
هم رویش منتشر کرده است:
آموزش ساخت ChatGPT و DALL-E با پایتون و OpenAI API
از مدل ترنسفورمر تا مدل زبانی بزرگ
ما بهعنوان انسان، متن را بهعنوان مجموعهای از کلمات درک میکنیم. جملات دنبالهای از کلمات هستند. اسناد دنبالهای از فصلها، بخشها و پاراگرافها هستند. بااینحال، برای رایانهها، متن صرفاً دنبالهای از کاراکترها است. برای توانمندسازی ماشینها بهمنظور درک متن، میتوان مدلی مبتنی بر شبکههای عصبی بازگشتی ساخت. این مدل یک کلمه یا کاراکتر را در یکزمان پردازش میکند و یک خروجی را پس از اعمال کل متن ورودی ارائه میدهد. این مدلها خیلی خوب کار میکنند، با این تفاوت که گاهی اوقات وقتی به پایان کار میرسند، آنچه را که در ابتدای دنباله اتفاق افتاده فراموش میکنند.
در سال ۲۰۱۷، واسوانی (Vaswani) و همکارانش برای ایجاد مدل ترنسفورمر مقالهای با عنوان “توجه تنها چیزی است که نیاز دارید” منتشر کرد. مدلهای ترنسفورمر بر اساس مکانیسم توجه (Attention) کار میکنند. برخلاف شبکههای عصبی بازگشتی، مکانیسم توجه به شما امکان میدهد کل جمله یا حتی پاراگراف را بهجای یک کلمه در یکزمان مشاهده کنید. این روش به مدل ترنسفورمر اجازه میدهد تا محتوای یک کلمه را بهتر درک کند. بسیاری از پیشرفتهترین مدلهای پردازش زبان طبیعی مبتنی بر ترنسفورمر هستند.
برای پردازش یک ورودی متنی با یک مدل ترنسفورمر، ابتدا باید آن را به دنبالهای از کلمات تبدیل کنید. سپس این نشانهها (tokens) بهصورت اعداد کدگذاری میشوند و به جاسازیهایی تبدیل میشوند که نمایشهای فضای برداری از نشانهها هستند و معنای خود را حفظ میکنند. در مرحله بعد، رمزگذار (encoder) در ترنسفورمر، جاسازیهای تمام نشانهها را به یک بردار محتوا تبدیل میکند. در زیر نمونهای از یکرشته متنی، نشانهگذاری و جاسازی آن را مشاهده میکنید. توجه داشته باشید که نشانهگذاری میتواند زیر کلمه باشد، مانند کلمه “nosegay” در متن به “nose” و “gay” تبدیل شده است.
As she said this, she looked down at her hands, and was surprised to find that she had put on one of the rabbit’s little gloves while she was talking. “How can I have done that?” thought she, “I must be growing small again.” She got up and went to the table to measure herself by it, and found that, as nearly as she could guess, she was now about two feet high, and was going on shrinking rapidly: soon she found out that the reason of it was the nosegay she held in her hand: she dropped it hastily, just in time to save herself from shrinking away altogether, and found that she was now only three inches high.
مثالی از رشته متن ورودی
[‘As’, ‘ she’, ‘ said’, ‘ this’, ‘,’, ‘ she’, ‘ looked’, ‘ down’, ‘ at’, ‘ her’, ‘ hands’, ‘,’, ‘ and’, ‘ was’, ‘ surprised’, ‘ to’, ‘ find’, ‘ that’, ‘ she’, ‘ had’, ‘ put’, ‘ on’, ‘ one’, ‘ of’, ‘ the’, ‘ rabbit’, “‘s”, ‘ little’, ‘ gloves’, ‘ while’, ‘ she’, ‘ was’, ‘ talking’, ‘.’, ‘ “‘, ‘How’, ‘ can’, ‘ I’, ‘ have’, ‘ done’, ‘ that’, ‘?”‘, ‘ thought’, ‘ she’, ‘,’, ‘ “‘, ‘I’, ‘ must’, ‘ be’, ‘ growing’, ‘ small’, ‘ again’, ‘.”‘, ‘ She’, ‘ got’, ‘ up’, ‘ and’, ‘ went’, ‘ to’, ‘ the’, ‘ table’, ‘ to’, ‘ measure’, ‘ herself’, ‘ by’, ‘ it’, ‘,’, ‘ and’, ‘ found’, ‘ that’, ‘,’, ‘ as’, ‘ nearly’, ‘ as’, ‘ she’, ‘ could’, ‘ guess’, ‘,’, ‘ she’, ‘ was’, ‘ now’, ‘ about’, ‘ two’, ‘ feet’, ‘ high’, ‘,’, ‘ and’, ‘ was’, ‘ going’, ‘ on’, ‘ shrinking’, ‘ rapidly’, ‘:’, ‘ soon’, ‘ she’, ‘ found’, ‘ out’, ‘ that’, ‘ the’, ‘ reason’, ‘ of’, ‘ it’, ‘ was’, ‘ the’, ‘ nose’, ‘gay’, ‘ she’, ‘ held’, ‘ in’, ‘ her’, ‘ hand’, ‘:’, ‘ she’, ‘ dropped’, ‘ it’, ‘ hastily’, ‘,’, ‘ just’, ‘ in’, ‘ time’, ‘ to’, ‘ save’, ‘ herself’, ‘ from’, ‘ shrinking’, ‘ away’, ‘ altogether’, ‘,’, ‘ and’, ‘ found’, ‘ that’, ‘ she’, ‘ was’, ‘ now’, ‘ only’, ‘ three’, ‘ inches’, ‘ high’, ‘.’]
مثالی از متن نشانهگذاری شده
بردار محتوا مانند ماهیت و جوهره کل متن ورودی است. با استفاده از این بردار، رمزگشای ترنسفورمر (decoder) بر اساس سرنخها، خروجی را تولید میکند. بهعنوانمثال، میتوانید ورودی اصلی را بهعنوان سرنخ ارائه دهید و اجازه دهید رمزگشای ترنسفورمر کلمه بعدی را که به در حالت عادی و در زبان ما انسانها به دنبال کلمه قبلی آورده میشود، تولید کند. سپس، میتوانید از همان رمزگشا دوباره استفاده کنید، اما این بار سرنخ، کلمه بعدی خواهد بود که قبلاً تولید شده است. این فرایند را میتوان برای ایجاد یک پاراگراف کامل، با شروع از یک جمله اصلی تکرار کرد و اینگونه میتوان با داشتن یک جمله اصلی یک پاراگراف متنی را تولید کرد.
به این فرایند تولید نسل خودرگرسیونی (auto-regressive generation) گفته میشود. یک مدل زبانی بزرگ دقیقاً اینگونه کار میکند، با این تفاوت که چنین مدل زبانی بزرگی همان مدل ترنسفورمری است که میتواند متن ورودی بسیار طولانی بگیرد. بردار محتوا بزرگ است و بنابراین میتواند مفاهیم بسیار پیچیده را مدیریت کند و دارای لایههای زیادی در رمزگذار و رمزگشای خود است.
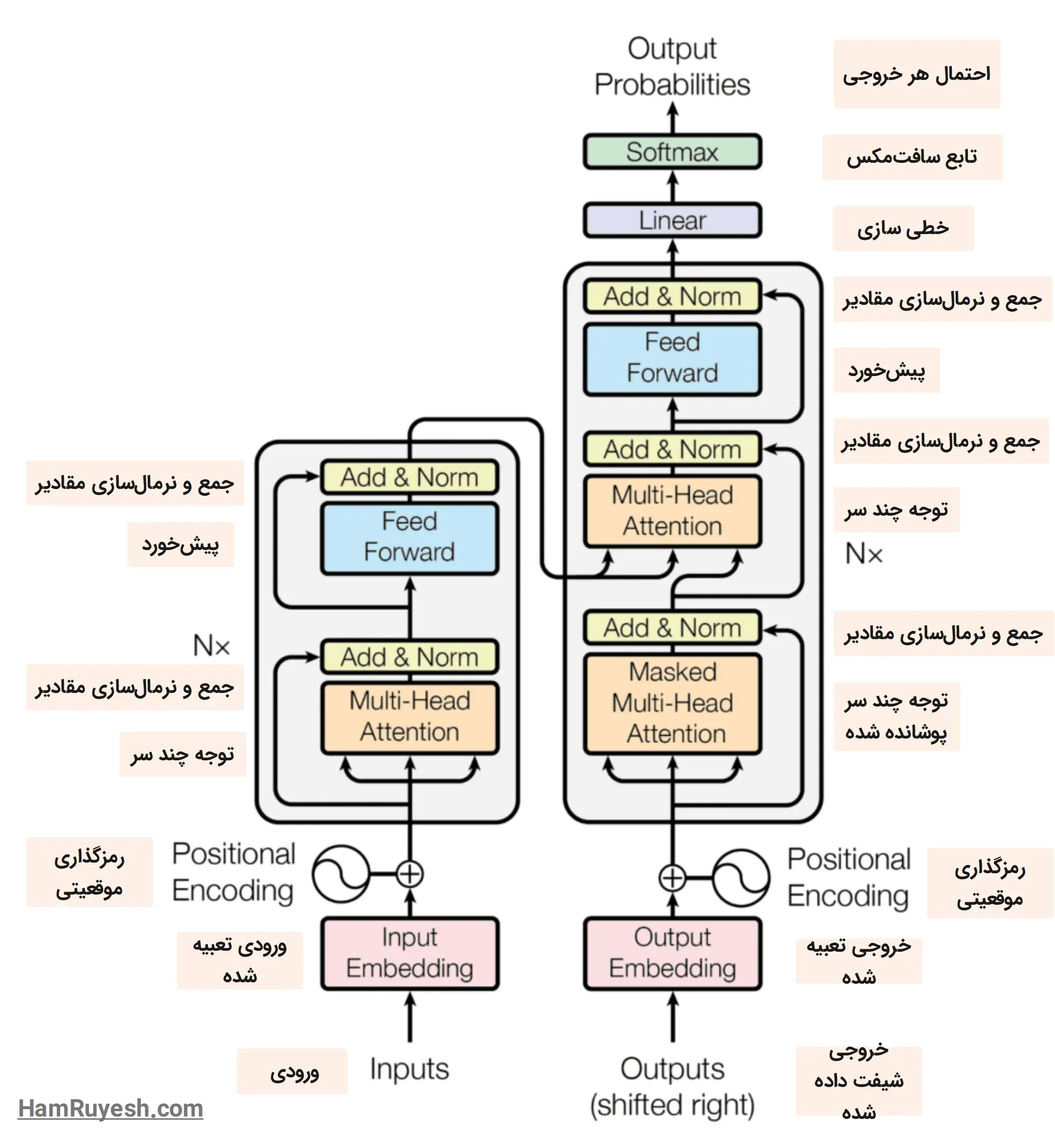
چرا Transformer میتواند متن را پیشبینی کند؟
آندری کارپاثی (Andrej Karpathy) در پست وبلاگ خود “اثربخشی غیرمنطقی شبکههای عصبی بازگشتی” نشان داد که شبکههای عصبی بازگشتی میتوانند کلمه بعدی یک متن را بهخوبی پیشبینی کنند. نهتنها به این دلیل که در زبان انسانی قواعدی وجود دارد (بهعنوانمثال دستور زبان) که استفاده از کلمات را در مکانهای مختلف یک جمله محدود میکند، بلکه به این دلیل که فراوانی و حشو بسیاری در زبانها وجود دارد.
بر اساس مقاله تأثیرگذار کلود شانون (Claude Shannon)، “پیشبینی و آنتروپی انگلیسی چاپ شده“، زبان انگلیسی با وجود داشتن ۲۷ حرف (شامل فاصله) دارای آنتروپی ۲.۱ بیت در هر حرف است. اگر حروف به طور تصادفی استفاده میشد، آنتروپی به ۴.۸ بیت افزایش مییافت که پیشبینی کلمه بعدی که در متن به زبان انسانی میآید را آسانتر میکرد.یادگیری مدلهای یادگیری ماشین و بهویژه مدلهای ترنسفورمر در انجام چنین پیشبینیهایی مهارت دارند.
با تکرار این فرایند، یک مدل ترنسفورمر میتواند کل متن را کلمه به کلمه تولید کند. بااینحال، گرامر یا دستور زبانی که از دید یک مدل ترنسفورمر دیده میشود چگونه است؟ اساساً، گرامر نشان میدهد که چگونه کلمات در زبان استفاده و به چه ترتیبی آورده میشوند. بر این اساس آنها را به بخشهای مختلف گفتار طبقهبندی میکند و نیاز به نظم خاصی در یک جمله دارد. با وجود این، شمردن تمام قواعد دستور زبان چالشبرانگیز است. در واقعیت، مدل ترنسفورمر به طور واضح این قوانین را ذخیره نمیکند، در عوض آنها را به طور ضمنی از طریق مثالها به دست میآورد. این امکان وجود دارد که مدل فراتر از قوانین دستور زبان، به ایدههای ارائه شده در مثالها دست یابد، البته به شرطی که مدل ترنسفورمر بهاندازه کافی بزرگ باشد.
چگونه یک مدل زبانی بزرگ ساخته میشود؟
یک مدل زبانی بزرگ یک مدل ترنسفورمر در مقیاس بزرگ است. آنقدر بزرگ است که معمولاً روی یک رایانه قابل اجرا نیست. ازاینرو طبیعتاً سرویسی است که از طریق API یا یک رابط وب ارائه میشود. همانطور که میتوانید انتظار داشته باشید، چنین مدل بزرگی قبل از اینکه بتواند الگوها و ساختارهای زبان را بهخاطر بسپارد، از مقدار زیادی متن آموخته میشود.
بهعنوانمثال، مدل GPT-3 که از سرویس چت جی پی تی ChatGPT پشتیبانی میکند، بر روی حجم عظیمی از دادههای متنی از اینترنت آموزش داده شده است. این آموزش شامل کتابها، مقالات، وبسایتها و منابع مختلف دیگر میشود. در طول فرایند آموزش، مدل روابط آماری بین کلمات، عبارات و جملات را یاد میگیرد. این امر به مدل اجازه میدهد که پاسخهای منسجم و مرتبط بامحتوا را در صورت دریافت دستور یا سؤال تولید کند.
مدل GPT-3 با استخراج از این حجم عظیم متن، میتواند چندین زبان را متوجه بشود و از موضوعات مختلف اطلاعات داشته باشد. به همین دلیل است که میتواند متن را به سبکهای مختلف تولید کند. در حالی که ممکن است شگفتزده شوید از اینکه مدل زبانی بزرگ میتواند ترجمه، خلاصهسازی متن و پاسخگویی به سؤالات را انجام دهد، تعجب نمیکنید که دستور زبان این پاسخها با گرامر متن اصلی موسوم به prompt، تطابق دارد.
هم رویش منتشر کرده است:
آموزش ChatGPT — شروع سریع ویژه ایرانیان
خلاصه
چندین مدل زبانی بزرگ تابهحال توسعهیافته است. بهعنوانمثال میتوان به GPT-3 و GPT-4 از OpenAI و LLaMA از Meta و PaLM2 از Google اشاره کرد. اینها مدلهایی هستند که میتوانند زبان انسانی را درک کنند و همچنین میتوانند متن تولید کنند.
در این مقاله یاد گرفتید که:
- مدل زبانی بزرگ مبتنی بر معماری ترنسفورمر است.
- مکانیسم توجه به LLMها اجازه میدهد تا وابستگیهای دوربرد بین کلمات را بهخاطر بسپارند، بنابراین مدل میتواند محتوای متن ورودی را درک کند.
- مدل زبان بزرگ میتواند متنی را بهصورت خود بازگشتی بر اساس نشانههای تولید شده قبلی تولید کند.
واژگان
مدل زبانی بزرگ | درباره مدل زبانی بزرگ | مدل ترنسفورمر | Large language models چیست | کدام چت بات بهتر است | یادگیری انتقالی چیست | Transformer چیست؟ | چت جی پی تی چگونه کار میکند؟ | مدل زبانی بزرگ LLM چیست | مدل زبانی بزرگ چیست | مدل ترنسفورمر چیست








2 دیدگاه برای “مدل زبانی بزرگ LLM چیست؟ ”
مقاله مختصر و مفید با ترجمه بسیار خوب. دست مریزاد مهندس فرجی عزیز
سپاسگزارم جناب مهندس آصفی