چکیده
مدلهای پیشرو در تبدیل دنباله بر اساس شبکههای عصبی عمیق بازگشتی یا کانولوشنی پیچیده ساخته میشوند که شامل یک رمزگذار و یک رمزگشا هستند. بهترین مدلها هم رمزگذار و رمزگشا را از طریق مکانیسم توجه به هم متصل میکنند. ما یک ساختار شبکه جدید و ساده به نام ترنسفورمر (Transformer) را ارائه میدهیم که فقط بر مکانیسمهای توجه (attention mechanisms) استوار است و دیگر از بازگشت و کانولوشن استفاده نمیکند. آزمایشها انجام شده روی دو وظیفه ترجمه ماشینی نشان میدهند که این مدلها علاوه بر برخورداری از کیفیت بالاتر، قابلیت همزمانسازی بیشتری دارند و زمان آموزش را نیز به طور قابلتوجهی کاهش میدهند. مدل ما با دستیافتن به BLEU برابر با ۲۸.۴ در وظیفه ترجمه انگلیسی به آلمانی WMT 2014، عملکرد این کار را نسبت به بهترین نتایج موجود، از جمله نتایج حاصل از مدلهای ترکیبی، بیشتر از 2 BLEU ارتقا میدهد. در وظیفه ترجمه انگلیسی به فرانسوی WMT 2014، مدل ما پس از آموزش ۳.۵ روزه بر روی هشت پردازنده گرافیکی که کسری کوچک از هزینههای آموزشی بهترین مدلهاست، نمره BLEU برتری برابر با ۴۱.۰ کسب کرده است و نمره BLEU برترین مدل تک مدل را در این حوزه تعیین میکند.
مقدمه
شبکههای عصبی بازگشتی (Recurrent neural networks)، حافظه طولانی کوتاهمدت(Long short-term memory (LSTM)) و واحدهای بازگشتی دروازهای(Gated recurrent units(GRU))، به طور خاص بهعنوان رویکردهای پیشرفته در مدلسازی توالی و مشکلات انتقال مانند مدلسازی زبان و ترجمه ماشینی استفاده میشوند. از آن زمان تاکنون، تلاشهای بسیاری برای توسعه مدلهای زبان بازگشتی و معماری رمزگذار – رمزگشا انجام شده است.
معمولاً، در مدلهای بازگشتی، عملیات محاسباتی بر اساس موقعیتهای نمادی دنباله ورودی و خروجی تقسیم میشود. با تطبیق موقعیتها با مراحل زمانی محاسبه، دنبالهای از حالتهای پنهان (ht) بهعنوان تابعی از حالت پنهان قبلی (ht-1) و ورودی در موقعیت t تولید میشود. این رویکرد اجتنابناپذیر باعث میشود که موازیسازی در نمونههای آموزشی مشکل شود که در توالیهای طولانی بسیار مهم است، زیرا محدودیت حافظه منجر به محدودیت در دستهبندی بین نمونهها میشود. تلاشهای اخیر با استفاده از ترفندهای فاکتوریزاسیون و محاسبات شرطی، بهبود قابلتوجهی در کارایی محاسباتی داشتهاند و همچنین بهبود عملکرد مدل در محاسبات نیز رخداده است. بااینحال، محدودیت اصلی محاسبات متوالی همچنان باقی است.
مکانیسمهای توجه بخشی جداییناپذیر از مدلسازی توالی و مدلهای تبدیلی در وظایف مختلف شدهاند و قابلیت مدلسازی وابستگیها را بدون توجه به فاصله آنها در توالی ورودی یا خروجی فراهم میکنند. بااینحال، به جز در تعداد کمی از موارد، این مکانیسمهای توجه با یک شبکه بازگشتی استفاده میشوند.
در این پژوهش، معماری ترنسفورمر را پیشنهاد میدهیم. این مدل از تکرار صرفنظر کرده و بهجای آن از مکانیسم توجه برای برقراری وابستگیهای سراسری بین ورودی و خروجی استفاده میکند. ترنسفورمر قابلیت موازیسازی بسیار بیشتری را فراهم میکند و پس از آموزش تنها در دوازده ساعت روی هشت پردازنده گرافیکی P۱۰۰، توانایی ترجمه باکیفیت بالا را ارائه میدهد.
هم رویش منتشر کرده است:
آموزش اجرای یک پروژه یادگیری ماشین با پایتون
پیشزمینه
هدف دیگر از کاهش محاسبات متوالی، اساساً برای مدلهای Extended Neural GPU، ByteNet و ConvS2S استفاده میشود. این سه مدل از شبکههای عصبی کانولوشنال بهعنوان ساختار اصلی خود استفاده میکنند و حالتهای پنهان را بهصورت موازی برای تمام موقعیتهای ورودی و خروجی محاسبه میکنند. در این مدلها، تعداد عملیات موردنیاز برای ارتباطدادن سیگنالها بین دو موقعیت ورودی یا خروجی دلخواه با افزایش فاصله بین این موقعیتها افزایش مییابد. این افزایش در ConvS2S به طور خطی و در ByteNet به طور لگاریتمی اتفاق میافتد. این موضوع باعث میشود یادگیری وابستگیهای بین موقعیتهای دورتر دشوارتر شود. در مدل ترنسفورمر، این مشکل به تعداد ثابتی از عملیات کاهش مییابد، اگرچه این کاهش به هزینه کاهش وضوح مؤثر به دلیل میانگینگیری موقعیتهای وزندار توجه انجام میشود. بااینحال، با استفاده از توجه چند سر (Multi-Head Attention)، همانطور که در بخشهای بعدی توضیح داده شده است، این تأثیر را متعادل میکنیم.
توجه به خود که گاهی به آن توجه درونی (intra-attention) نیز گفته میشود، یک مکانیسم توجه است که موقعیتهای مختلف یک دنباله تکرشتهای را با یکدیگر مرتبط میکند تا نمایشی از دنباله را محاسبه کند. توجه به خود، با موفقیت در وظایف مختلفی مانند درک مطلب، خلاصهسازی، نتیجهگیری متنی و یادگیری نمایش جملات مستقل از وظیفه، استفاده شده است.
شبکههای حافظه، بهجای تکرار متوالی بر اساس مکانیسم توجه متوالی هستند و ثابت شده است که در پاسخ به سؤالات به زبان ساده و وظایف مدلسازی زبان عملکرد خوبی دارند.
با این حال، تا آنجا که ما میدانیم، ترنسفورمر اولین مدل مبدل است که برای محاسبه نمایشهای ورودی و خروجی خود بدون استفاده از توالیهای RNN یا کانولوشن، کاملاً به مکانیسم توجه به خود متکی است. در بخشهای بعدی، ترنسفورمر را توصیف میکنیم، عملکرد توجه به خود را شرح میدهیم و مزایای آن را نسبت به مدلهای قبلی بررسی میکنیم.
هم رویش منتشر کرده است:
شبکه عصبی کانولوشن به زبان ساده
معماری مدل
بیشتر مدلهای ترجمه مبتنی بر شبکههای عصبی دارای ساختار رمزگذار – رمزگشا هستند. در این ساختار، رمزگذار ورودی را (x1 ,…, xn) به یک نمایش پیوسته z= (z1 ,…, zn) تبدیل میکند و رمزگشا سپس در هر مرحله یک عنصر از خروجی (y1 ,…, yn) را تولید میکند. در این فرایند، مدل بهصورت رگرسیون خودکار عمل میکند و با استفاده از خروجیهای قبلی بهعنوان ورودی اضافی در هر مرحله، خروجی بعدی را تولید میکند.
ترنسفورمر، این ساختار کلی را هم برای رمزگذار و هم برای رمزگشا، با استفاده از توجه به خود پشتهای و لایههای تماماً متصل نقطهبهنقطه، اجرا میکند که به ترتیب در نیمههای چپ و راست شکل ۱ نشاندادهشده است.
پشته های رمزگذار و رمزگشا
رمزگذار: رمزگذار از پشتهای از N = 6 لایه یکسان تشکیل شده است. هر لایه دارای دو زیرلایه است. زیرلایه اول یک مکانیسم توجه به خود چند سر است و زیرلایه دوم یک شبکه پیشخور ساده و کاملاً متصل و موقعیتی است. در هر زیرلایه، از اتصال باقیمانده در اطراف آن استفاده میشود و سپس لایه نرمالسازی انجام میشود. بهعبارتدیگر، خروجی هر زیرلایه برابر است با LayerNorm(x + Sublayer(x)) که در آن Sublayer(x) تابعی است که توسط خود زیرلایه پیادهسازی میشود. به منظور سهولت در اتصالات باقیمانده، تمامی زیرلایهها در مدل و همچنین لایههای تعبیه (Embedding layers)، خروجیهایی با ابعاد dmodel = 512 تولید میکنند.
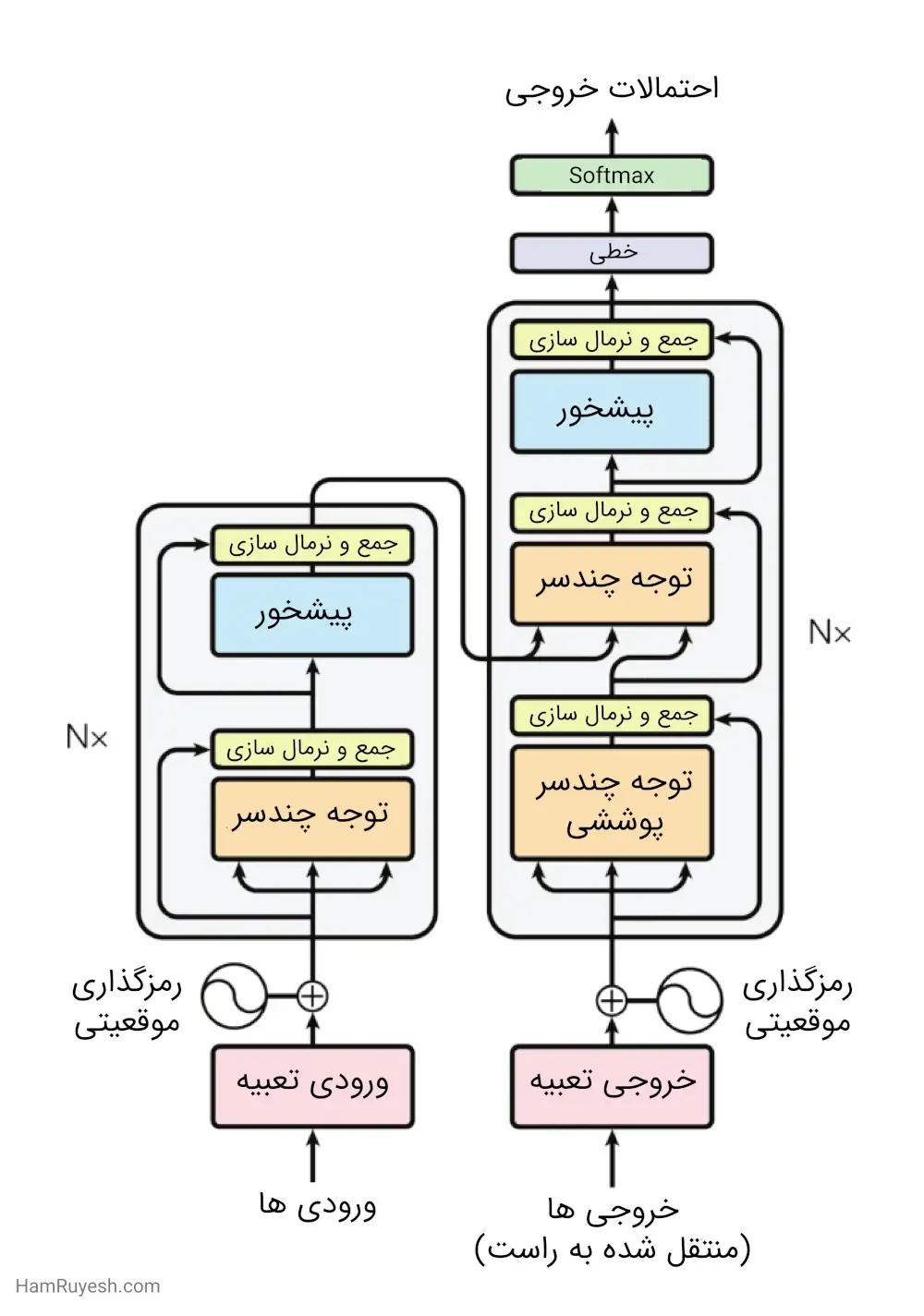
رمزگشا: رمزگشا هم از یک پشته شامل N = 6 لایه یکسان تشکیل شده است. بهعلاوه، در مقایسه با هر لایه رمزگذار، رمزگشا یک زیرلایه سوم را اضافه میکند که توجه چند سر را بر روی خروجی پشته رمزگذار انجام میدهد. مشابه رمزگذار، مدر هر زیرلایه از اتصالات باقیمانده استفاده میکنیم و سپس لایه نرمالسازی را اعمال میکنیم.
همچنین، ما زیرلایه توجه به خود رمزگشا را در پشته قرار میدهیم تا از امکان توجه موقعیتها به موقعیتهای بعدی جلوگیری شود. وجود این پوشش همراه با این واقعیت که نمایشهای خروجی بهاندازه یک موقعیت اختلاف دارند، تضمین میکند که پیشبینیها برای موقعیت i تنها به خروجیهای شناخته شده در موقعیتهای قبل از i وابسته باشند.
توجه
تابع توجه را میتوان بهعنوان نگاشتی از یک پرسش و مجموعهای از جفتهای کلید – مقدار به یک خروجی توصیف کرد، جایی که پرسش، کلیدها، مقادیر و خروجی همگی بردار هستند. خروجی بهعنوان مجموع مقادیر وزندار محاسبه میشود، جایی که وزنی که به هر مقدار اختصاص داده میشود توسط تابع سازگاری پرسش با کلید مربوطه محاسبه میشود.
توجه نقطهای مقیاسدار (Scaled Dot-Product Attention)
ما توجه خاص خود را “توجه نقطهای مقیاس دار” مینامیم (شکل ۲). ورودی از پرسشها و کلیدهایی با ابعاد dk و مقادیری با ابعاد dv تشکیل شده است. ما ضرب نقطهای پرسش را با تمام کلیدها محاسبه کرده، آن را بر تقسیم میکنیم و تابع softmax را بر روی مقادیر اعمال میکنیم تا وزنها را به دست آوریم.
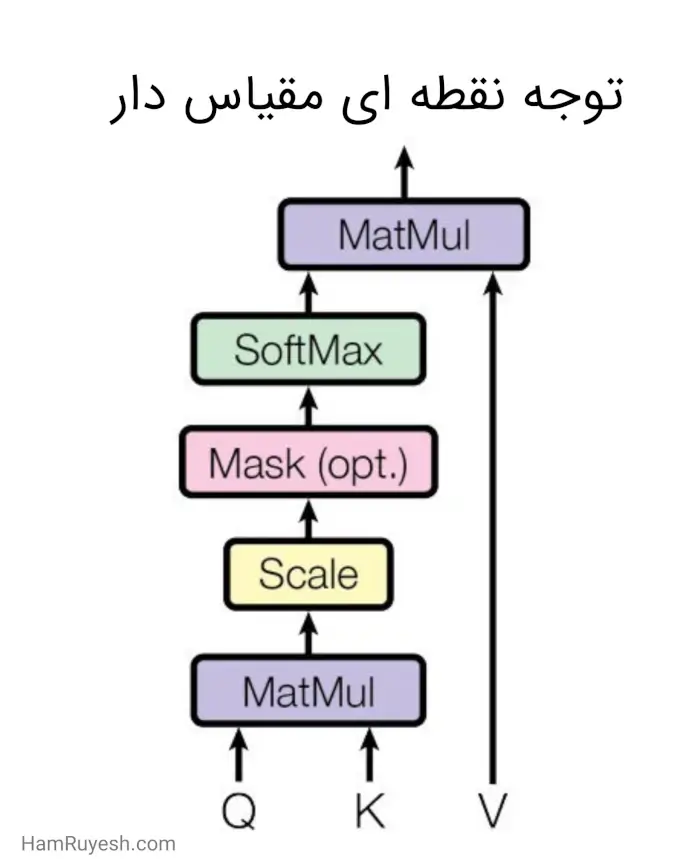
در عمل، ما تابع توجه را بهصورت همزمان بر روی یک مجموعه پرسشها محاسبه میکنیم و آنها را در یک ماتریس Q قرار میدهیم. کلیدها و مقادیر نیز در ماتریسهای K و V قرار میگیرند. ماتریس خروجی را بهصورت زیر محاسبه میکنیم:
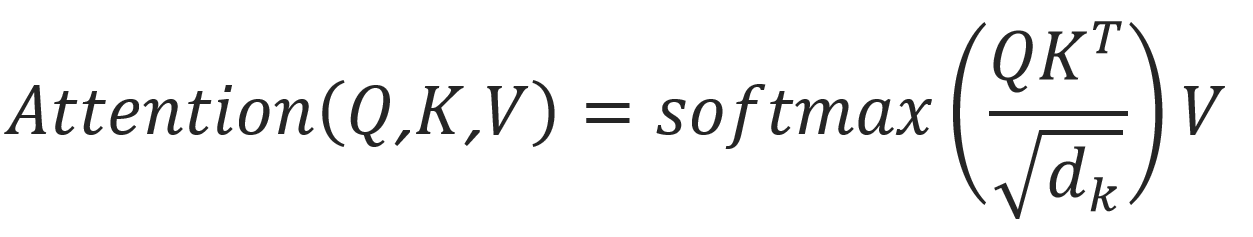
دو تابع توجه که معمولاً مورداستفاده قرار میگیرند عبارتاند از توجه افزایشی و توجه نقطهای (ضربی). بدون درنظرگرفتن ضریب مقیاسبندی ![]() ، توجه نقطهای مطابق با الگوریتم ما است. توجه افزایشی تابع سازگاری را با استفاده از یک شبکه پیشخور با یکلایه پنهان محاسبه میکند. اگرچه این دو تابع در پیچیدگی نظری مشابه هستند، اما توجه نقطهای در عمل سریعتر و بهرهوری فضایی بیشتری دارد، زیرا میتوان از کدهای ضرب ماتریسی بهینهسازی شده برای پیادهسازی آن استفاده کرد.
، توجه نقطهای مطابق با الگوریتم ما است. توجه افزایشی تابع سازگاری را با استفاده از یک شبکه پیشخور با یکلایه پنهان محاسبه میکند. اگرچه این دو تابع در پیچیدگی نظری مشابه هستند، اما توجه نقطهای در عمل سریعتر و بهرهوری فضایی بیشتری دارد، زیرا میتوان از کدهای ضرب ماتریسی بهینهسازی شده برای پیادهسازی آن استفاده کرد.
اگرچه برای مقادیر کوچک dk، این دو مکانیسم به طور مشابه عمل میکنند، اما در مقیاسهای بزرگتر dk، توجه افزایشی عملکرد بهتری نسبت به توجه نقطهای بدون مقیاسبندی دارد. ما حدس میزنیم که برای مقادیر بزرگ dk، ضرب نقطهای از نظر اندازهبزرگ میشود و تابع softmax را به مناطقی میبرد که گرادیانهای بسیار کوچکی دارد (برای توضیح اینکه چرا ضربهای نقطهای بزرگ میشوند، فرض کنید که مولفههای q و k متغیرهای تصادفی مستقل با میانگین ۰ و واریانس ۱ باشند. در این صورت، ضرب نقطهای آنها، 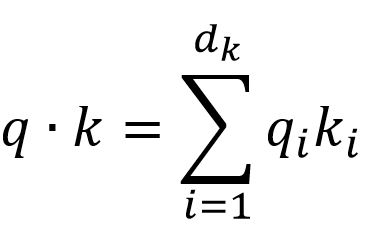 ، میانگین ۰ و واریانس dk دارد.) برای مقابله با این تأثیر، ما ضرب نقطهای را با
، میانگین ۰ و واریانس dk دارد.) برای مقابله با این تأثیر، ما ضرب نقطهای را با ![]() مقیاس میدهیم.
مقیاس میدهیم.
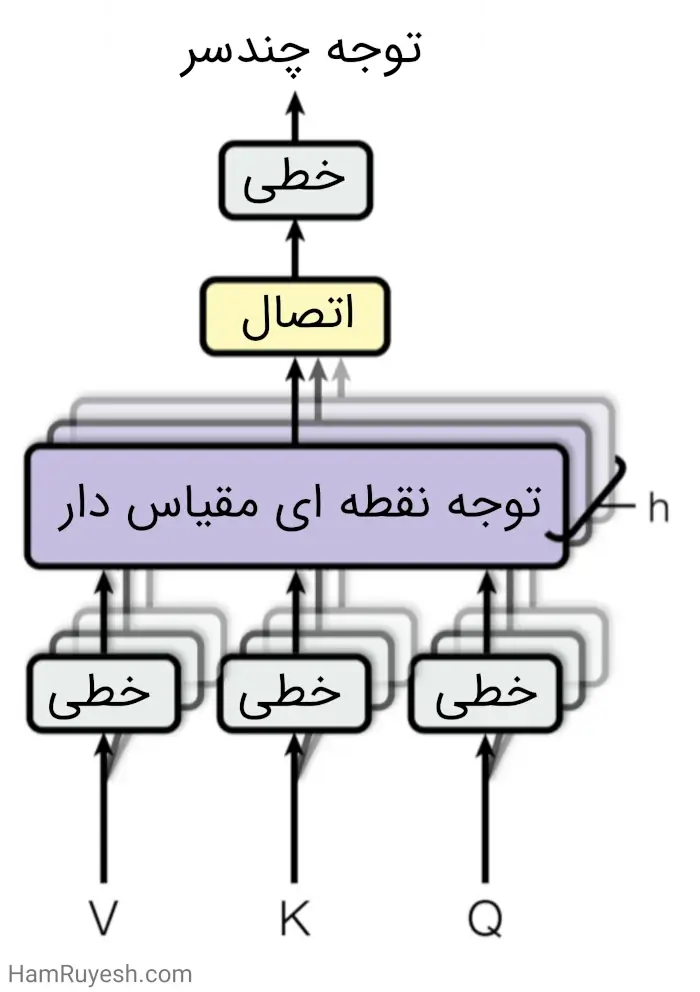
توجه چندسر
در اینجا، بهجای استفاده از یک تابع توجه واحد برای کلیدها، مقادیر و پرسشها با بُعد dmodel، ما متوجه شدیم که بهتر است h بار از تبدیل خطی یادگیری شده و متفاوت برای تبدیل پرسشها، کلیدها و مقادیر به بُعدهای dk، dk و dv استفاده کنیم. سپس بر روی هر یک از این نسخههای جدید از پرسشها، کلیدها و مقادیر، بهصورت موازی تابع توجه را اجرا کرده و مقادیر خروجی با بُعد dv به دست میآید. این مقادیر بههمپیوسته و دوباره تبدیل خطی میشوند و نتیجهای بهعنوان مقادیر نهایی به دست میآید که در شکل ۳ نمایشدادهشده است.
استفاده از توجه چندسر، به مدل امکان میدهد که به طور همزمان به اطلاعات از زیر فضاهای نمایش مختلف و در موقعیتهای مختلف توجه کند. این امکان با استفاده از یک تابع توجه تکسر از بین میرود، زیرا میانگینگیری صورت میگیرد.
![]()
به طوریکه![]()
جایی که تبدیلهای خطی، ماتریس های پارامتر ها زیر هستند:
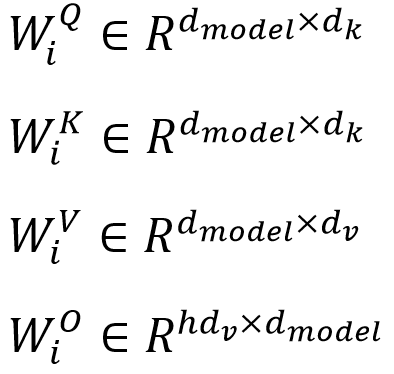
در این کار، ما h = 8 سر توجه موازی با بُعد dk = dv = dmodel= h = 64 استفاده میکنیم. به دلیل کاهش بُعد هر سر، هزینه محاسباتی کلی، مشابه هزینه توجه تکسر با بُعد کامل است.
کاربردهای توجه در مدل ما
در ترنسفورمر، توجه چند سر را به سه روش مختلف استفاده میکنیم:
- در لایههای “توجه رمزگذار – رمزگشا”، پرسشها را از لایه قبلی رمزگشا میگیریم و کلیدها و مقادیر حافظه را از خروجی رمزگذار دریافت میکنیم. بدین ترتیب هر موقعیت در رمزگشا به تمام موقعیتها در دنباله ورودی توجه میکند. این عملکرد شبیه به مکانیسم توجه رمزگذار – رمزگشا در مدلهای توالی بهتوالی است.
- رمزگذار شامل لایههای توجه به خود است. در هر لایه توجه به خود، همه کلیدها، مقادیر و پرسشها از یک مکان یکسان میآیند. در این حالت، منظور از خروجی، لایه قبلی رمزگذار است. هر موقعیت در رمزگذار میتواند به تمام موقعیتها در لایه قبلی رمزگذار توجه کند.
- به طور مشابه، لایههای توجه به خود در رمزگشا امکان میدهند تا هر موقعیت در رمزگشا به تمام موقعیتها در رمزگشا، یعنی از موقعیتهای قبل تا خود موقعیت مدنظر، توجه کند. برای حفظ خاصیت رگرسیون خودکار، نیاز است جریان اطلاعات به سمت چپ را در رمزگشا متوقف کنیم. این کار را در داخل توجه نقطهای مقیاس دار با پوشاندن (تنظیم به منفی بینهایت) تمام مقادیر ورودی تابع softmax که متناظر با اتصالات غیرقانونی هستند، انجام میدهیم. شکل ۳ را مشاهده کنید.
شبکههای پیشخور موقعیتی (Position-wise Feed-Forward Networks)
علاوه بر زیرلایههای توجه، هر یک از لایه از رمزگذار و رمزگشای ما شامل یک شبکه پیشخور کاملاً متصل است که بهصورت جداگانه و یکسان برای هر موقعیت اعمال میشود. این شبکه شامل دو تبدیل خطی با یک فعالسازی ReLU میان آنها است.
![]()
اگرچه تبدیلهای خطی در موقعیتهای مختلف یکسان هستند، اما از پارامترهای مختلفی در لایههای مختلف استفاده میکنند. روش دیگر برای ایجاد این شبکه، قراردادن دو کانولوشن با اندازه هسته ۱ است. ابعاد ورودی و خروجی برابر با dmodel=۵۱۲ است و ابعاد لایه داخلی برابر با dff=۲۰۴۸ است.
تعبیه و Softmax
به طور مشابه با سایر مدلهای تبدیل دنباله، از تعبیههای آموختهشده برای تبدیل نمادهای ورودی و نمادهای خروجی به بردارهای با ابعاد dmodel استفاده میکنیم. همچنین از تبدیل خطی یادگرفته شده و تابع softmax برای تبدیل خروجی رمزگشا به احتمالات بعدی پیشبینیشده استفاده میکنیم. در مدل ما، ماتریس وزن یکسانی بین دولایه تعبیه شده و تبدیل خطی قبل از softmax را به اشتراک میگذاریم. این وزنها را در لایههای تعبیه، در ضرب میکنیم.
رمزگذاری موقعیتی (Positional Encoding)
باتوجهبه اینکه مدل ما شامل هیچگونه بازگشت یا کانولوشنی نیست، برای استفاده از ترتیب دنباله، باید اطلاعاتی درباره موقعیت نسبی یا مطلق نمادها در دنباله در مدل درج کنیم. به این منظور، ما “رمزگذاری موقعیتی” را به تعبیههای ورودی در پشتههای رمزگذار و رمزگشا اضافه میکنیم. رمزگذاری موقعیتی ابعاد مشابهی با تعبیههای ورودی دارند (dmodel)، بنابراین میتوان آنها را با هم جمع کرد. روشهای متعددی برای رمزگذاری موقعیتی وجود دارد، شامل روشهای یادگیری شده و ثابت.

برای رمزگذاری موقعیتی در این کار، از توابع سینوسی و کوسینوسی با فرکانسهای مختلف استفاده میکنیم:
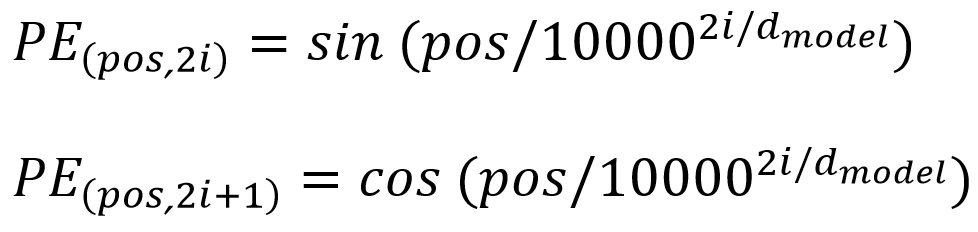
در اینجا pos نشان دهنده موقعیت و i نشانگر ابعاد است. به عبارت دیگر، هر بعد از رمزگذاری موقعیتی متناظر با یک فرکانس سینوسی است. طول موج ها از∏2 تا 1000∙∏2 یک توالی هندسی تشکیل می دهند. علت انتخاب این تابع این است که فرض کردیم این امکان را به مدل می دهد که به راحتی حضور در موقعیتهای نسبی را یاد بگیرد، زیرا برای هر انتقال ثابت k، می توان PE(pos+k) را به عنوان یک تابع خطی از PE(posi) نمایش داد.
ما همچنین استفاده از تعبیههای موقعیتی آموخته شده را آزمایش کردیم و متوجه شدیم که دو نسخه نتایج تقریباً یکسانی تولید میکنند (جدول ۳، سطر E را ببینید). ما نسخه سینوسی را انتخاب کردیم؛ زیرا این امکان را به مدل میدهد که طولهای توالی بیشتر از آنکه در طول آموزش با آنها مواجه میشود را نیز برونیابی کند.
علت استفاده از توجه به خود
در این بخش، ما لایههای توجه به خود را با لایههای بازگشتی و کانولوشنی که معمولاً برای نگاشت دنبالههایی با طول متغیر (x1 ,…, xn) به دنبالههایی با طول ثابت (z1 ,…, zn) استفاده میشوند، در یک رمزگذار یا رمزگشای تبدیل توالی معمولی مقایسه میکنیم. باتوجهبه استفاده ما از توجه به خود، سه مورد را در نظر میگیریم.
اولین مورد، پیچیدگی محاسباتی کل در هر لایه است. دومین مورد، قابلیت موازیسازی محاسباتی است که با حداقل تعداد عملیات متوالی انجام میشود.
مورد سوم، مسیریابی بین وابستگیهای دوربرد در شبکه است. یادگیری وابستگیهای دوربرد یک چالش کلیدی در بسیاری از وظایف تبدیل دنبالهها است. یکی از عوامل کلیدی که بر توانایی یادگیری اینگونه وابستگیها تأثیر میگذارد، طول مسیرهایی است که سیگنالهای روبهجلو و عقب در شبکه باید طی کنند. هرچه این مسیرهای بین هر ترکیب موقعیت در دنباله ورودی و خروجی کوتاهتر باشد، یادگیری وابستگیهای دوربرد آسانتر است؛ بنابراین ما حداکثر طول مسیر بین هر دو موقعیت ورودی و خروجی را در شبکههایی که از انواع لایههای مختلف تشکیل شدهاند را نیز مقایسه میکنیم.
همانطور که در جدول ۱ ذکر شده است، لایه توجه به خود باعث اتصال همه موقعیتها با تعداد ثابتی از عملیات متوالی میشود. این در حالی است که لایه بازگشتی نیاز به O(n) عملیات متوالی دارد. از نظر پیچیدگی محاسباتی، درصورتیکه طول دنباله n کمتر از ابعاد نمایشی d باشد، لایههای توجه به خود سریعتر از لایههای بازگشتی هستند. این امر اغلب در مواردی که مدلهای پیشرفته در ترجمههای ماشینی استفاده میشوند، مانند تکههای کلمه و بایت – جفت، صدق میکند.
برای بهبود عملکرد محاسباتی در کارهایی که دنبالههای بسیار طولانی در آنها وجود دارد، میتوان توجه به خود را محدود به همسایگی با اندازه r در دنباله ورودی کرد که حول موقعیت خروجی مربوطه تمرکز دارد. این کار باعث افزایش حداکثر طول مسیر به O(n/r) میشود. در کارهای آینده قصد داریم این رویکرد را بیشتر بررسی کنیم.
لایه تکی کانولوشن با عرض هسته k < n کل جفت موقعیتهای ورودی و خروجی را به هم متصل نمیکند. برای انجام این کار، نیاز به پشتهای از لایههای کانولوشن به تعداد O(n/r) برای هستههای بههمپیوسته یا O(logk(n)) برای کانولوشنهای پراکنده است که طول مسیرهای بلندتری بین هر دو موقعیت در شبکه ایجاد میکند. با اینحال، لایههای کانولوشن معمولاً با ضریب k پرهزینهتر از لایههای بازگشتی هستند. اما، کانولوشنهای قابلجداسازی باعث کاهش قابلتوجهی در پیچیدگی محاسباتی به O(k∙n∙d+n∙d2) میشوند. بااینحال، حتی با k = n، پیچیدگی یک کانولوشن معادل ترکیب یکلایه توجه به خود و یکلایه پیشخور نقطهای است که ما در مدل انجام میدهیم.
به علاوه، توجه به خود ممکن است مدلهای قابل تفسیرتری را نیز به ارمغان بیاورد. ما توزیعهای توجه از مدلهای خودمان را بررسی کرده و نمونهها را در پیوست ارائه و بررسی میکنیم. نهتنها هر سر توجه بهوضوح یاد میگیرد که وظایف مختلفی را انجام دهد، بلکه به نظر میرسد بسیاری از آنها رفتارهایی مرتبط با ساختار نحوی و معنایی جملات را نشان میدهند.
علاوه بر این، توجه به خود میتواند مدلهای قابل تفسیرتری را فراهم کند. ما توزیعهای توجه از مدلهای خود را بررسی کرده و نمونهها را در پیوست ارائه و بررسی میکنیم. هر سر توجه نهتنها یاد میگیرد که وظایف مختلفی را انجام دهد، بلکه به نظر میرسد بسیاری از آنها رفتارهایی مرتبط با ساختار نحوی و معنایی جملات را نشان میدهند.
آموزش
در این بخش، قوانین آموزش مدلهای ما شرح داده شده است.
داده های آموزشی و دسته بندی
ما آموزش را بر روی مجموعهداده انگلیسی – آلمانی WMT 2014 انجام دادیم. این مجموعه شامل حدود ۴.۵ میلیون جفت جمله است. برای رمزگذاری جملات، از رمزگذاری بایت – جفت استفاده کردهایم و تعداد واژگان مشترک منبع – هدف حدوداً ۳۷,۰۰۰ نماد است. برای زبان انگلیسی – فرانسوی، ما از مجموعهداده بزرگتر انگلیسی – فرانسوی WMT 2014 با ۳۶ میلیون جمله و ۳۲,۰۰۰ تکه کلمه واژگان استفاده کردیم. جفت جملهها بر اساس طول توالی به دستههای آموزشی تقسیم شدند. هر دسته آموزشی شامل یک مجموعه جفت جمله است که دارای تقریباً ۲۵,۰۰۰ نماد منبع و ۲۵,۰۰۰ نماد هدف است.
سختافزار و برنامهزمانی
مدلهای خود را روی یک دستگاه با ۸ پردازنده گرافیکی NVIDIA P100 آموزش دادیم. برای مدلهای پایه، هر مرحله آموزشی حدود ۰.۴ ثانیه طول میکشد و از فراپارامترهای مشخص شده در مقاله استفاده شده است. مدلهای پایه را به مجموع ۱۰۰,۰۰۰ مرحله یا ۱۲ ساعت آموزش دادیم. برای مدلهای بزرگ (همانطور که در خط آخر جدول ۳ توضیح داده شده است)، زمان هر مرحله ۱.۰ ثانیه بود. مدلهای بزرگ را برای ۳۰۰,۰۰۰ مرحله (۳.۵ روز) آموزش دادیم.
بهینهساز (Optimizer)
در اینجا از الگوریتم بهینهساز Adam با پارامترهای β1 = 0.9، β2 = 0.98 و ε = 10-9 استفاده کردهایم. نرخ یادگیری در طول دورهی آموزش با استفاده از فرمول زیر تغییر میکند:
![]()
در این فرمول، نرخ یادگیری در ابتدا به صورت خطی با افزایش warmup_steps افزایش مییابد و سپس به نسبت معکوس جذر گام کاهش مییابد. ما از warmup_steps = 4000 استفاده کردهایم.
نظم دهی (Regularization)
در طول آموزش، از سه روش نظمدهی استفاده میکنیم:
اعمال Dropout اضافی: ما Dropout را بر روی خروجی هر زیرلایه قبل از اضافه شدن به ورودی زیرلایه و نرمالسازی آن اعمال میکنیم. همچنین، Dropout را بر روی جمع تعبیهها و رمزگذاریهای موقعیتی در هر دو پشته رمزگذار و رمزگشا نیز اعمال میکنیم. برای مدل پایه، از نرخ Pdrop=0.1 استفاده میکنیم.
Label Smoothing : در طول آموزش، ما از Label Smoothing با مقدار ls = 0.1 استفاده کردهایم. این کار باعث کاهش پیچیدگی میشود، زیرا مدل یاد میگیرد که عدم اطمینان بیشتری کار کند، اما دقت و امتیاز BLEU را بهبود میبخشد.
نتایج
ترجمه ماشینی
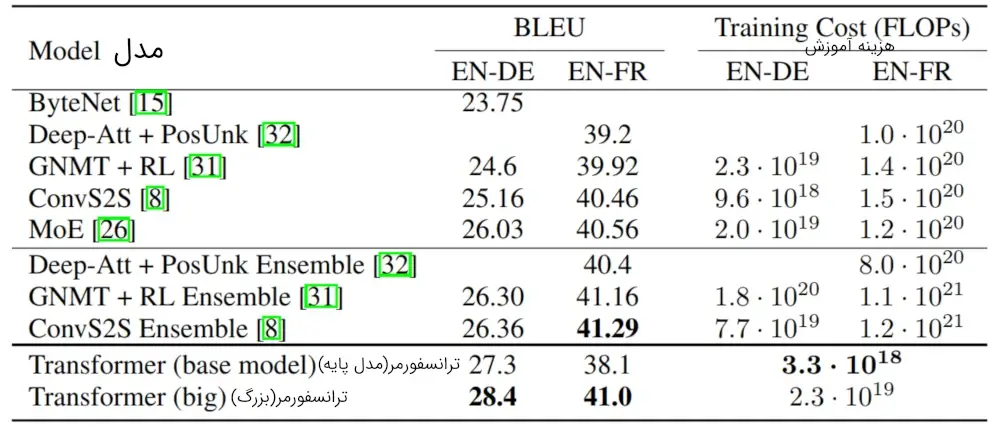
در وظیفه ترجمه متن انگلیسی به آلمانی با استفاده از مجموعهداده WMT 2014، مدل ترنسفورمر بزرگ (مورد نمونه در جدول ۲) نسبت به بهترین مدلهای گزارش شده تا قبل از آن (شامل مدلهای ترکیبی)، با افزایش بیش از ۲.۰ امتیاز BLEU، بهبود یافت و به امتیاز BLEU جدیدی برابر با ۲۸.۴ دستیافت. جزئیات پیکربندی این مدل در خط پایین جدول ۳ آورده شده است. آموزش این مدل به مدت ۳.۵ روز روی ۸ کارت گرافیک P۱۰۰ طول کشید. حتی مدل پایه ما، با هزینه آموزش کمتر از تمام مدلهای رقابتی قبلی، بهبود قابلتوجهی نسبت به آنها داشت و بهعنوان مدل برتر منتشر شده قبلی شناخته شد.
در وظیفه ترجمه متن انگلیسی به فرانسوی با استفاده از مجموعهداده WMT 2014، مدل بزرگ ما به امتیاز BLEU معادل با ۴۱.۰ رسید و بهبود قابلتوجهی را نسبت به همهٔ مدلهای تکی منتشر شده قبلی با هزینه آموزشی کمتر از ۱/۴ مدل برتر قبلی به دست آورد. مدل ترنسفورمر بزرگ برای ترجمه انگلیسی به فرانسوی از نرخ Dropout برابر با ۰.۱ بهجای ۰.۳ استفاده کرد.
برای مدلهای پایه، ما از مدل تکی استفاده کردیم که با میانگینگیری از ۵ نقطه آخر که بافاصله زمانی ۱۰ دقیقه نوشته شده بودند، بهدستآمده است. برای مدلهای بزرگ، از میانگین آخرین ۲۰ نقطه استفاده کردیم. از الگوریتم جستجوی شعاعی (Beam search) با عرض ۴ و طول خطا α = ۰.۶ استفاده کردیم. فراپارامترهای ذکر شده پس از آزمایشهایی در مجموعه توسعه انتخاب شدهاند. حداکثر طول خروجی در زمان استنباط را برابر با طول ورودی + ۵۰ قرار دادیم، اما در صورت امکان، فرایند را زودتر پایان میدهیم.
جدول ۲ خلاصهای از نتایج ما را نشان میدهد و کیفیت ترجمه و هزینههای آموزش ما را با ساختارهای مدل دیگری که در مقالات دیگر وجود دارد، مقایسه میکند. ما تعداد عملیات اعشاری مورداستفاده برای آموزش یک مدل را با ضرب زمان آموزش، تعداد پردازندههای گرافیکی استفاده شده و تخمینی از ظرفیت پایدار اعشاری بادقت واحد هر پردازنده گرافیکی (ما از مقادیر ۲.۸، ۳.۷، ۶.۰ و 9.5 TFLOPS به ترتیب برای K۸۰، K40، M40 و P۱۰۰ استفاده کردیم)، محاسبه میکنیم.
تغییرات مدل
برای ارزیابی اهمیت اجزای مختلف ترنسفورمر، مدل پایه خود را به روشهای مختلفی تغییر دادیم و تغییر در عملکرد ترجمه انگلیسی به آلمانی را در مجموعه توسعه، یعنی newstest2013، اندازهگیری کردیم. همانطور که در بخش قبل توضیح داده شد از جستجوی شعاعی، استفاده کردیم، اما میانگینگیری نقطه آزمایش انجام نشد. نتایج این تغییرات را در جدول ۳ مشاهده میکنید.
در سطرهای جدول ۳ (A)، تعداد سرهای توجه و کلیدهای توجه و ابعاد مقدار را تغییر دادیم و مقدار محاسبات را، همانطور که گفته شد، ثابت نگه داشتیم. درحالیکه توجه تکسر به نسبت بهترین حالت، 0.9 BLEU کمتر است، کیفیت نیز با افزایش سرهای توجه کاهش مییابد.
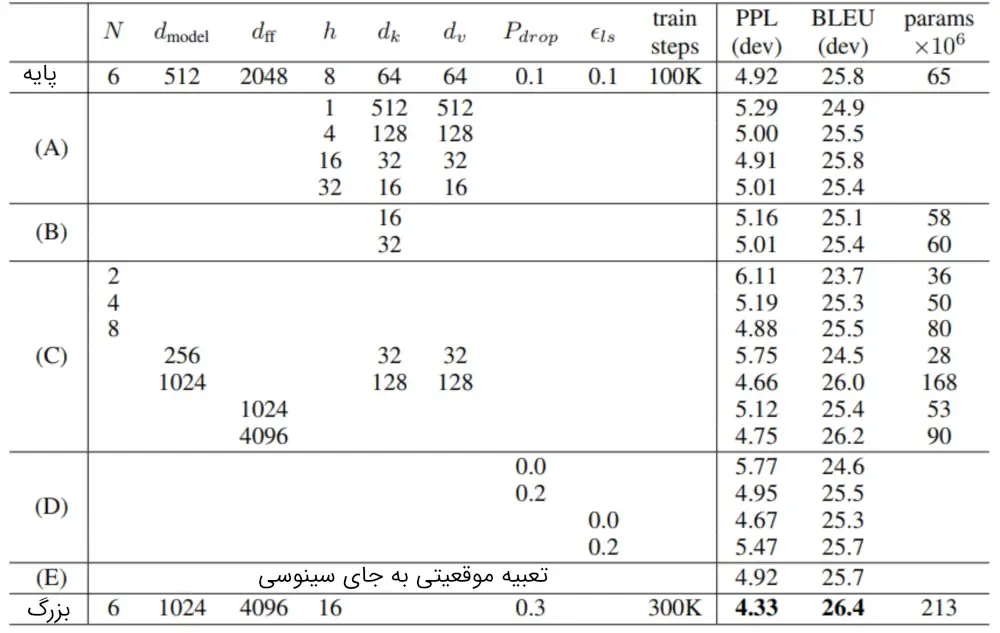
در سطرهای جدول ۳ (B)، مشاهده میشود که کاهش اندازه کلید توجه (dk) کیفیت مدل را ضعیف میکند. این نشان میدهد که تعیین سازگاری آسان نیست و استفاده از یک تابع سازگاری پیشرفتهتر از ضرب نقطهای میتواند مفید باشد. همچنین، در سطرهای (C) و (D) مشاهده میشود که همانطور که انتظار میرفت، مدلهای بزرگتر بهتر عمل میکنند و استفاده از Dropout بسیار مفید است تا از بیش برازش (overfitting) جلوگیری شود. در سطر (E)، رمزگذاری موقعیتی سینوسی با تعبیههای موقعیتی یادگرفته شده جایگزین میشود و نتایج تقریباً مشابه مدل پایه به دست میآید.
نتیجهگیری
در این پژوهش، ما مدل ترنسفورمر را معرفی کردیم؛ اولین مدلی که به طور کامل بر اساس توجه طراحی شده است و لایههای بازگشتی که بیشترین استفاده را در معماری رمزگذار – رمزگشا دارند را باتوجهبه خود چند سر جایگزین کرده است.
برای وظایف ترجمه، ترنسفورمر قابلیت آموزش با سرعت قابلتوجهی نسبت به معماریهای بر اساس لایههای بازگشتی یا کانولوشنی را دارد. در دو وظیفه ترجمه انگلیسی به آلمانی WMT 2014 و ترجمه انگلیسی به فرانسوی WMT 2014، به پیشرفتهای قابلتوجهی دستیافتهایم. در وظیفه اول، بهترین مدل ما حتی عملکرد بهتری نسبت بهتمامی مدلهای قبلی گزارش شده، داشته است.
ما درباره آینده مدلهای مبتنی بر توجه هیجانزدهایم و قصد داریم آنها را در وظایف دیگری نیز به کار ببریم. همچنین، قصد داریم ترنسفورمر را برای مسائلی که ورودی و خروجی آنها غیر از متن هستند، توسعه دهیم و مکانیسمهای توجه محدود محلی را بررسی کنیم تا بتوانیم بهصورت بهینه ورودی و خروجیهای بزرگی مانند تصاویر، صدا و ویدئو را کنترل کنیم. کاهش طول توالی در فرایند تولید، هدف دیگری از تحقیقات ما است.
کدی که برای آموزش و ارزیابی مدلهای خود استفاده کردیم در آدرس https://github.com/tensorflow/tensor2tensor در دسترس است.
کلیدواژگان
ترنسفورمر چیست| لایه رمزگذاری موقعیتی| Positional encoding| Transformer چیست؟| مدل Transformer| Transformer چیست| مدل ترنسفورمر| Transformer Model |مدل انتقالی|مدل های مبتنی بر Transformer| Transformer در هوش مصنوعی| Natural language processing|پردازش زبان طبیعی| NLP با ترنسفورمر در پایتون| ترنسفورمر ها در ترجمه ماشینی| مدل زبانی در هوش مصنوعی| Language model در AI|مکانیزم توجه| مکانسیم توجه در یادگیری عمیق| توجه در یادگیری ماشین| مکانیزم اتنشن| مکانیزم های توجه| شبکه های توجه| مکانیسم توجه و ترنسفورمر|attention چیست| شبکه های عصبی مبتنی بر توجه| مکانیزم attention |attention در شبکه عصبی| Attention mechanism |self-attention| مدل رمزگذار رمزگشا چیست|دنباله به دنباله|انکودر دیکودر|ساختار رمزگذار رمزگشا| شبکه عمیق رمزگذار رمزگشا|معماری رمزگذار رمزگشا| شبکه عصبی رمزگذار رمزگشا|مدل Encoder-Decoder|رمزگذاری موقعیتی در ترنسفورمر|رمزگذاری موقعیتی و ترنسفورمر| رمزگذاری موقعیتی چیست|رمزگذاری کلمات





