چگونه ماشینها زبان انسان را پردازش و درک میکنند؟
هر آنچه ما بیان میکنیم (چه به صورت شفاهی و چه به صورت کتبی) اطلاعات زیادی را به همراه دارد. موضوعی که انتخاب میکنیم، لحن ما، انتخاب کلمات و همه چیز نوعی اطلاعات قابل تفسیر و ارزشمند است که از آن استخراج میشود. از نظر تئوری، ما میتوانیم رفتار انسان را با استفاده از این اطلاعات درک کرده و حتی پیش بینی کنیم. اما یک مشکل وجود دارد:
یک شخص ممکن است صدها یا هزاران کلمه را در یک بیانیه ایجاد کند، هر جمله با پیچیدگی متناظر خود. اگر میخواهید صدها، هزاران یا میلیونها نفر را در یک موقعیت جغرافیایی مشخص ارزیابی و تحلیل کنید، وضعیت غیرقابل مدیریت خواهد بود.
دادههای تولید شده از مکالمات، بیانیهها یا حتی توییتها نمونههایی از دادههای بدون ساختار هستند.
دادههای غیر ساختار
دادههای غیر ساختار به طور مرتب در ساختار ردیف و ستون پایگاههای داده رابطهای سنتی جای نمیگیرند. و اکثریت قریب به اتفاق نشاندهنده دادههای در دسترس در جهان واقعی هستند. دستکاری کردن آن دشوار است. با این وجود، به لطف پیشرفتها در رشتههایی مانند یادگیری ماشینی، یک انقلاب بزرگ در رابطه با این موضوع در جریان است. امروزه دیگر تلاش برای تفسیر یک متن یا گفتار براساس کلمات کلیدی آن (روش مکانیکی به سبك قدیمی) نیست. بلکه تلاش برای درک معنای پشت آن کلمات (روش شناختی) است. به این ترتیب، میتوان اشکال گفتاری مانند کنایه را تشخیص داد. یا حتی تجزیه و تحلیل احساسات را انجام داد. در ادامه به جواب سوال پردازش زبان طبیعی چیست می پردازیم.
پردازش زبان طبیعی چیست ؟
پردازش زبان طبیعی چیست ؟ یا nlp چیست ؟ پردازش زبان طبیعی یا NLP زمینهای از هوش مصنوعی است که به ماشینها توانایی خواندن، درک و استنتاج معنا از زبانهای انسانی را میدهد.
این یک رشتهای است که بر تعامل بین علم داده و زبان انسان تمرکز دارد و در بسیاری از صنایع مقیاس پذیر است. امروزه NLP به لطف پیشرفتهای بزرگ در دسترسی به دادهها و افزایش قدرت محاسباتی در حال شکوفایی است. که به متخصصان اجازه دستیابی به نتایج معنیدار در حوزههایی مانند بهداشت و درمان، رسانه، امور مالی و منابع انسانی را میدهد. پس آموختید که پردازش زبان طبیعی چیست ؟
موارد استفاده از NLP ( کاربرد پردازش زبان طبیعی )
به عبارت ساده، NLP کنترل خودکار زبان طبیعی انسان مانند گفتار یا متن را نشان میدهد. و اگر چه این مفهوم جذاب است، ارزش واقعی پشت این فناوری از موارد استفاده آن ناشی میشود.
NLP میتواند در انجام بسیاری از كارها به شما کمک کند. کاربرد پردازش زبان طبیعی بسیار است و به نظر میرسد که زمینههای کاربرد آن به صورت روزانه افزایش مییابند. بیایید به چند مثال از کاربرد پردازش زبان طبیعی اشاره کنیم :
پیش بینی بیماری ها
NLP براساس سوابق الکترونیکی سلامت و گفتار خود بیمار، تشخیص و پیش بینی بیماریها را امکان پذیر میکند. این قابلیت در شرایط سلامتی که از بیماریهای قلبی عروقی به افسردگی و حتی اسکیزوفرنی میرسد، مورد بررسی قرار گرفته است. به عنوان مثال، Amazon Comprehend Medical سرویسی است که از NLP برای استخراج شرایط بیماری، داروها و نتایج درمان از یادداشتهای بیمار، گزارشهای آزمایش بالینی و سایر پروندههای الکترونیکی سلامت استفاده میکند.
شناسایی و استخراج اطلاعات
سازمانها میتوانند با شناسایی و استخراج اطلاعات در منابعی مانند رسانههای اجتماعی، آنچه مشتریان در مورد یک سرویس یا محصول میگویند را تعیین کنند. این تجزیه و تحلیل احساسی میتواند اطلاعات زیادی در مورد انتخابهای مشتریان و محرکهای تصمیمگیری آنها فراهم کند.
دستیار شناختی
یک مخترع در IBM یک دستیار شناختی ایجاد کرد که مانند یک موتور جستجوی شخصی با یادگیری همه چیز در مورد شما کار میکند. و سپس یک نام، یک آهنگ، یا هر چیزی که شما نمیتوانید لحظهای که به آن نیاز دارید به خاطر بیاورید را به شما یادآوری میکند.
کمک به شرکت هایی مانند یاهو و گوگل
شرکتهایی مانند یاهو و گوگل، با تجزبه و تحلیل متن ایمیلهایی که از طریق سرورهای آنها جریان مییابند. و حتی قبل از اینکه هرزنامهها به صندوق ورودی شما وارد شوند، متوقف میکنند. ایمیلهای شما را با NLP فیلتر و طبقه بندی میکنند.
شناسایی اخبار جعلی
برای کمک به شناسایی اخبار جعلی، گروه NLP در MIT یک سیستم جدید برای تعیین اینکه آیا یک منبع دقیق است. یا از نظر سیاسی مغرضانه است، ایجاد کرد. تشخیص داد که آیا یک منبع خبری میتواند قابلاعتماد باشد یا خیر.
رابط های هوشمند صدا محور
الکسا آمازون (Amazon’s Alexa) و سیری اپل (Apple’s Siri ) نمونههایی از رابطهای هوشمند صدا محور هستند که از NLP برای پاسخ به پیامهای فوری استفاده میکنند. و هر کاری مانند پیدا کردن یک فروشگاه خاص انجام میدهند. به ما پیشبینی آب و هوا را میگویند. بهترین مسیر را به دفتر پیشنهاد میکنند یا چراغهای خانه را روشن میکنند.
تجار مالی
داشتن بینش در مورد آنچه اتفاق میافتد. و آنچه مردم در مورد آن صحبت میکنند میتواند برای تجار مالی بسیار ارزشمند باشد. NLP برای پیگیری اخبار، گزارشها، نظرات در مورد ادغام احتمالی بین شرکتها استفاده میشود. همه چیز را میتوان در یک الگوریتم معامله گنجانید تا سودهای کلانی کسب کند. یادتان باشد، شایعه را بخرید و اخبار را بفروشید.
شناسایی مهارت ها
NLP همچنین در هر دو مرحله جستجو و انتخاب جذب استعداد، شناسایی مهارتهای استخدامهای بالقوه و همچنین شناسایی چشمانداز پیش از اینکه آنها در بازار کار فعال شوند، مورد استفاده قرار میگیرد.
کارهای روزمره
با پشتیبانی از فناوری IBM Watson NLP، LegalMation بستری را برای خودکار کردن کارهای روزمره و کمک به تیمهای حقوقی در صرفه جویی در وقت، کاهش هزینهها و تغییر تمرکز استراتژیک ایجاد کرد.
دیگر کاربردهای پردازش زبان طبیعی
NLP به ویژه در صنعت مراقبتهای بهداشتی در حال شکوفایی است. این تکنولوژی در حال بهبود ارائه خدمات درمانی، تشخیص بیماری و کاهش هزینهها است. در حالیکه سازمانهای مراقبت بهداشتی در حال پذیرش فزاینده پروندههای الکترونیک سلامت هستند. این واقعیت که مستندات بالینی را میتوان بهبود بخشید به این معنی است که بیماران میتوانند از طریق مراقبتهای بهداشتی بهتر، بهتر درک و بهره مند شوند. هدف باید بهینهسازی تجربه آنها باشد. و چندین سازمان در حال حاضر بر روی این موضوع کار میکنند.
شرکتهایی مانند آزمایشگاههای Winterlight پیشرفتهای عظیمی در درمان بیماری آلزایمر با نظارت بر اختلال شناختی از طریق صحبت کردن انجام میدهند. و همچنین میتوانند از آزمایشها و مطالعات بالینی برای طیف گستردهای از اختلالات سیستم عصبی مرکزی حمایت کنند. پس از یك رویکرد مشابه، دانشگاه استنفورد، وایوبات (Woebot)، یک درمانگر چت بات را با هدف کمک به افراد مبتلا به اضطراب و اختلالات دیگر، توسعه داد.
اما بحثهای جدی در مورد این موضوع وجود دارد. چند سال پیش مایکروسافت نشان داد که با تجزیه و تحلیل نمونههای بزرگ پرس و جوی موتور جستجو، آنها میتوانند کاربران اینترنتی که از سرطان لوزالمعده رنج میبرند را حتی قبل از اینکه تشخیص بیماری را دریافت کنند، شناسایی کنند. کاربران چگونه به چنین تشخیصی واکنش نشان میدهند؟ و چه اتفاقی میافتاد اگر شما به عنوان یک مثبت کاذب مورد آزمایش قرار میگرفتید؟ (به این معنی که میتوان بیماری را حتی اگر نداشته باشید تشخیص داد). این موضوع، مربوط به Google Flu Trends است که در سال ۲۰۰۹ اعلام شد قادر به پیشبینی آنفولانزا است. اما بعدا به دلیل دقت پایین و ناتوانی در برآورده کردن نرخهای پیشبینیشده، ناپدید شد.
NLP ممکن است کلید یک حمایت بالینی موثر در آینده باشد. اما هنوز چالشهای زیادی برای مواجهه در کوتاهمدت وجود دارد. بنابرین دیدید که همانطور گفتم کاربرد پردازش زبان طبیعی بسیار است.
NLP پایه برای تحتتاثیر قرار دادن دوستان غیر NLP شما —- الگوریتم های پردازش زبان طبیعی
جدا از کاربرد بسیار پردازش زبان طبیعی اشکال هایی وجود دارد. اشکالات اصلی که ما این روزها با NLP مواجه میشویم مربوط به این واقعیت است که زبان بسیار پیچیده است. فرآیند درک و دستکاری زبان بسیار پیچیده است. و به همین دلیل استفاده از تکنیکهای مختلف برای رسیدگی به چالشهای مختلف قبل از اتصال همه چیز به یکدیگر رایج است. زبانهای برنامهنویسی مانند پایتون یا آر (R) به شدت برای انجام این تکنیکها استفاده میشوند. اما قبل از این که به کدنویسی (که موضوع یک مقاله متفاوت خواهد بود) وارد شویم درک مفاهیم آنها مهم است. بیایید برخی از پرکاربردترین الگوریتمهای NLP را در زمان تعریف واژگان اصطلاحات خلاصه و توضیح دهیم:
هم رویش منتشر کرده است:
آموزش پایتون Python (برنامه نویسی پایتون مقدماتی تا پیشرفته )
بسته کلمات (Bag of Words)
یک مدل رایج است که به شما این امکان را میدهد که تمام کلمات را در یک متن بشمارید. اساسا یک ماتریس رخداد برای جمله یا سند ایجاد میکند. بدون توجه به دستور زبان و ترتیب کلمه. سپس از این فرکانسها یا رخدادهای کلمه به عنوان ویژگی برای آموزش یک طبقهبندی کننده استفاده میشود.
برای یک مثال کوتاه، من اولین جمله آهنگ “Across the Universe” را از گروه بیتلز گرفتم:
Words are flowing out like endless rain into a paper cup.
کلمات چون بارانی بیپایان در یک فنجان کاغذی جاری میشوند.
They slither while they pass, they slip away across the universe
همچنان که میگذرند میلغزند و از دنیا میگذرند.
حال بیایید این کلمات را بشماریم:
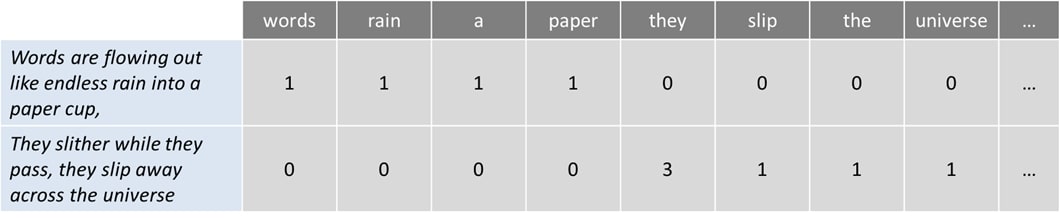
این رویکرد ممکن است جنبههای منفی متعددی مانند عدم وجود معنا و زمینه معنایی را منعکس کند. و حقایقی که کلمات را متوقف میکنند (مانند “the” یا” a ” ) به تجزیه و تحلیل نویز اضافه میکنند. و برخی کلمات بر این اساس وزن ندارند ( ” universe” کمتر از کلمه” they” وزن دارد).
برای حل این مشکل، یک رویکرد این است که فراوانی کلمات را با این که هر چند وقت یکبار در تمام متون ظاهر میشوند (نه فقط آن چیزی که ما تحلیل میکنیم) دوباره مقیاس بندی کنیم. به طوری که امتیازات کلمات مکرر مانند “the” که در سراسر متون دیگر نیز تکرار میشوند، جریمه شوند. این رویکرد برای امتیازدهی “Term Frequency — Inverse Document Frequency” (TFIDF) نامیده میشود. و بسته کلمات را با وزن بهبود میبخشد. از طریق TFIDF عبارات مکرر در متن “پاداش” میگیرند (مانند کلمه “they” در مثال ما). اما اگر این عبارات در متون دیگری که ما نیز در الگوریتم گنجاندهایم، تکرار شوند “مجازات” میشوند.
در مقابل، این روش عبارات منحصر به فرد و یا نادر را با در نظر گرفتن تمام متون، برجسته و “پاداش”می دهد. با این وجود، این رویکرد هنوز هیچ زمینه و معنایی ندارد.
هم رویش منتشر کرده است:
آموزش تحقیق کلمه کلیدی در 1 ساعت --- Keyword Research
توکن سازی (Tokenization)
این فرآیند تقسیمبندی متن به جملات و کلمات است. در اصل، این كار برش یک متن به قطعاتی به نام توکن است. و در عین حال برخی کاراکترهای خاص، مانند نقطهگذاری را حذف میکند. با پیروی از مثال ما، نتیجه توكنسازی به صورت زیر خواهد بود:

خیلی ساده است، نه؟ خوب، اگر چه ممکن است در این مورد و همچنین در زبانهایی مانند انگلیسی کاملا ابتدایی به نظر برسد که کلمات را با یک فضای خالی جدا میكند (که زبانهای بخشبندی شده نامیده میشوند). همه زبانها یکسان رفتار نمیکنند، و اگر در مورد آن فکر کنید، فضاهای خالی به تنهایی کافی نیست. حتی برای انگلیسی که توکنسازیهای مناسب را انجام دهد. تقسیم براساس فضاهای خالی ممکن است چیزی را که باید به عنوان یک نشانه در نظر گرفته شود. مانند نامهای خاص (به عنوان مثالSan Franciscoیا New York) یا عبارات خارجی وام گرفته شده (به عنوان مثال، laissez faire) را درهم بشکند.
توکنیزه کردن نیز میتواند علائم نگارشی را حذف کند. و مسیر را برای تقسیمبندی مناسب کلمه کاهش دهد اما همچنین باعث ایجاد عوارض احتمالی میشود. در مورد نقطهای که کلمه اختصاری را همراهی میکند (به عنوان مثال dr.). نقطه پس از آن اختصار باید به عنوان بخشی از یک نشانه در نظر گرفته شود و حذف نشود.
فرآیند علامت گذاری میتواند به طور خاص زمانی که با حوزههای متن زیست پزشکی سر و کار داریم. که حاوی تعداد زیادی خط تیره، پرانتز و دیگر علائم نگارشی هستند، مشکلساز باشد.
برای جزئیات بیشتر در مورد علامت گذاری میتوانید توضیح خوبی در این مقاله پیدا کنید.
حذف کلمات توقف (Stop Word Removal)
شامل خلاص شدن از حروف تعریف، ضمایر و حروف اضافه مانند ” and”، ” the ” یا ” to” در زبان انگلیسی است. در این فرآیند برخی کلمات بسیار رایج که به نظر میرسد ارزش کمی یا هیچ ارزشی برای هدف NLP دارند فیلتر میشوند. و از متنی که باید پردازش شود حذف میشوند. از این رو واژههای گسترده و مکرری که در مورد متن مربوطه اطلاعاتی ندارند حذف میشوند.
کلمات توقف را میتوان با انجام جستجو در لیست از پیش تعریفشده کلمات کلیدی، آزاد کردن فضای پایگاهداده و بهبود زمان پردازش، به طور ایمن نادیده گرفت.
هیچ لیست جهانی از کلمات توقف وجود ندارد. اینها میتوانند از قبل انتخاب شوند یا از ابتدا ساخته شوند. یک رویکرد بالقوه این است که با استفاده از کلمات توقف از پیش تعریفشده شروع کنیم. و کلمات را بعدا به لیست اضافه کنیم. با این حال، به نظر میرسد که روند کلی در طول زمان گذشته، استفاده از لیستهای کلمات توقف استاندارد بزرگ به استفاده از لیستهای خالی بودهاست.
نکته این است که حذف کلمات میتواند اطلاعات مربوطه را پاک کند. و زمینه را در یک جمله مشخص اصلاح کند. به عنوان مثال، اگر ما یک تجزیه و تحلیل احساسی انجام دهیم، ممکن است الگوریتم خود را از مسیر خارج کنیم. اگر یک کلمه توقف مانند “not” را حذف کنیم. تحت این شرایط، شما ممکن است حداقل لیست کلمات توقف را انتخاب کنید. و بسته به هدف خاص خود، عبارات اضافی را اضافه کنید.
ریشه یابی (Stemming) —- stemming چیست ؟
stemming چیست ؟ به فرآیند برش انتها یا آغاز کلمات با هدف حذف وندها (افزودههای واژگانی به ریشه کلمه) اشاره دارد.
وندها که به ابتدای کلمه متصل میشوند پیشوندها نامیده میشوند (برای مثال، astro در کلمه ” astrobiology”). و وندهای متصل در انتهای کلمه پسوندها نامیده میشوند (برای مثال، ” ful” در کلمه ” helpful”) .
مشکل این است که وندها میتوانند اشکال جدیدی از یک کلمه را ایجاد یا گسترش دهند (وندهای صرفی نامیده میشوند). یا حتی خود کلمات جدیدی خلق کنند (وندهای اشتقاقی نامیده میشوند). در زبان انگلیسی، پیشوندها همیشه اشتقاقی هستند (وند یک کلمه جدید مانند پیشوند ” eco” در کلمه ” ecosystem” ایجاد میکند). اما پسوندها میتوانند اشتقاقی باشند (وند یک کلمه جدید مانند پسوند “ist” در کلمه ” guitarist” ایجاد میکند) یا صرفی (وند یک شکل جدید از کلمه مانند پسوند “er” در کلمه ” faster” ایجاد میکند).
چطور میتونیم تفاوت ایجاد کنیم و قسمت درست را برش دهیم؟

یک رویکرد ممکن این است که فهرستی از وندها و قوانین مشترک را در نظر بگیریم (زبانهای پایتون و آر (R) کتابخانههای مختلفی دارند که حاوی وندها و روشها هستند) . و براساس آنها عمل کنیم. اما البته این رویکرد محدودیتهایی را ایجاد میکند. از آنجا که آنها از رویکردهای الگوریتمی استفاده میکنند، نتیجه فرآیند ریشه یابی (stemming) ممکن است یک کلمه واقعی نباشد. و یا حتی معنای کلمه (و جمله) را تغییر دهد. برای جبران این اثر میتوانید آن روشهای از پیش تعریفشده را با اضافه کردن یا حذف وندها و قوانین ویرایش کنید. اما باید در نظر بگیرید که ممکن است عملکرد را در یک حوزه بهبود بخشید. در حالی که یک تخریب را در حوزه دیگر ایجاد کنید. همیشه به کل تصویر نگاه کنید و عملکرد مدل خود را آزمایش کنید.
بنابراین اگر ریشه یابی کردن محدودیتهای جدی دارد. چرا ما از آن استفاده میکنیم؟ اول از همه، میتوان از آن برای تصحیح خطاهای املای توکنها استفاده کرد. استفاده و اجرا آن بسیار سریع است (آنها عملیات ساده را بر روی یک رشته انجام میدهند). و اگر سرعت و عملکرد در مدل NLP مهم هستند، پس ریشه یابی قطعا راهی است كه باید طی شود. به یاد داشته باشید، ما از آن با هدف بهبود عملکرد خود استفاده میکنیم، نه به عنوان تمرین دستور زبان.
یافتن ریشه کلمه با Lemmatization —– Lemmatization چیست ؟
Lemmatization چیست ؟ هدف آن کاهش یک کلمه به شکل پایه آن و گروهبندی اشکال مختلف یک کلمه یکسان است. برای مثال افعال در زمان گذشته به حال تبدیل میشوند (برای مثال ” went” به ” go” تغییر میکند). و مترادفها یكپارچه میشوند (برای مثال ” best” به ” good” تغییر میکند)، بنابراین کلمات را با معنای مشابه با ریشه شان استاندارد میکنند.
اگرچه به نظر میرسد که ارتباط نزدیکی با فرآیند ریشه یابی دارد، اما lemmatization از رویکرد متفاوتی برای رسیدن به شکل ریشه کلمات استفاده میکند.
قیاس کلمات را به شکل دیکشنری خود (معروف به لما) حل میکند که برای آن نیاز به دیکشنری دقیق دارد که در آن الگوریتم میتواند به جستجو بپردازد و کلمات را به لما خود پیوند دهد.
برای مثال، کلمات “ running“، “ runs” و “ ran” همه شکلهای کلمه “ run” هستند، بنابراین ” run” لما تمام کلمات قبلی است.

Lemmatization همچنین زمینه کلمه را به منظور حل مسایل دیگر مانند ابهامزدایی در نظر میگیرد. که به این معنی است که میتواند بین کلمات یکسانی که معانی متفاوتی دارند بسته به زمینه خاص تمایز قائل شود. به کلماتی مثل “خفاش” (که میتواند با حیوان یا با چماق فلزی / چوبی به کار رفته در بیس بال مطابقت داشته باشد). یا “بانک” (مرتبط با موسسه مالی یا زمین در کنار یک آب) فکر کنید. با ارایه یک پارامتر بخشی از گفتار به یک کلمه (خواه اسم باشد، خواه فعل و غیره) میتوان نقشی را برای آن کلمه در جمله تعریف کرد و ابهامزدایی را حذف کرد.
همانطور که شما ممکن است در حال حاضر نشان دهید، lemmatization یک کار بسیار بیشتر از انجام یک فرآیند ریشه یابی ناشی از منابع است. در عین حال، از آنجا که به دانش بیشتری در مورد ساختار زبان نیاز دارد تا یک رویکرد ریشهیابی، به قدرت محاسباتی بیشتری نیاز دارد تا راهاندازی یا تطبیق یک الگوریتم ریشهیابی.
مدلسازی موضوعی (Topic Modeling)
به عنوان روشی برای کشف ساختارهای پنهان در مجموعهای از متون یا اسناد است. در اصل، متون را برای کشف موضوعات پنهان براساس محتوایشان، پردازش کلمات منحصر به فرد و تخصیص مقادیر براساس توزیع آنها، دستهبندی میکند. این تکنیک براساس این فرضیات است که هر سند شامل ترکیبی از موضوعات است. و هر موضوع شامل مجموعهای از کلمات است. که به این معنی است که اگر بتوانیم این موضوعات پنهان را پیدا کنیم میتوانیم معنای متون خود را بیابیم.
الگوریتم LDA
از دنیای تکنیکهای مدلسازی موضوع، احتمالا Latent Dirichlet Allocation (LDA) بیشترین کاربرد را دارند. این الگوریتم نسبتا جدید (کمتر از ۲۰ سال پیش اختراع شد). به عنوان یک روش یادگیری بدون نظارت کار میکند. که موضوعات مختلفی را کشف میکند که زمینه جمعآوری اسناد هستند. در روشهای یادگیری بدون نظارت مانند این، هیچ متغیر خروجی برای هدایت فرآیند یادگیری وجود ندارد. و دادهها توسط الگوریتمها برای یافتن الگوها بررسی میشوند. برای اینکه دقیقتر باشیم، LDA گروهی از کلمات مرتبط را به صورت زیر پیدا میکند:
۱. هر کلمه را به یک موضوع تصادفی تخصیص دهید. که در آن کاربر تعداد موضوعاتی را که میخواهد کشف کند را تعریف میکند. شما خود موضوعات را تعریف نمیکنید (شما فقط تعداد موضوعات را تعریف میکنید). و الگوریتم تمام اسناد را به موضوعات نگاشت خواهد کرد به طوری که کلمات در هر سند عمدتا توسط آن موضوعات خیالی جذب میشوند.
۲. الگوریتم به صورت تکراری از هر کلمه عبور میکند. و کلمه را به موضوعی اختصاص میدهد. که در آن احتمال تعلق کلمه به یک موضوع، و احتمال ایجاد سند توسط یک موضوع در نظر گرفته میشود. این احتمالات چندین بار تا همگرایی الگوریتم محاسبه میشوند.
برخلاف دیگر الگوریتمهای خوشهبندی مانند K – means که خوشهبندی سخت را اجرا میکنند (که در آن موضوعات مجزا هستند)، LDA هر سند را به ترکیبی از موضوعات اختصاص میدهد، که به این معنی است که هر سند میتواند توسط یک یا چند موضوع توصیف شود (برای مثال سند ۱ توسط ۷۰ % از موضوع A، ۲۰ % از موضوع B و ۱۰ % از موضوع C توصیف شود) و نتایج واقع گرایانه تری را منعکس میکند.
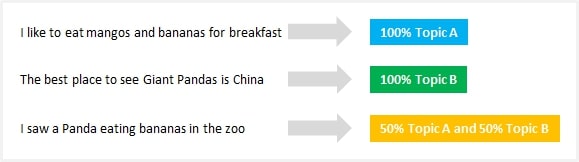
مدلسازی موضوعی برای طبقه بندی متون، ساخت سیستمهای توصیه گر (به عنوان مثال برای توصیه کتاب به شما بر اساس خوانشهای گذشته) یا حتی تشخیص روند انتشارات آنلاین بسیار مفید است.
آینده چه شکلی است؟
در این مقاله آموختید پردازش زبان طبیعی چیست ؟ و دانستید که کاربرد پردازش زبان طبیعی بسیار است که به تعدادی از کاربردهای پردازش زبان طبیعی اشاره شد. در حال حاضر NLP در حال تلاش برای تشخیص تفاوتهای جزئی در معنای زبان است. چه به دلیل فقدان زمینه، خطاهای هجی کردن و چه تفاوتهای گویشی.
در مارس ۲۰۱۶ مایکروسافت Tay را راهاندازی کرد. یک ربات هوش مصنوعی (AI) که در توئیتر به عنوان یک آزمایش NLP منتشر شد. ایده این بود که هر چه کاربران بیشتری با Tay صحبت کنند، آن هوشمندتر خواهد شد. خوب، نتیجه این بود که پس از ۱۶ ساعت Tay به خاطر نظرات نژادپرستانه و توهینآمیز اش کنار گذاشته شد:
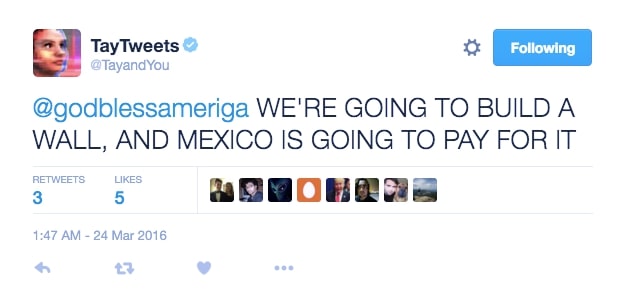

مایکروسافت از تجربه خود آموخت. و چند ماه بعد Zo، نسل دوم چت بات انگلیسی زبان خود را منتشر کرد. که مرتکب همان اشتباهات قبلی نمی شود. Zo برای شناسایی و تولید مکالمه از ترکیبی از رویکردهای نوآورانه استفاده میکند و شرکتهای دیگر در حال جستجو با رباتهایی هستند که میتوانند جزئیات خاص مکالمه فردی را به یاد بیاورند.
اگرچه آینده بسیار چالش برانگیز و پر از تهدید برای NLP به نظر میرسد، این رشته با سرعت زیادی در حال توسعه است (احتمالا هرگز قبلا اینگونه نبوده است) . و ما به احتمال زیاد در سالهای آینده به سطحی از پیشرفت خواهیم رسید که باعث میشود کاربردهای پیچیده ممکن به نظر برسند.
با تشکر از Jesús del Valle، Jannis Busch و Sabrina Steinert برای مطالب ارزشمند شما.
به این مباحث علاقه دارید؟ مرا در لینکدین یا توییتر دنبال کنید.
کلید واژگان
پردازش زبان طبیعی چیست ؟ – nlp چیست ؟ – ان ال پی چیست ؟ – کاربرد پردازش زبان طبیعی – پردازش زبان طبیعی با پایتون – پردازش زبان طبیعی فارسی – پردازش زبان طبیعی در پایتون – پردازش زبانهای طبیعی – پردازش زبان طبیعی و بازیابی اطلاعات – قانون nlp چیست ؟ – روش nlp چیست ؟ – تاریخچه و کاربرد ان ال پی – کاربردهای پردازش زبان طبیعی – پردازش زبان طبیعی چیست ؟ – کاربرد پردازش زبان طبیعی – الگوریتم های پردازش زبان طبیعی – پرکاربردترین الگوریتم های پردازش زبان طبیعی – Lemmatization چیست ؟ – یافتن ریشه کلمات – stemming چیست – stemmer چیست
منبع :
How machines process and understand human language