبکه خواهد بود.
matin (خریدار محصول) –
سلام
لطفا کدهایی که آموزش دادین را در یک فایل بگذاریند که دانلود کنیم
مصطفی آصفی –
سلام به شما. تو این بسته کد نداشتیم. مبانی نظری آموزش داده شده. تو بسته بعدی که ساخت شبکه عصبی هست (+) سورس کد به طور کامل در اختیار فراگیر هست.
آرمان کریمی (خریدار محصول) –
سلام ، آموزش واقعا خیلی خیلی خوبی برای من بود ، من با شبکه های عصبی قبلا کار کرده بودم اما درک مفهومی از چگونگی عملکرد این شبکه ها نداشتم.
مصطفی آصفی –
سلام به شما. ممنونم که برای اظهار لطف خودتون وقت گذاشتین.خوشحالم که کارم مفید بوده.
مجید نوشادی –
سلام ممنون با این آموزش
مصطفی آصفی –
سلام و ممنون از لطف شما و این که برای ارسال انرژي مثبت وقت گذاشتین.
محمد مولوی (خریدار محصول) –
درود بر شما
در نرم افزار های دیگر مدل ساری با شبکه عصبی MLP چند پارامتر هست که در فیلم ها توضیح ندادید و لطفا تعریفی ازشان ارایه بدید .
Momentum Factor
iterations
Accuracy Rate
مصطفی آصفی –
سلام به شما. در مورد مفهوم iteration تو بسته ساخت شبکه عصبی – درس ۱۸ (+) ب توضیح بیشتری دادم. در مورد پارامتر Momentum در واقع ضریب اضافه ای هست که تو گرادیان کاهشی تصادفی برای تغییر تصادفی اصلاح وزن بر اساس مجموع گرادیان ها (به جای صرفا گرادیان کاهشی منفرد) استفاده میشه. تو این مقاله (+) رابطه اون توضیح داده شده.
در مورد نرخ دقت یه تعریف واحد وجود نداره. لطفا دقیق تر بفرمایید که تو چه نرم افزاری و با چه شرایطی هست که بتونم دقیق تر نظر بدم.
رضا –
درود بر شما آقای آصفی
در ابتدا تبریک میگم بابت ساخت چنین آموزش جامعی.
من خیلی ترغیب شدم این آموزش از صفر رو تهیه کنم و البته قبلا آموزش پانداس رو دیدم و کمی هم روی نام پای وقت گذاشتم و اینطور حس کردم که اگه یک متخصص رشته ی آمار و ریاضی، پایتون و کتابخونه های تحلیل داده رو یاد بگیره کارش خیلی راحت تر هستش تا اینکه یک برنامه نویس پایتون بخواد دانش آماری و ریاضیاتیش رو افزایش بده.البته منظورم در حد متوسط و پیشرفته هستش.
اگه این نظر من درست هستش
به نظرتون شبکه های عصبی یا هوش مصنوعی هم نیاز به دانش بالا در ریاضیات یا آمار داره؟
مصطفی آصفی –
سلام به شما. سلامت باشین. این آموزش به دانش سطح بالای ریاضی نیاز نداره اما این نظر در مورد کل دنیای هوش مصنوعی نیست. ابزارها متنوع هستن و هر کدوم دانشی نیاز دارن. به عنوان یه برنامه نویس و کسی که نیاز داره صرفا بعدها از شبکه های آماده هم استفاده کنه توصیه می کنم که با دیدن این آموزش یه دید عمیق نسبت به این موضوع پیدا کنید.
یدالله خانزاده (خریدار محصول) –
با سلام و احترام
لطفاً بفرمایید مبحث کدنویسی با چه زبانی و چه موقع آماده میشود
مصطفی آصفی –
سلام به شما. آموزش منتشر شد. لینک پایین رو ببینید:
آموزش ساخت شبکه عصبی با پایتون و پروژه محور (+)
Parmis (خریدار محصول) –
سلام استاد خسته نباشید امکانش هست لینک بسته جامع پیاده سازی شبکه مصنوعی رو اینجا قرار بدین
مصطفی آصفی –
سلام سلامت باشید نشانی پایین رو ببینید:
آموزش ساخت شبکه عصبی (+)
علیرضا فروزان (خریدار محصول) –
سلام استاد وقتتون بخیر
استاد فایل شماره 18 از آموزش شبکه عصبی لینکش برای من قابل دانلود نیست لطفا راهنمایی کنید
با تشکر
روابط عمومی هم رویش –
با سلام. همراه گرامی فایل مورد نظر چک شد و مشکلی یافت نشد. پیشنهاد می کنیم جهت دانلود از نرم افزار رایگان fdm استفاده نمایید که لینک دانلود در ذیل قرار می گیرد. همچین لینک دانلود درس 18 مجدد برای شما (به همین آدرس ایمیل که دیدگاه را ثبت کرده اید) ایمیل گردید.
https://www.freedownloadmanager.org/download.htm
علیرضا طهرانی –
سلام استاد تدریس عالی بود.سوال من اینه که چه زمانی مبحث کد زنی آماده میشود؟
مصطفی آصفی –
سلام سلامت باشین. بسته ساخت شبکه عصبی در نشانی پایین متتشر شده:
آموزش ساخت شبکه عصبی با پایتون (+)
پینوشت: پاسخ شما روزآمد شد.
فرزاد شاهبنده (خریدار محصول) –
سلام جناب مهندس آصفی عزیز
در انتهای درس 13 و ابتدای درس 14 در خصوص پس انتشار، چرا معکوس تابع سیگموید را در خطاها اعمال نکردید؟!!
مگر نه این بود که مقدارهای بدست آمده در شبکه، با اعمال تابع سیگموید بدست آمده اند. حالا که دارید اصلاح می کنید و خطاها را بدست می آورید باید عکس کاری که سیگموید روی هر مقدار اعمال کرده را نیز در مقدار خطا اعمال کنید و سپس پس انتشارش بدهید.
پیشاپیش ممنونم از پاسخ شما.
مصطفی آصفی –
سلام و سپاس از دقت نظر شما. دقت کنید که خروجی واقعی رو تابع سیگويید ایجاد نکرده. پیش بینی شبکه رو تابع سیگمویید رو ایجاد کرده. پس اختلاف خروجیها (خطا) رو نمیشه با فرآیند عکس تابع سیگمویید به یک ورودی منحرف شده معنی دار تعبیر کرد (خیلی سخته با متن منظور رو بشه رسوند ولی امیدوارم چند مرتبه جمله رو بخونید تا منظورم برسه)
حتی بیاید فرض کنیم که چنین کنیم و خطا (اختلاف خروجیها) رو با عکس سیگمویید به ورودی نورون برگردونیم. کمکی می کنه؟ در این صورت ما صرفا متوجه شدیم که چه مقدار از ورودی نورون باعث ایجاد خطا شده. بعد آیا درسته که این ورودی رو بین اتصالها تقسیم کنیم؟ یعنی بگیم هر کدوم از شما چه سهمی در ایجاد این ورودی داشتین. در حالی که ما دنبال سهم تقصیر اونها در خطای برآیندی هستیم. دنبال این هستیم که نهایتا بفهمیم خطایی که یک نورون در لایه پایانی داره چه وزنی از این خطا در اثر فلان اتصال بوده و چه وزنی از این خطا سهم اتصال دیگه.
امیدوارم توضیحم گویا بوده باشه. باز اگه منظور رو دست متوجه نشدم بفرمایید.
ابوالفضل حسن زاده –
سلام استاد خسته نباشید. استاد من فیلم معرفی دوره را تماشا کردم، توضیحات اون رو هم مطالعه کردم. اما به جواب سوالم نرسیدم. سوالم این هستش که اون بخش محاسبات و کار با ریاضیات در چه حد هست ؟ ایا افراد علاقه مند به اینجور موارد که سن کمی حدودا بین ۱۵ تا ۲۰ سال رو دارند در هر رشته ای که تحصیل کردند ، خواه دبیرستان باشه خواه هنرستان و خب سطح علمی این دو در ریاضیات خیلی با هم متفاوته همانطور که خودتون اطلاع دارید. از نظر درک مطلب ریاضیات در این بخش به مشکل نمیخوریم و این سطح از ریاضیات که در اموزش به کار رفته برای همه قابل درک است ؟
مصطفی آصفی –
سلام به شما جناب حسن زاده. سوال سختی پرسیدین. به طور کلی سعی کردم مفاهیم رو طوری بگم که آموزش نه تنها برای دانشجوها بلکه برای دانش آموزان از مقطع متوسطه دوم به بعد مناسب باشه. محاسبات ماتریسی و مفهوم مشتق که برای ساخت شبکه نیاز بوده هم از صفر توضیح داده شده. منتها نمی تونم ادعا کنم که حتما همه بچه ها راحت با آموزش ارتباط خواهند گرفت. باید بازخوردها رو بگیریم و حتما بر اساس اون ها درس ها رو روآمد و اصلاح می کنم. برای مثال خود شما اگه آموزش رو با تمرکز دیدین حتما مشکلات رو اینجا بگذارین. ممنونم.