پیش از این در همرویش فیلم شبکه عصبی کانولوشنی به زبان ساده منتشر شد. برای دیدن فیلم معرفی این آموزش بر روی این لینک (+) و یا پخش کننده پایین کلیک کنید:
برای دریافت بسته کامل این آموزش بر روی لینک زیر کلیک کنید:
شبکه عصبی کانولوشن به زبان ساده
ELI5 چیست ؟
ELI5 مخفف این عبارت است: Explain like I’m 5. یعنی طوری به من توضیح بده که انگار 5 ساله هستم!! پس با این مقاله از مجله هم رویش همراه باشید تا شبکههای عصبی کانولوشنی را به سادهترین شکل ممکن برایتان توضیح دهیم!
هوش مصنوعی، شاهد رشدی چشمگیر در راستای از بین بردن شکاف موجود میان تواناییهای انسان و ماشین بوده است. پژوهشگران و علاقمندان نیز به همین سرعت، بر روی جنبههای گوناگون این حوزه کار کردهاند تا اتفاقات شگفت انگیزی را محقق کنند. یکی از زمینههای متعدد این حوزه، بینایی کامپیوتر است.
هم رویش منتشر کرده است:
آموزش شبکه عصبی مصنوعی -- از صفر به زبان ساده
هدف این رشته، این است که ماشینها بتوانند جهان را همانگونه که انسانها میبینند، مشاهده کنند، آن را به روشی مشابه درک کنند و حتی از این دانش در راستای انجام بسیاری از کارها نظیر تشخیص تصویر و فیلم، تحلیل و دستهبندی تصویر، سرگرمیهای رسانهای، سیستمهای توصیه گر، پردازش زبان طبیعی و … استفاده کنند.
پیشرفت و توسعهی حوزه بینایی ماشین، با یادگیری عمیق شکل گرفته و به مرور زمان تکمیل یافته است. این پیشرفت در درجه اول، مدیون یک الگوریتم مشخص است: شبکه عصبی کانولوشنی.
** اگر قصد دارید در قالب یک فیلم کوتاه با ساختار کلی شبکه عصبی کانولوشنی آشنا شوید بر روی این لینک (+) و یا پخش کننده پایین کلیک کنید:
معرفی
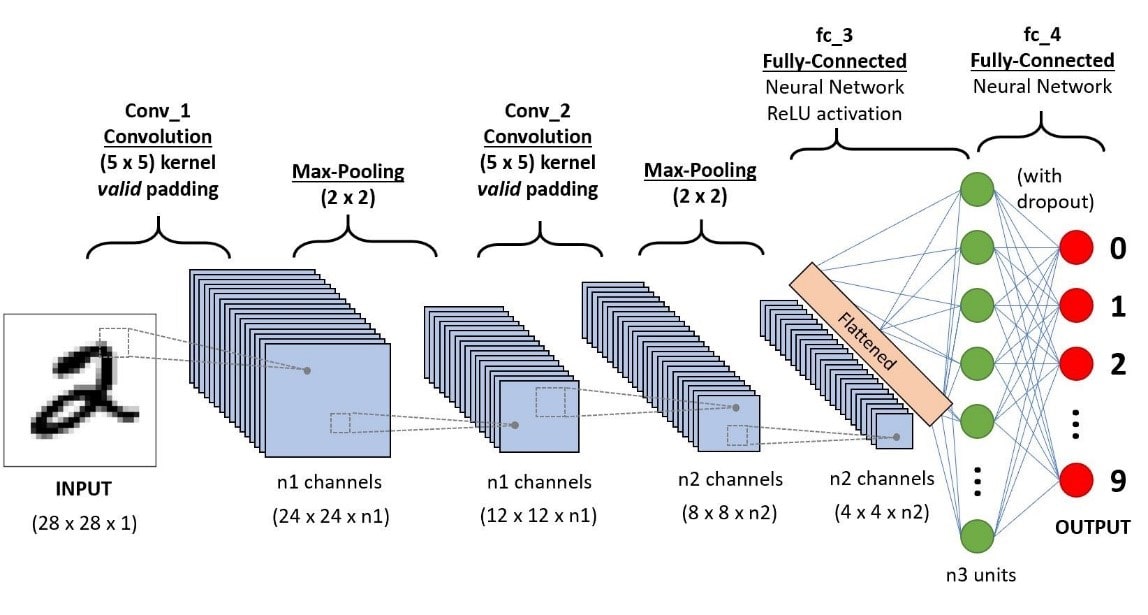
یک شبکه عصبی کانولوشنی (CNN یا ConvNet)، یک الگوریتم یادگیری عمیق بوده که قادر است یک ورودی تصویری را دریافت کند. به جنبهها یا اشیای مختلف موجود در تصویر، اهمیت (وزنها و بایاسهای قابل یادگیری) اختصاص دهد. و در نهایت بتواند یکی را از دیگری متمایز کند. پیش پردازش مورد نیاز در یک شبکه کانولوشنی، به مراتب کمتر از سایر الگوریتمهای دستهبندی است. همچنین این شبکهها، توانایی یادگیری فیلترها یا ویژگیها را دارند، در حالی که در روشهای اولیه، این فیلترها به صورت دستی طراحی و مهندسی میشدند.
هم رویش منتشر کرده است:
آموزش ساخت شبکه عصبی با پایتون (و دیگر زبانها) از صفر
معماری شبکه کانولوشنی
معماری شبکه کانولوشنی، مشابه الگوی اتصال نورونها در مغز انسان است و از قشر دیداری الهام گرفته شده است. نورونها تنها در یک ناحیه محدود از میدان دید به محرکها پاسخ میدهند که به آن، میدان پذیرش (Receptive Field) گفته میشود. مجموعهای از این میدانها، با هم همپوشانی دارند تا کل ناحیهی بینایی را پوشش دهند.
+ در ادامه ببیند مفهوم کانولوشن چیست؟
مزیت شبکههای کانولوشنی بر شبکههای عصبی پیشخور
یک تصویر، چیزی نیست جز یک ماتریس از مقادیر پیکسلها، مگر نه؟! پس شاید فکر کنید کافیست یک تصویر را مسطح کنیم (مثلا یک ماتریس تصویر 3×3 را به یک بردار 9×1 تبدیل کنیم) و سپس آن را با هدف دستهبندی به یک شبکه پرسپترون چندلایه تحویل دهیم. اما نه … به این سادگیها هم نیست!!
در مواردی که با عکسهای باینری بسیار ساده سروکار داریم، این روش ممکن است در حین پیش بینی دستهها، یک دقت متوسط از خود نشان دهد. اما در مورد تصاویر پیچیدهای که در آنها وابستگی به پیکسل وجود دارد، دقت چندانی ندارد.
یک شبکه کانولوشنی قادر است با استفاده از فیلترهای مربوطه، وابستگیهای مکانی و زمانی یک تصویر را با موفقیت ضبط و ثبت کند. این معماری، به واسطه کاهش تعداد پارامترهای درگیر و امکان استفادهی مجدد از وزنها، سازگاری بهتری در مواجه با دیتاستهای تصویری از خود نشان میدهد. به بیان دیگر، این شبکه میتواند به گونهای آموزش ببیند که پیچیدگی تصاویر را بهتر درک کند.
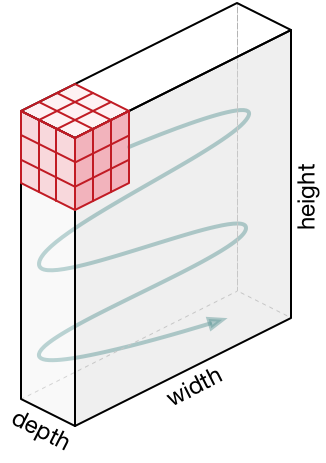
تصویر ورودی
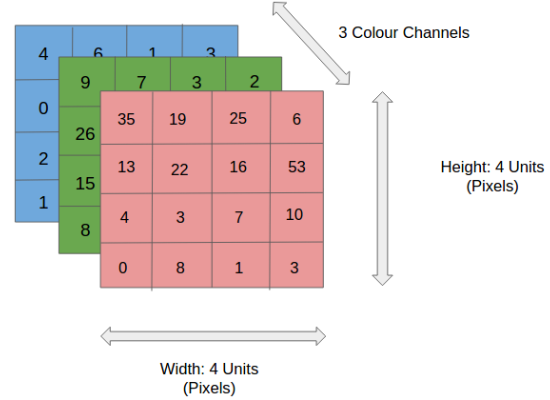
در این شکل، یک تصویر RGB داریم که به سه صفحه رنگی خود – یعنی قرمز، سبز و آبی – تجزیه شده است. شمار زیادی از این فضاهای رنگی برای نمایش تصاویر وجود دارد نظیر Grayscale, RGB, HSV, CMYK و … . میتوانید تصور کنید که وقتی تصاویر به ابعاد بالایی نظیر 8k (7680×4320) میرسند، حجم محاسبات چقدر زیاد و پیچیده میشود. نقش شبکه کانولوشنی، این است که تصاویر را به شکلی کاهش دهد که پردازش آنها سادهتر باشد؛ ان هم بدون از دست دادن ویژگیهایی که برای دستیابی به یک پیشبینی خوب، مهم و بحرانی هستند. این موضوع، زمانی اهمیت دارد که بخواهیم یک معماری طراحی کنیم که نه تنها در یادگیری ویژگیها خوب باشد، بلکه در دیتاستهای بزرگ و گسترده نیز مقیاس پذیر و قابل تعمیم باشد.
لایه کانولوشن – کرنل

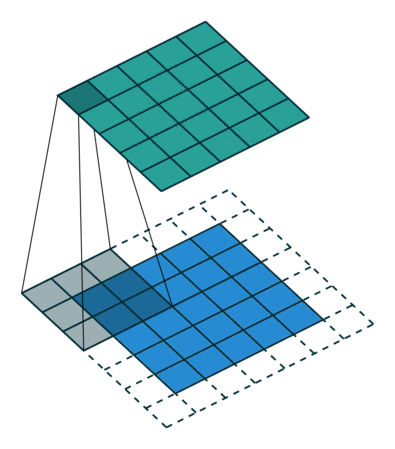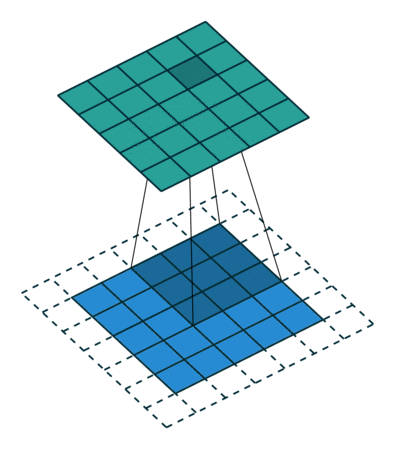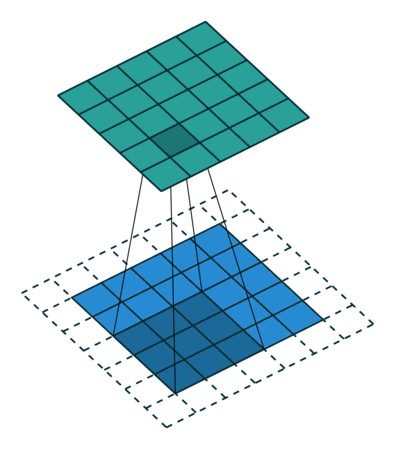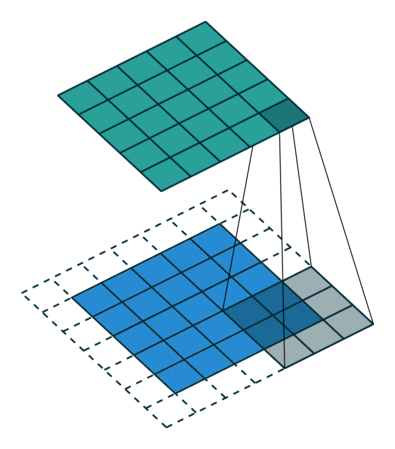
پیچش (Convoluting) یک تصویر 5x5x1 با یک کرنل 3x3x1 برای دستیابی به یک ویژگی پیچش شده (convolved feature) با ابعاد 3x3x1
ابعاد تصویر = 5 (ارتفاع) x 5 (عرض) x 1 (تعداد کانالها، مثلا برای RGB)
در شکل فوق، بخش سبز رنگ، تصویر ورودی 5x5x1 ما را نشان میدهد. المانی که در انجام عملیات کانولوشن (پیچش) در قسمت اول از لایه کانولوشنی نقش ایفا میکند، کرنل (Kernel) یا فیلتر نام دارد که با رنگ زرد نشان داده شده است. در اینجا یک ماتریس 3x3x1 را به عنوان کرنل (K) در نظر گرفتهایم.
کرنل، 9 مرتبه جابجا میشود زیرا طول گام (Stride Length) برابر با 1 است. در هر مرتبه، یک عمل ضرب ماتریسی بین ماتریس کرنل (K) و بخشی از تصویر که توسط کرنل پوشانده میشود (P) صورت میگیرد.
فیلتر با یک گام ثابت و مشخص، به سمت راست حرکت میکند تا اینکه کل عرض را طی کند. در ادامه، با همان گام ثابت، به سمت پایین حرکت کرده و به ابتدای (سمت چپ) تصویر میرود. سپس، این روند را تکرار میکند تا جایی که کل تصویر را بپیماید.
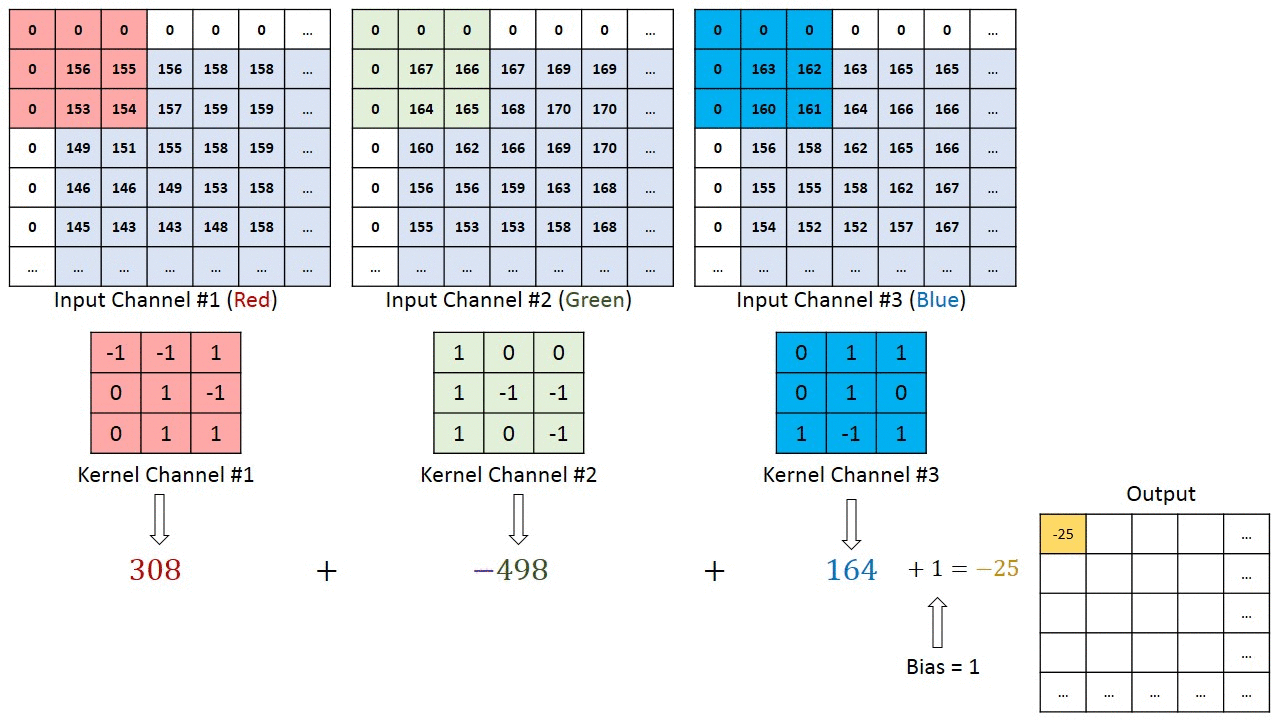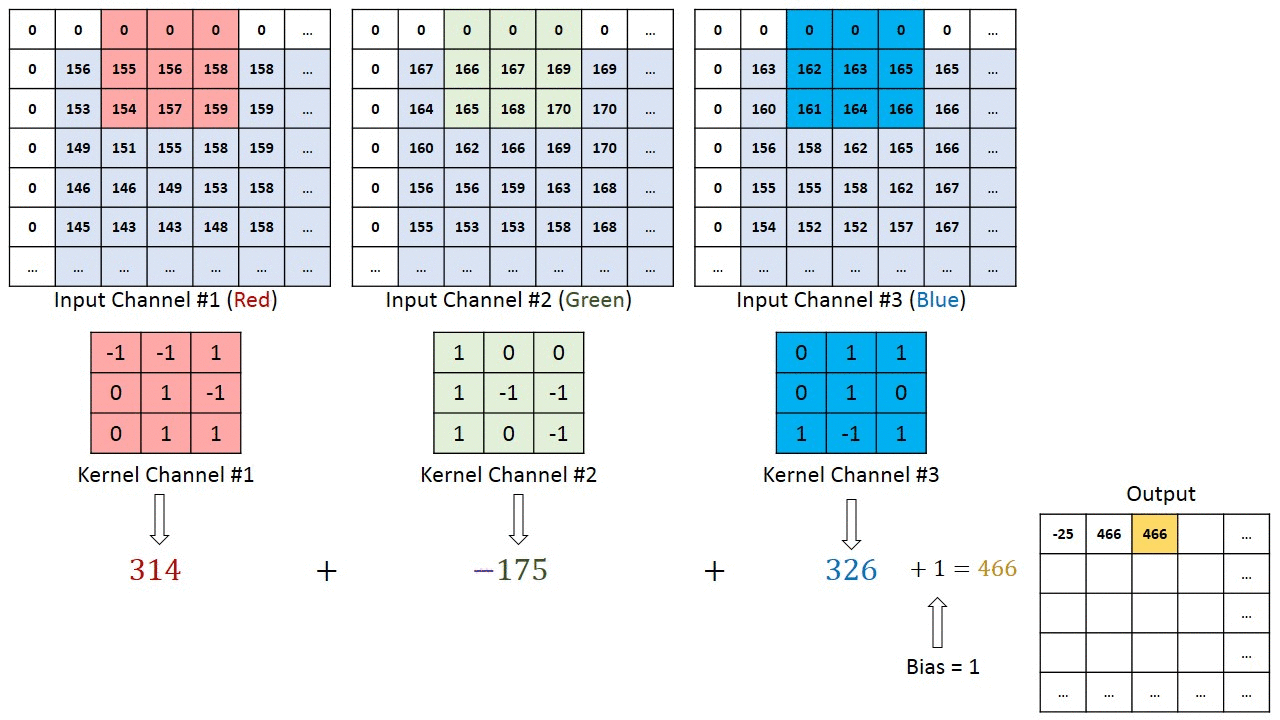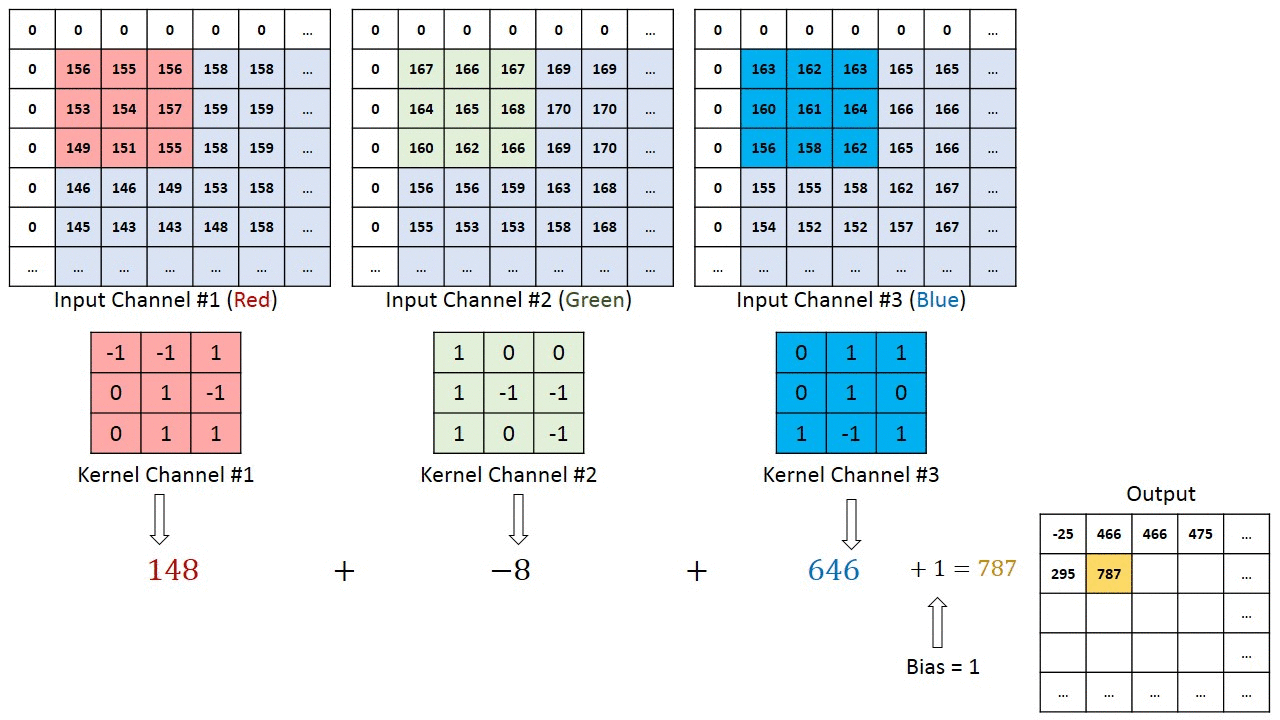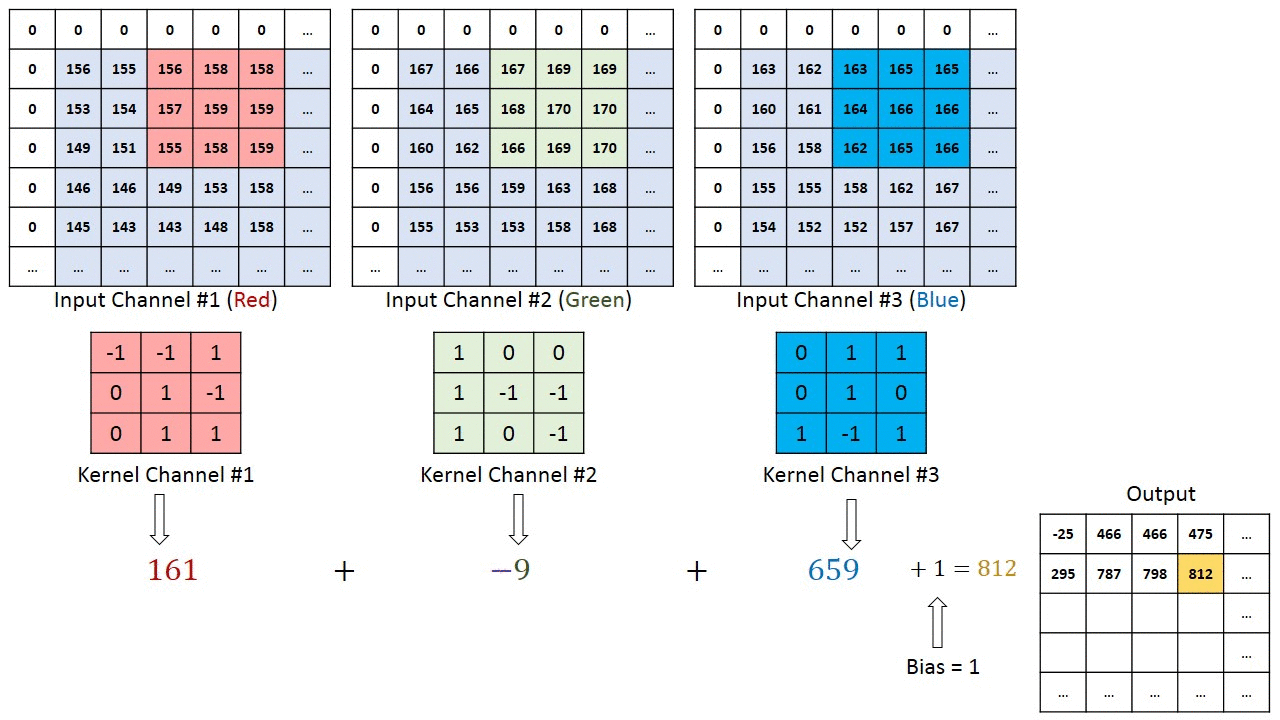
در مواردی که تصاویر، از چند کانال تشکیل شدهاند (نظیر RGB)، کرنل همان عمق تصویر ورودی را خواهد داشت. ضرب ماتریسی بین Kn و In ([K1, I1]; [K2, I2]; [K3, I3]) صورت میگیرد و تمام نتایج با بایاس جمع میشوند تا در نهایت، یک خروجی ویژگی پیچش شده (Convoluted) با کانالی به عمق 1 تحویل دهد.
+ اگر شما مشتاق شدهاید که خودتان یک شبکه کانولوشن بسازید. ما بسته آموزش کدنویسی کانولوشن (+) را به همین منظور تهیه کردهایم.
هدف عملیات کانولوشن
هدف عملیات کانولوشن، استخراج ویژگیهای سطح بالا (مانند لبه ها) از تصویر ورودی است. شبکههای کانولوشنی لازم نیست تنها به یک لایه کانولوشنی محدود شوند. به طور معمول، اولین لایه کانولوشنی، وظیفهی ضبط ویژگیهای سطح پایین نظیر لبهها، رنگ، جهت گرادیان و … را بر عهده دارد. با اضافه شدن لایههای بعدی، معماری شبکه با ویژگیهای سطح بالا نیز سازگار میشود. در نتیجه شبکهای در اختیار خواهیم داشت که درک کاملی از تصاویر موجود در دیتاست دارد، مشابه همان درکی که ما از تصاویر داریم.
این عملیات، دو نوع نتیجه در اختیار ما قرار میدهد:
در یک حالت، ابعاد ویژگی پیچش شده، در مقایسه با ورودی، کاهش یافته و در حالت دیگر، ابعاد خروجی افزایش یافته یا بدون تغییر باقی مانده است. این اتفاق در حالت اول، با استفاده از حاشیه گذاری معتبر (valid padding) و در حالت دوم، با استفاده از حاشیه گذاری همانی (same padding) رخ میدهد.
زمانی که یک تصویر 5x5x1 را به یک تصویر 6x6x1 افزایش میدهیم و سپس کرنل 3x3x1 را روی آن اعمال میکنیم، درمییابیم که ماتریس پیچش شده، ماتریسی با ابعاد 5x5x1 خواهد بود (یعنی همان ابعاد ماتریس تصویر اولیه!). در نتیجه به آن حاشیهگذاری همانی گفته میشود.
از طرف دیگر، اگر همان عملیات را بدون حاشیهگذاری انجام دهیم، به ماتریسی دست مییابیم که دارای ابعادی مشابه با ابعاد کرنل است (یعنی 3x3x1). از این رو، به آن حاشیهگذاری معتبر گفته میشود.
مخزن زیر، حاوی گیفهای بسیاری از قبیل موارد بالاست که به شما کمک میکند درک بهتری از نحوهی کار حاشیهگذاری و طول گام و عملکرد آنها در کنار یکدیگر داشته باشید.
لایه پولینگ (Pooling)
لایه پولینگ، مشابه لایه کانولوشنی، وظیفه کاهش اندازه مکانی (فضایی) ویژگی پیچش شده را برعهده دارد. این کار به منظور کاهش توان محاسباتی مورد نیاز برای پردازش دادهها از طریق کاهش ابعاد صورت میگیرد. به علاوه، این کار برای استخراج ویژگیهای غالب که از نظر چرخشی و موضعی غیرقابل تغییر هستند، و در نتیجه، برای حفظ روند آموزش موثر مدل، مفید است.
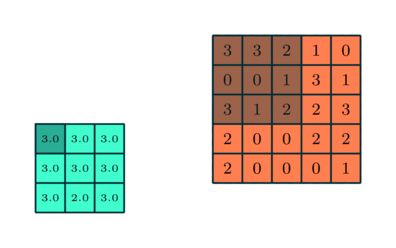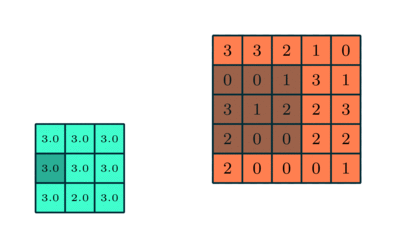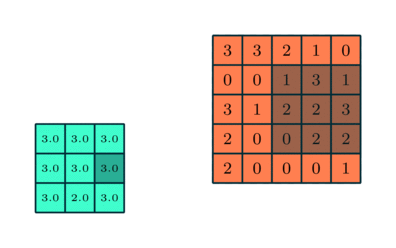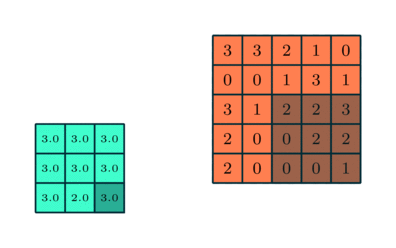
دو نوع پولینگ وجود دارد:
پولینگ حداکثری (Max Pooling) و پولینگ میانگینی (Average Pooling).
پولینگ حداکثری:
حداکثر مقدار از آن بخش تصویر که توسط کرنل پوشانده شده است را برمی گرداند. از طرف دیگر، پولینگ میانگینی، میانگین تمام مقادیر بخش تحت پوشش کرنل را برمیگرداند.
پولینگ حداکثری، به عنوان یک نویزگیر نیز عمل میکند. این نوع از پولینگ، فعالیتهای دارای نویز را به طور کلی حذف میکند و در کنار کاهش ابعاد، فرایند کاهش نویز را نیز انجام میدهد.
پولینگ میانگینی:
خیلی ساده، فرایند کاهش ابعاد را به عنوان یک مکانیسم نویزگیری نیز انجام میدهد. از این رو میتوان گفت که پولینگ حداکثری، عملکردی به مراتب بهتر از پولینگ میانگینی از خود نشان میدهد.
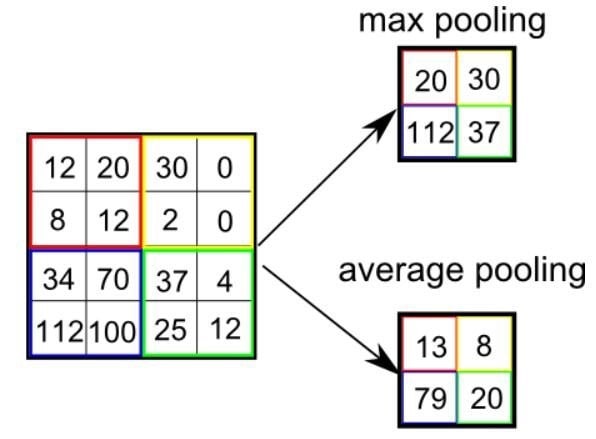
انواع پولینگ
لایه کانولوشنی و لایه پولینگ، با یکدیگر، لایه i اُم یک شبکه عصبی کانولوشنی را تشکیل میدهند. بسته به پیچیدگیهای موجود در تصاویر، ممکن است تعداد این لایهها به منظور ضبط جزئیات سطح پایین یا موارد دیگر، افزایش یابد. اما هزینه نیز با توجه به افزایش قدرت محاسباتی، بیشتر میشود.
پس از طی روند بیان شده، اکنون با موفقیت مدل را قادر کردیم که ویژگیها را درک کند. در ادامه، قصد داریم خروجی نهایی را مسطح (flatten) کرده و آن را برای اهداف دستهبندی به یک شبکه عصبی مرسوم تحویل دهیم.
دستهبندی __ لایه کاملا متصل
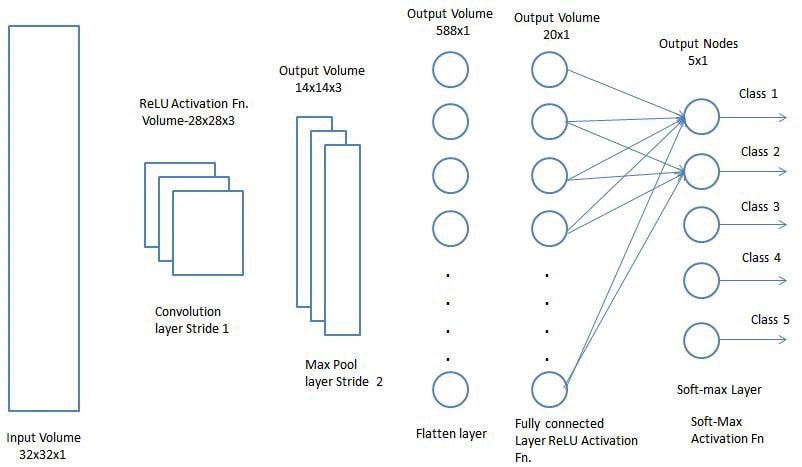
اضافه کردن یک لایه کاملا متصل (Fully-Connected)، یک روش (معمولا) ارزان برای یادگیری ترکیبات غیرخطی از ویژگیهای سطح بالاست که توسط خروجی لایه کانولوشن نمایش داده میشوند. لایه کاملا متصل، یک تابع غیرخطی احتمالی در آن فضا را یاد میگیرد.
اکنون که تصویر ورودی خود را به یک قالب مناسب برای پرسپترون چند سطحیمان تبدیل کردهایم، میتوانیم تصویر را مسطح کرده و به صورت یک بردار ستونی نمایش دهیم. این خروجی مسطح شده، به یک شبکه عصبی پیشخور تحویل داده میشود و در هر تکرار از فرایند آموزش، گسترش رو به عقب (backpropagation) بر روی آن اعمال میشود. پس از طی مجموعهای از مراحل (epochs)، مدل قادر است ویژگیهای غالب (dominating) و ویژگیهای معین سطح پایین را از هم تشخیص داده و با استفاده از تکنیک دستهبندی softmax، آنها را دستهبندی کند.
معماریهای مختلفی برای شبکههای عصبی کانولوشنی وجود دارد که در ساخت الگوریتمهایی که به تقویت هوش مصنوعی در آیندهی نه چندان دور منجر میشوند، نقش کلیدی ایفا میکنند. برخی از آنها عبارتند از:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
در راستای این مقاله، مطالعه مقاله های زیر پیشنهاد میشود:
شبکه عصبی چیست ؟ ___ آشنایی با شبکه های عصبی مصنوعی
شبکه عصبی بازگشتی چیست ؟ آشنایی با شبکههای عصبی بازگشتی (RNN) و (LSTM)
تاریخچه شبکه عصبی و یادگیری عمیق ___ (قسمت اول)
تاریخچه یادگیری عمیق و شبکه عصبی ___ (قسمت دوم)
شبکه های عصبی چیست __ تاریخچه شبکه عصبی و یادگیری ماشین (قسمت سوم)
کلیدواژگان
شبکه عصبی کانولوشنال – شبکه عصبی کانولوشن یا convolutional – ELI5 – شبکه عصبی کانولوشنال چیست – مخفف ELI5 – مخفف ELI5 چیست – شبکه عصبی – شبکه عصبی چیست – شبکه عصبی به زبان ساده – شبکه ی عصبی – شبکه عصبی cnn – شبکه های عصبی چیست – الگوریتم شبکه عصبی – الگوریتم شبکه های عصبی – شبکه های عصبی کانولوشن – شبکه های عصبی کانولوشنی – شبکه های عصبی کانولوشنی (cnn) – شبکه های عصبی کانولوشن (cnn) – شبکه عصبی کانولوشنی – مزیت شبکه کانولوشن – مزیت شبکه عصبی کانولوشنال – مزیت شبکه های کانولوشنی
منبع
a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way
هم رویش منتشر کرده است
-
 آموزش یادگیری ماشین از صفر --- یادگیری سریع و آسان
۶۸,۰۰۰ تومان
آموزش یادگیری ماشین از صفر --- یادگیری سریع و آسان
۶۸,۰۰۰ تومان -
 آموزش تشخیص اشیای اختصاصی با YOLO
۷۵,۰۰۰ تومان
آموزش تشخیص اشیای اختصاصی با YOLO
۷۵,۰۰۰ تومان