مقدمهای بر طبقه بندی ویدئو
بسیاری از مقالات و آموزشهای یادگیری عمیق در درجه اول بر سه حوزهی داده تمرکز میکنند: تصاویر، گفتار و متن. این حوزههای داده برای کاربردهای خود در طبقه بندی تصویر، بازشناسی گفتار و طبقهبندی احساسات متنی محبوب هستند. یکی دیگر از موارد بسیار جالب داده، ویدئو است.
از دیدگاه ابعاد و اندازه، ویدئوها یکی از جالبترین انواع دادهها در کنار مجموعه دادههایی مانند شبکههای اجتماعی یا کدهای ژنتیکی هستند. پلتفرمهای آپلود ویدیویی مانند یوتیوب، در حال جمعآوری مجموعه دادههای عظیمی هستند که تحقیقات یادگیری عمیق را تقویت میکنند.
یک ویدئو واقعا فقط مجموعهای از تصاویر است. این نوشتار، مقاله ای با عنوان “Large-scale Video Classification with Convolutional Neural Networks“ را كه در مورد تحقیقات طبقه بندی ویدئویی به رهبری Andrej Karpathy، که در حال حاضر مدیر AI در تسلا است، مرور خواهد کرد.
این مقاله ویدئوهایی را با شبکه های کانولوشنی به روشی بسیار شبیه به مدلسازی تصاویر با CNNs، مدلسازی میکند. این مقاله یک نوشتار مهم برای نمایش قدرت شبکه های کانولوشنی است. قبل از این کار، تحقیقات طبقه بندی ویدئو تحت سیطرهی مجموعه ای از ویژگیهای کلمات بصری چندی شده در یک فرهنگ لغت k – means بود و با یک مدل یادگیری ماشین مانند SVM طبقهبندی میشد. برجسته کردن قدرت CNNsها مجرد از همهی این الگوریتمهای مهندسی ویژگی قبلی است. این مقاله همچنین به عنوان پایه و اساس خوبی از ایدهها برای ادغام جزء زمانی ویدئوها در مدلهای CNN عمل میکند.
این مقاله به بررسی سه جزء مختلف طبقه بندی ویدئو میپردازد. طراحی CNNهایی که قابلیت اتصال زمانی در ویدئوها را دارند، CNNهایی با وضوح چندگانه که میتوانند محاسبات را سرعت بخشند، و موجب اثربخشی یادگیری انتقالی در طبقهبندی ویدئو شوند.
هم رویش منتشر کرده است:
آموزش بینایی کامپیوتر با پایتون و OpenCV ___ بسته جامع
مجموعه دادهی مورد بحث
یکی از مهمترین اجزای هر پروژهی یادگیری عمیق، درک مجموعه دادهی مورد استفاده است. این مقاله از یک مجموعه دادهای كه متشکل از ۱ میلیون ویدئوی یوتیوب در ۴۸۷ کلاس است، استفاده کردهاست. همچنین این مقاله با یادگیری انتقالی از ویژگیهای آموختهشده از مجموعه دادهی عظیم، از آن ویژگیها، برای آزمایش مجموعه دادهی کوچکتر UCF – ۱۰۱ كه شامل ۱۳۳۲۰ ویدئو متعلق به ۱۰۱ دسته است، استفاده میکند.
دو نگرانی جدّی در رابطه با مجموعه دادههای ویدئویی
نگرانی اول:
دو نگرانی جدّی در رابطه با مجموعه دادههای ویدئویی مورد استفاده وجود دارد. اولی اندازهی بزرگ مجموعه داده است، بنابراین امکان بارگذاری کل مجموعه داده به حافظه محلی غیرعملی میشود. یک راهحل برای این کار، استفاده از کتابخانهی تجزیهی url برای بارگیری پویای ویدئوها از لینکهای یوتیوب آنها و بازنویسی ویدئوهایی است که در حال حاضر در حافظه هستند که در اندازهی دسته قبلی مورد استفاده قرار گرفتهاند. برای سرعت بخشیدن به این امر، یک سیستم محاسباتی موازی استفاده میشود به طوری که میتوان این دستهها را در دستگاه جداگانهای نسبت به دستگاهی که مدل را آموزش میدهد، بارگیری و پیش پردازش کرد.Karpathy و همکاران از یک خوشه محاسباتی برای پیادهسازی این آزمایشها استفاده میکنند که برای این نوع خط لولهی پردازش دادهها بسیار مناسب است.
نگرانی دوم:
نگرانی دوم در مورد این مجموعه داده، مورد طول متغیر هر نمونه است که به طور مکرر در کاربردهای متن کاوی، یافت میشود. برای مثال، یک ویدئو ممکن است ۳۰ ثانیه باشد، در حالی که ویدئو دیگر ۲ دقیقه است. در متن، این مساله با اضافه کردن ۰ به انتهای متن به گونهای حل میشود که تمام ورودیها دارای طول یکسان باشند. این مقاله با پیشبینی برشهایی از ویدئوها و تجمیع پیشبینیها در برشها در این زمینه کار میکند. من فکر میکنم که این یک جزئیات بسیار مهم از مقاله است که باید به خاطر داشته باشید. همهی ویدئوها به شبکه تغذیه نمیشوند، بلکه از مجموعهای از کلیپهای نیم ثانیهای استفاده میکنند. ویدیوها معمولا در ۳۰ فریم بر ثانیه ضبط میشوند. بنابراین، این کلیپها از ۱۵ فریم تشکیل شدهاند.
تجمیع پیشبینیها در کلیپ نیم ثانیهای مفهومی مشابه با افزایش زمان آزمایش در طبقهبندی تصویر است. پیش بینی کلاس برای یک تصویر با پیش بینی همان تصویر پس از چرخش، برش، كراپ یا افزایش فضای رنگی آن ترکیب میشود. این آزمایشها برای طبقهبندی ویدئو را اغلب با معکوس کردن و برش دادن کلیپهای نیم ثانیهای تست میکنند.
ترکیب اطلاعات زمانی
برای استفاده از اطلاعات حرکت محلی موجود در ویدئو ، چه الگوی اتصال زمانی در معماری CNN بهتر است؟
اطلاعات حرکتی اضافی چگونه بر پیشبینیهای CNN تاثیر میگذارد و به طور کلی چقدر باعث بهبود عملکرد میشود؟
شاید جالبترین موضوع این مقاله این باشد که چگونه یک شبکه کانولوشن کلاسیک برای در نظر گرفتن وابستگیهای زمانی در ویدئوها اصلاح میشود. در این مقاله، یک دسته از فریمها روی هم قرار گرفته و به CNN وارد میشوند. به طور کلاسیک، یک CNN از ورودی یک ماتریس به شکل (کانالهای رنگی * عرض * ارتفاع) میگیرد. برای مثال، این224×224×3 میتواند یک تنسور ورودی باشد. در این آزمایشها، فریمهای قبلی در بالای محور کانال رنگی روی هم انباشته شدهاند به طوری که ورودی متشکل از دو فریم ویدئو به شکل 224×224×6 میباشد.
Karpathy و همکاران ۳ استراتژی مختلف را برای ترکیب فریمها به عنوان ورودی CNN پیشنهاد میکنند و این روشها را با یک مدل مبنا برای طبقهبندی فریمها بطور همزمان مقایسه میکنند.
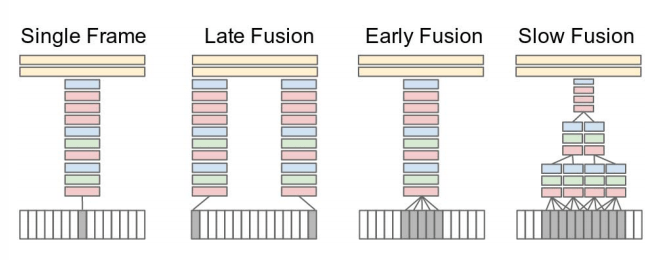
مدل Single Frame، نمونهای از طبقهبندی ویدئوها از طریق تجمیع سادهی پیشبینیها از میان فریمها / تصاویر تکی است. مدل Late Fusion، فریمها را با الحاق فریم اول و آخر در کلیپ ترکیب میکند. مدل Early Fusion یک بخش پیوستهی بزرگ از کلیپ را میگیرد. در نهایت، مدل Slow Fusion دارای یک طرح بسیار پیچیدهتر است که در آن ۴ قطعه مجاور، هم پوشانی جزئی دارند که در لایههای کانولوشنی به تدریج ترکیب میشوند. آزمایشهای فردی بیشترین موفقیت را با استراتژی Slow Fusionکسب کردند، هرچند که به طور قابلتوجهی بیشتر از مدل Single Frame نبود. بهترین نتایج کلی، با میانگینگیری از نتایج، در تمام مدلها بدست آمد (تکی + زود + دیر + کند).
CNNs چند رزولوشنی
یک مفهوم بسیار جالب دیگر که در این مقاله مورد بحث قرار گرفتهاست، یک استراتژی جذاب برای پردازش تصویر است. CNN چند رزولوشنی به شرح زیر عمل میکند:
دو ورودی جداگانه به لایههای کانولوشن جداگانه تغذیه میشوند که پس از دو توالی مجزا از Conv – MaxPol – BatchNorm با یکدیگر ترکیب میشوند. این ورودیهای چندگانه، ترکیبی از یک فریم با نمونه برداری کاهشی شده به فریم و یک مرکز برش یافته از فریم اصلی است.
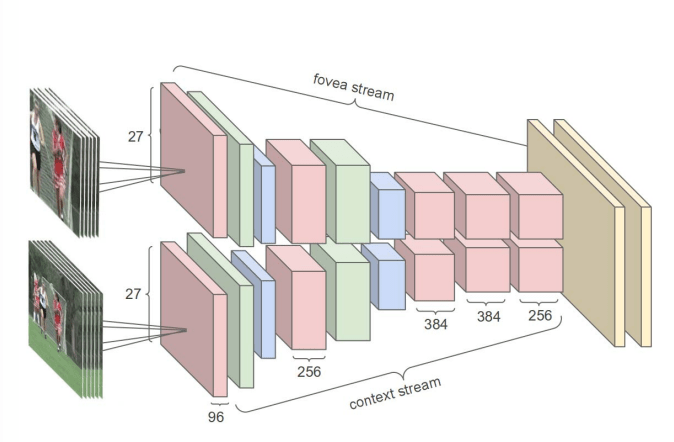
این استراتژی زمان زیادی از محاسبات را برای لایههای کانولوشنی صرفهجویی میکند. نویسندگان یک افزایش 2 تا 4 برابری در سرعت را به دلیل این طرح کاهش ابعاد گزارش کردهاند.
به طور خاص، آنها سرعت ۵ کلیپ در ثانیه را با یک شبکه فول فریم و ۲۰ کلیپ در ثانیه را با یک شبکه چند رزولوشنی گزارش میکنند. آنها همچنین تأکید میکنند که در صورت استفاده از پردازندهی گرافیکی پیشرفته به جای موازیسازی در خوشه محاسباتی آنها با 10 تا 50 مدل تکراری، میتوان این سرعت را بیشتر کرد. علاوه بر افزایش سرعت، بهبود اندکی را نسبت به مدل Single Frame گزارش میدهند که در اصل از فریمهای استفاده میكند.
هم رویش منتشر کرده است:
آموزش پردازش تصویر با OpenCV و پایتون (شروع سریع و عمیق)
آموزش یادگیری انتقالی در طبقه بندی ویدئو
انتقال یادگیری در پردازش تصویر به شدت مورد مطالعه قرار گرفتهاست و یک مفهوم بسیار شهودی است. مدل را بر روی یک مجموعه داده بزرگ مانند ImageNet، با 1.2M تصویر آموزش دهید، این وزنها را به یک مساله با دادههای کمتر انتقال دهید، و سپس وزنها را بر روی مجموعه دادهی جدید تنظیم (fine-tune) کنید.
در این مقاله، Karpathy و همکاران، ویژگیها را از مجموعه دادهی Youtube-1M به مجموعه دادهی مشهور پردازش ویدئویی، UCF-101 انتقال میدهند. آنها را با سه سطح یادگیری انتقالی، آزمایش کردند. و این را با آموزش ابتدایی بر روی مجموعه دادهی UCF-101 مقایسه کردند.
سطوح یادگیری انتقالی مورد مطالعه شامل تنظیم دقیق لایهی بالایی، تنظیم دقیق ۳ لایهی بالایی، و تنظیم دقیق همه لایهها بود. به عنوان مثال، زمانی که لایهی بالایی تنظیم دقیق میشود، بقیه وزنها در شبکه در طول آموزش “فریز” میشوند. به این معنی که آنها تنها در گذر رو به جلو شبکه شرکت میکنند و از طریق پس انتشار به روز نمیشوند.
در این مقاله، افزایش عملکرد، با استفاده از استراتژی ترکیب زمانی (Time Fusion) و رزولوشن چندگانه (Multi-Resolution) تا حدودی ناچیز بود. با این حال، نتایج یادگیری انتقالی بسیار چشم نواز هستند. اگر این گزارش، نتایج شبکه Single Frame را نیز نشان میداد، که اگر طرح Slow Fusion برای یادگیری انتقالی موثرتر بود، این دو در تقابل باشند.
نتیجهگیری
من تحتتاثیر نتایج گزارششده قرار گرفتم که مدل Slow Fusion همواره از مدلهای Single-Fram بهتر عمل میکند. با وارد شدن به این مقاله، انتظار داشتم که الگوریتمهای ترکیب زمانی، متشکل از ویژگیهای CNN باشند که به یک مدل بازگشتی مانند LSTM تغذیه میشوند. من فکر میکنم که مدل Slow Fusion را به سادگی میتوان با دو برابر کردن اندازهی بلوکهای پیوسته، شاید اتصال بلوکهای پیوسته با فاصله پارامتری از چند قاب و اضافه کردن اتصالات باقی مانده بهبود بخشید.
من فکر میکنم که پردازش چند رزولوشنی ایده بسیار جالبی برای تصاویر و ویدئو است که میتواند به گفتار و صوت نیز بسط داده شود. این مکانیزم در درجه اول برای افزایش سرعت محاسبات با کاهش اندازهی ورودی طراحی شدهاست. با این حال، من فکر میکنم جالب خواهد بود که این را معکوس کنیم و دقت طبقهبندی را بعد از نمونهبرداری از تصاویر با یک تکنیک با وضوح بالا مانند SR-GANs آزمایش کنیم.
دیدن موفقیت یادگیری انتقالی در تصاویر و بسط دادن آن به ویدئوها، دلگرمکننده است. تقریبا افزایش ۲۵ درصدی دقت در UCF – ۱۰۱ پس از آموزش در مجموعه دادهی YouTube-1M، به طور شوکه کنندهای بالا است.
این مقاله یک پایه و اساس عالی برای بررسی طبقه بندی ویدئو است. این مقاله به خوبی نوشته شده و در مورد بسیاری از ویژگیهای مهم، ساخت مدلهای یادگیری عمیق بر روی دادههای ویدئویی بحث میکند. لطفاً نظر خود را در مورد مقاله یا این نوشتار بنویسید.
+ پیش از این آموزش ربات هوش مصنوعی ChatGPT در همرویش منتشر شد. برای دیدن فیلم معرفی این آموزش بر روی لینک آموزش ربات هوش مصنوعی ChatGPT و یا پخش کننده پایین کلیک کنید:
برای تهیه این بسته آموزشی میتوانید به لینک آموزش ChatGPT مراجعه کنید.
کلید واژگان
طبقه بندی ویدئو – طبقه بندی ویدیو – طبقه بندی ویدئو ها – شبکه های کانولوشنی – شبکه های عصبی کانولوشنی – شبکه های عصبی کانولوشن – یادگیری انتقالی – یادگیری انتقالی چیست – پردازش ویدئو – ویدئو کاوی – پردازش ویدئو چیست – پردازش ویدیو چیست – پردازش تصویر ویدئو – پردازش تصویر ویدیو – ویدئوکاوی – پردازش تصویر – پردازش تصویر چیست – شبکه های کانولوشنی
منبع :
Introduction to Video Classification
دوره های آموزشی مرتبط
-
 پردازش تصویر چیست ؟ OpenCV چیست ؟
رایگان
پردازش تصویر چیست ؟ OpenCV چیست ؟
رایگان -
 آموزش YOLO - تشخیص اشیا با پایتون در OpenCV
۷۵,۰۰۰ تومان
آموزش YOLO - تشخیص اشیا با پایتون در OpenCV
۷۵,۰۰۰ تومان





