یادگیری عمیق به مدلهای محاسباتی که از لایههای پردازشی متعدد تشکیل شدهاند اجازه میدهد تا نمایش دادهها را با سطوح انتزاعی متعدد بیاموزند. این روشها به طور چشمگیری پیشرفتهترین فناوریها را در تشخیص گفتار، تشخیص بصری اشیا و بسیاری از حوزههای دیگر مانند کشف دارو و ژن بهبود بخشیدهاند.
یادگیری عمیق با استفاده از الگوریتم انتشار روبهعقب خطاها که بهاختصار “پس انتشار“backpropagation algorithm) ) نامیده میشود، ساختار پیچیدهای را در مجموعههای بزرگی از دادهها کشف میکند. این الگوریتم به ما نشان میدهد که چگونه ماشین ها باید پارامترهای داخلی که برای محاسبه بازنمایی هر لایه که درلایه قبل از آن استفاده میشد را تغییر دهند.
شبکههای کانولوشن عمیق (DCNN)، پیشرفتهای قابلتوجهی در پردازش تصاویر، ویدئو، گفتار و صدا به ارمغان آوردهاند، درحالیکه شبکههای عصبی بازگشتی (RNN)، مانند نوری به دادههای متوالی همچون متن و گفتار تابیدهاند. بهعبارتدیگر، این شبکهها به ما در درک و تحلیل این نوع دادهها مانند جملات در متن و کلمات در گفتار، کمک میکنند.
یادگیری ماشین (machine learning)
فنّاوری یادگیری ماشین بخشهای مختلفی از جامعه مدرن را تقویت میکند: از جستجوهای وب گرفته تا فیلترینگ محتوا در شبکههای اجتماعی. از پیشنهادها در وبسایتهای تجارت الکترونیک، و در حال حاضر به طور فزایندهای در محصولات مصرفی؛ مانند دوربینها و تلفنهای هوشمند حضور دارد.
دستگاههای یادگیری ماشین برای شناسایی اشیا در تصاویر، تبدیل گفتار به متن، تطبیق خبرها، پستها یا محصولات بر اساس علایق کاربران و انتخاب نتایج مرتبط با جستجو استفاده میشود. در حال حاضر، این برنامهها بیشتر و بیشتر از یک دسته از تکنیکها به نام یادگیری عمیق استفاده میکنند.
تکنیکهای متداول و سنتی یادگیری ماشین در توانایی پردازش دادههای طبیعی در شکل خام خود محدود بودند. برای دههها، برای ساختن یک سیستم تشخیص الگو یا یادگیری ماشین نیاز به مهندسی دقیق و تخصص قابلتوجهی بود. تا یک استخراجکننده ویژگی طراحی شود که دادههای خام (مانند مقادیر پیکسلهای یک تصویر) را به یک نمایش داخلی مناسب یا بردار ویژگی تبدیل کند. از این بردار ویژگی، زیرسیستم یادگیری که اغلب یک طبقهبندی کننده است، میتواند الگوها را در ورودی تشخیص دهد یا طبقهبندی کند.
یادگیری بازنمایی (Representation learning)، مجموعهای از روشهاست که به ماشین اجازه میدهد با دادههای خام تغذیه شود. پیرو آن ماشین به طور خودکارنمایشهای موردنیاز برای تشخیص یا طبقهبندی را کشف می کند. روشهای یادگیری عمیق، روشهای یادگیری – بازنمایی با چندین سطح نمایش هستند. آنها ترکیب ماژولهای ساده اما غیرخطی که هر یک نمایشها را در یک سطح (شروع با ورودی خام) به نمایشی در سطح بالاتر و کمی انتزاعیتر تبدیل میکنند. با ترکیب کافی از این نوع تبدیلها، میتوان توابع بسیار پیچیده را یاد گرفت.
برای انجام طبقهبندی، لایههای بالاتر نمایش، جنبههایی از ورودی را تقویت میکنند که برای تمایز مهم هستند و تغییرات غیرمرتبط را کاهش میدهد. برای مثال، یک تصویر بهصورت آرایهای از مقادیر پیکسل است و ویژگیهای یادگرفته شده در اولین لایه نمایش معمولاً حضور یا عدم حضور لبهها در جهتها و مکانهای خاص در تصویر را نشان میدهد.
لایه دوم به طور معمول الگوها را با تشخیص ترتیبهای خاصی از لبهها شناسایی میکند، بدون درنظرگرفتن تغییرات کوچک در موقعیت لبهها.
لایه سوم الگوها را به ترکیبهای بزرگتری تبدیل میکند که با بخشهایی از اشیا آشنا مطابقت دارند و لایههای بعدی اشیا را بهعنوان ترکیبی از این بخشها شناسایی میکنند. جنبه کلیدی
یادگیری عمیق این است که این لایههای ویژگیها توسط مهندسان انسانی طراحی نشدهاند. آنها از دادهها با استفاده از یک روش یادگیری همهمنظوره و عمومی یاد گرفته میشوند.
یادگیری عمیق در حل مشکلاتی که برای سالها در برابر بهترین تلاشهای جامعه هوش مصنوعی مقاومت کردهاند، پیشرفتهای قابلتوجهی داده است. این روش در کشف ساختارهای پیچیدهای با ابعاد بالا عملکرد خوبی دارد و بنابراین در بسیاری از حوزههای علم، تجارت و دولت قابلاستفاده است.
علاوه بر شکستن رکوردها در تشخیص تصویر و تشخیص گفتار، در پیشبینی فعالیت مولکولهای دارویی بالقوه، تجزیهوتحلیل دادههای شتابدهنده ذرات، بازسازی مدارهای مغزی و پیشبینی اثرات جهشها در DNA غیر کدگذاری شده بر بیان ژن و بیماری، سایر تکنیکهای یادگیری ماشین را شکست داده است.
شاید تعجبآورتر این باشد که یادگیری عمیق نتایج بسیار امیدوارکنندهای در وظایف مختلف برای درک زبان طبیعی، بهویژه طبقهبندی موضوع، تجزیهوتحلیل احساسات، پاسخ به سؤالات و ترجمه زبان را به ارمغان آورده است.
ما فکر میکنیم که یادگیری عمیق در آینده نزدیک موفقیتهای بسیار بیشتری خواهد داشت. زیرا نیاز به انجام محسبات دستی کمی دارد، بنابراین بهراحتی میتواند از افزایش تعداد محاسبات و دادههای موجود بهرهبرداری کند. الگوریتمها و معماریهای جدید یادگیری که در حال حاضر برای شبکههای عصبی عمیق درحالتوسعه هستند، باعث افزایش سرعت این فرایند خواهند شد.
هم رویش منتشر کرده است:
آموزش یادگیری ماشین از صفر — یادگیری سریع و آسان
یادگیری نظارت شده (Supervised learning)
رایجترین شکل یادگیری ماشین، چه عمیق و چه غیر عمیق، یادگیری نظارت شده است. تصور کنید که میخواهیم سیستمی بسازیم که بتواند تصاویر را بهعنوانمثال شامل یکخانه، یک ماشین، یک شخص یا یک حیوان خانگی دستهبندی کند. ما ابتدا یک مجموعهای بزرگ از تصاویر خانهها، ماشینها، افراد و حیوانات خانگی را جمعآوری میکنیم که هر کدام با دستهبندی خود برچسبگذاری شدهاند.
در طول آموزش، تصویری به دستگاه نشان داده میشود و خروجی را بهصورت یک بردار امتیازات، یکی برای هر دسته، تولید میکند. ما میخواهیم دسته موردنظر بالاترین امتیاز را از همه دستهها داشته باشد، اما این اتفاق احتمالاً قبل از آموزش رخ نمیدهد.
ما یک تابع هدف محاسبه میکنیم که خطا (یا فاصله) بین امتیازات خروجی و الگوی موردنظر امتیازات را اندازهگیری میکند. سپس ماشین پارامترهای تنظیمپذیر داخلی خود را برای کاهش این خطا تغییر میدهد. این پارامترهای تنظیمپذیر که اغلب وزنها (weights) نامیده میشوند، اعداد حقیقی هستند. که میتوان آنها را بهعنوان ‘دستهبندیها’ در نظر گرفت که تابع ورودی – خروجی ماشین را تعریف میکنند. در یک سیستم یادگیری عمیق معمولی، ممکن است صدها میلیون از این وزنهای قابلتنظیم و صدها میلیون نمونه برچسبگذاری شده برای آموزش ماشین وجود داشته باشد.
برای تنظیم صحیح بردار وزن، الگوریتم یادگیری یک بردار گرادیان محاسبه میکند. این بردار برای هر وزن، نشان میدهد که اگر وزن به مقدار کمی افزایش یابد، خطا تا چه میزان افزایش یا کاهش مییابد. سپس بردار وزن در جهت مخالف بردار گرادیان تنظیم می شود.
تابع هدف، به طور میانگین در تمام نمونههای آموزشی، میتواند بهعنوان نوعی منظره تپهای در فضای با ابعاد بالا از مقادیر وزنی دیده میشود. بردار گرادیان منفی جهت شیبدارترین نزول را در این منظر نشان میدهد و آن را به حداقل نزدیک میکند، جایی که خطای خروجی به طور میانگین کم است.
در عمل، بیشتر تمرینکنندگان از روشی به نام نزول گرادیان تصادفی (stochastic gradient descent) استفاده میکنند. این شامل نمایش بردار ورودی برای چند نمونه، محاسبه خروجیها و خطاها، محاسبه گرادیان متوسط برای آن نمونهها و تنظیم وزنها بهمنظور تطابق با آنها است. این فرایند برای بسیاری از مجموعههای کوچکی از نمونههای مجموعه آموزشی تکرار میشود تا زمانی که میانگین تابع هدف دیگر کاهش نیابد.
به این دلیل تصادفی نامیده میشود که هر مجموعه کوچکی از نمونهها تخمینی نویزدار (به دلیل وجود نویز یا اطلاعات ناقص، دقت کمتری دارد. مترجم.) از گرادیان متوسط بر روی تمام نمونهها ارائه میدهد.
این روش ساده معمولاً در مقایسه با تکنیکهای بهینهسازی پیچیدهتر، مجموعهای از وزنها را به طور شگفتانگیزی سریعتر پیدا میکند. پس از آموزش، عملکرد سیستم بر روی مجموعهای متفاوت از نمونهها به نام مجموعه تست اندازهگیری میشود. این کار برای آزمایش توانایی عمومی سازی ماشین (توانایی تولید پاسخهای منطقی در ورودیهای جدیدی که در طول آموزش هرگز ندیده است) انجام میشود.
بسیاری از برنامههای کاربردی کنونی یادگیری ماشین از طبقهبندیکنندههای خطی که از مهندسی ویژگی های دستی (hand engineered features) (به ویژگی هایی که به صورت دستی (نه توسط ماشین ها) با استفاده از الگوریتم های مختلف در یک تصویر طراحی و ساخته شده اند و از داده های خام استخراج می شوند، اشاره دارد. مترجم. ) استفاده میکنند.
یکطبقه کننده خطی دو کلاسه، مجموع وزنی مولفههای بردار ویژگی را محاسبه میکند. اگر مجموع وزنی بالاتر از یک آستانه باشد، ورودی بهعنوان متعلقات یک دسته خاص طبقهبندی میشود.
از دهه ۱۹۶۰ میدانستیم که طبقهبندیکنندههای خطی تنها میتوانند فضای ورودی خود را به مناطق بسیار ساده تقسیم کند. بهعبارتدیگر نیمه فضاهایی که توسط یک ابر صفحه از هم جدا شدهاند. (در این روش، باتوجهبه ویژگیهای دادهها، یک صفحه بهگونهای در فضای ویژگیها قرار داده میشود که دادههای دودسته را از هم جدا کند).
اما مشکلاتی مانند تشخیص تصویر و گفتار نیاز به تابع ورودی – خروجی دارند که حساسیت کمی نسبت به تغییرات نامربوط به ورودی داشته باشد. مانند تغییرات در موقعیت، جهت یا روشنایی یک شیء، یا تغییرات در تلفظ یا لهجه گفتار .
درحالیکه به تغییرات جزئی خاص بسیار حساس باشد (برای مثال، تفاوت بین یک گرگ سفید و یک نژاد سگ سفید گرگ مانند به اسم ساموید). در سطح پیکسل، تصاویر دو ساموید در حالات و محیطهای مختلف ممکن است با یکدیگر بسیار متفاوت باشند. درحالیکه دو تصویر از یک ساموید و یک گرگ در یک موقعیت و پسزمینههای مشابه ممکن است بسیار شبیه به یکدیگر باشند.
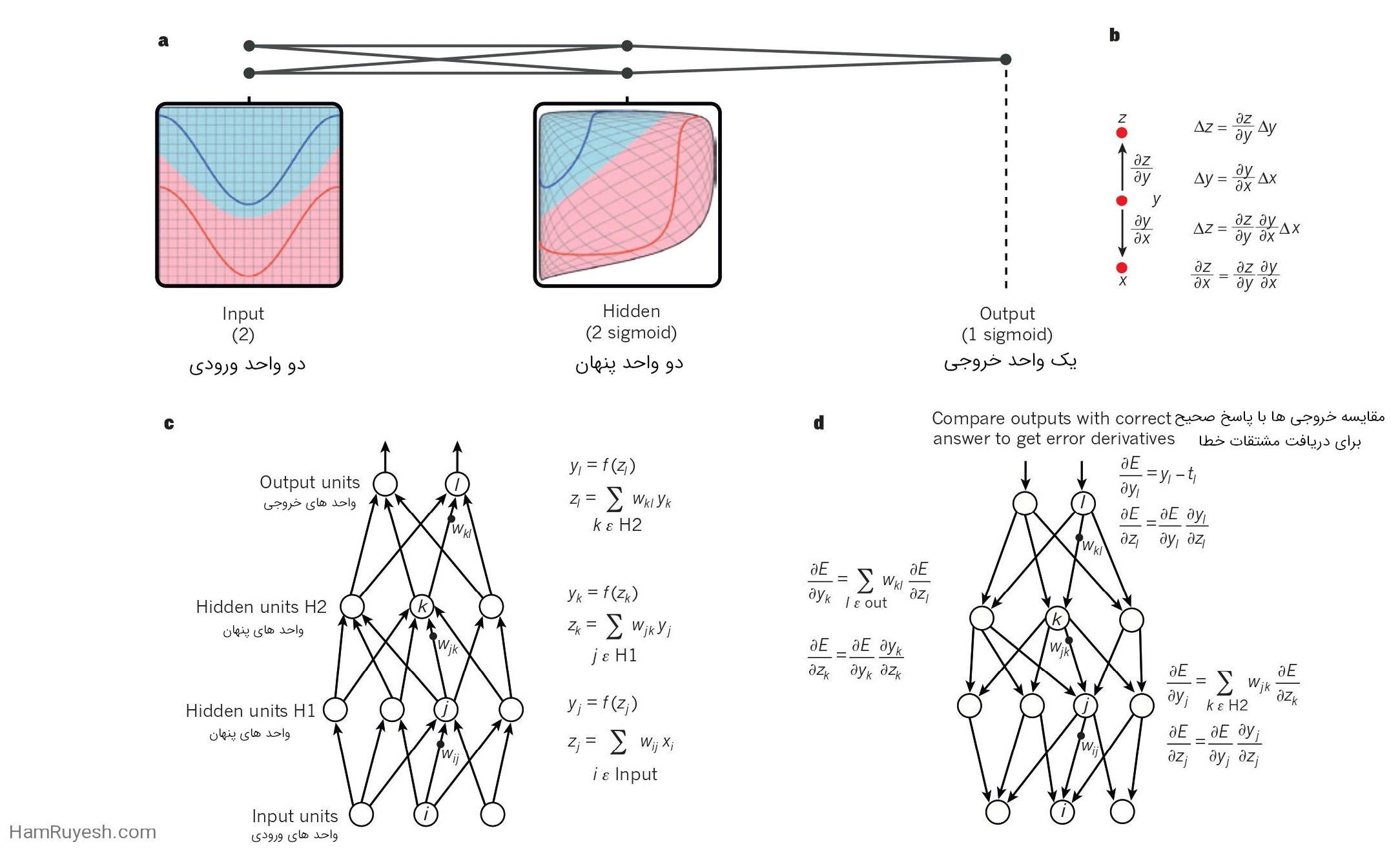
![]()
a، یک شبکه عصبی چندلایه (که با نقاط متصل نشاندادهشده است) میتواند فضای ورودی را بهگونهای تغییر دهد که طبقات دادهها (نمونههایی که در خطوط قرمز و آبی قرار دارند) بهصورت خطی قابلجداسازی باشند. توجه داشته باشید که چگونه یک شبکه منظم (نشاندادهشده در سمت چپ) در فضای ورودی نیز توسط واحدهای پنهان تبدیل میشود (نشاندادهشده در پنل میانی). این یک مثال گویا با تنها دو واحد ورودی، دو واحد پنهان و یک واحد خروجی است. اما شبکههای مورداستفاده برای تشخیص اشیا یا پردازش زبان طبیعی شامل دهها یا صدها هزار واحد هستند. با اجازه از C.Olah (/http://colah.github.io)تکثیر شده است.
b، قاعده زنجیرهای مشتقات به ما میگوید چگونه دو تأثیر کوچک (تأثیر یک تغییر کوچک در x بر روی y و تأثیر y بر روی z ) ترکیب میشوند. یک تغییر کوچک Δx در x ابتدا تبدیل به یک تغییر کوچک Δy در y میشود با ضرب در y/∂x∂ (یعنی تعریف مشتق جزئی). به طور مشابه، تغییر Δy یک تغییر Δz در z ایجاد میکند. جایگذاری یک معادله در دیگری، قاعده زنجیرهای مشتقات را میدهد – چگونه Δx از طریق ضرب در حاصلضرب y / ∂x∂ و x∂ / ∂z به Δz تبدیل میشود. این قاعده همچنین زمانی کار میکند که x، y و z بردارها باشند (و مشتقات ماتریس ژاکوبی باشند).
c، معادلاتی که برای محاسبه فاز پبشرو (forward pass) در یک شبکه عصبی با دو لایه مخفی و یک لایه خروجی استفاده میشود. هر کدام یک ماژول هستند که از طریق آن میتوان گرادیانها را به عقب منتقل کرد. در هر لایه، ابتدا ورودی کلی z به هر واحد محاسبه میشود که مجموعهای از خروجیهای واحدها در لایه پایینتر است. سپس یک تابع غیرخطی (.)f بر روی z اعمال میشود تا خروجی واحد را بدست آوریم. به منظور سادگی، مقدار بایاس (bias) را نادیده گرفتیم. توابع غیرخطی استفاده شده در شبکههای عصبی شامل واحد خطی اصلاح شده (ReLU) f(z) = max(0,z) که معمولاً در سالهای اخیر استفاده میشود. همچنین توابع سیگموئیدی معمولی مانند تانژانت هیپربولیک، f(z) = (exp(z) – exp(-z)) / (exp(z) + exp(-z)) و تابع لجستیک، f(z) = 1/(1 + exp(-z)) میباشند.
d، معادلات مورد استفاده برای محاسبه حرکت پس انتشار (Backward pass). در هر لایه پنهان، مشتق خطا نسبت به خروجی هر واحد محاسبه میشود که یک جمع وزندار از مشتق خطا نسبت به ورودی کل واحدها در لایه بالا است. سپس مشتق خطا نسبت به خروجی را به مشتق خطا نسبت به ورودی تبدیل میکنیم با ضرب آن در گرادیان f(z). در لایه خروجی، مشتق خطا نسبت به خروجی یک واحد با تفاضلگیری تابع هزینه محاسبه میشود. این مقدار برابر است با yl − tl اگر تابع هزینه برای واحد l برابر با 0.5(yl − tl)2 باشد، جایی که tl مقدار هدف است.
هنگامی که E∂/∂zk مشخص شود، مشتق خطا برای وزن wjk در ارتباط از واحد j در لایه پایین فقط yj ∂E/∂zk است.
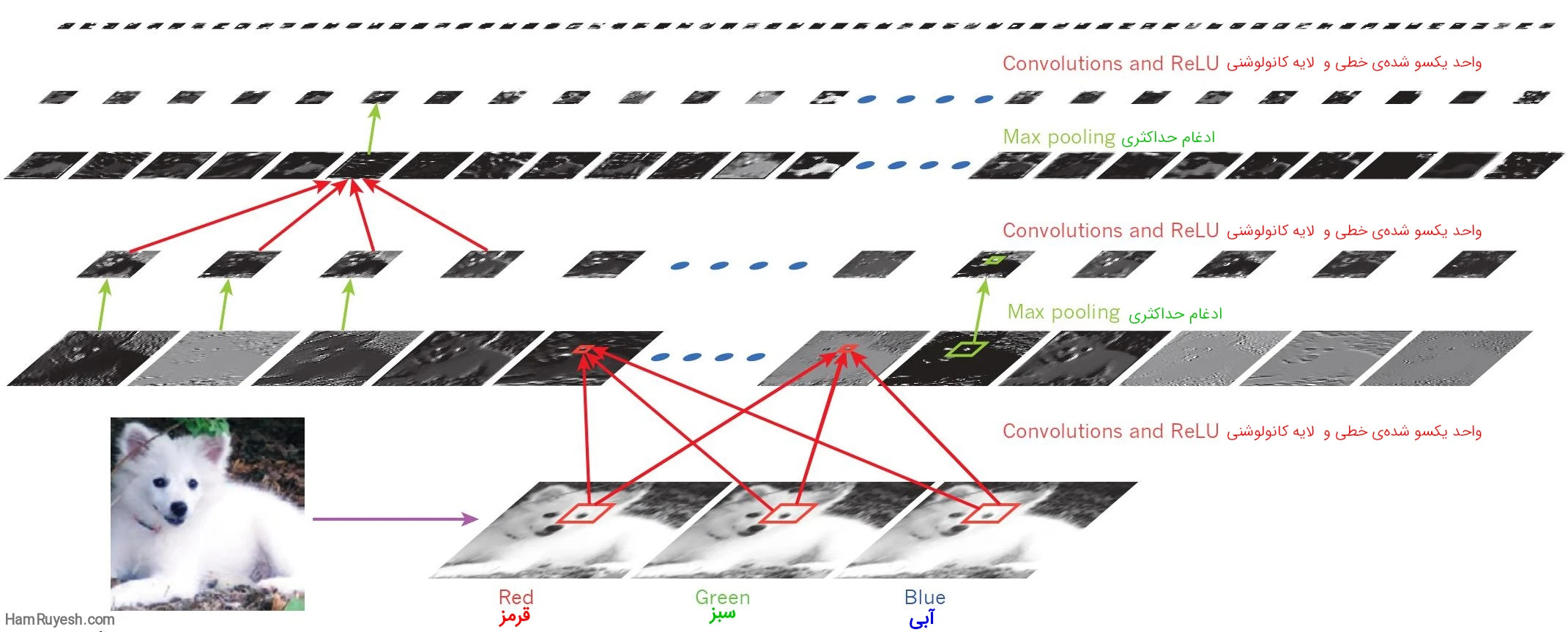
خروجیها (نه فیلترها) هر لایه (به صورت افقی) از یک معماری شبکه کانولوشن معمولی روی تصویر یک سگ ساموید اعمال میشود. (پایین سمت چپ؛ و ورودیهای RGB (قرمز، سبز، آبی)، پایین سمت راست).
هر تصویر مستطیلی یک خروجی لایه کانولوشنی است که به آن فیچرمپ (feature map) گفته می شود، مربوط به خروجی یکی از ویژگیهای یادگیری شده است که در هر یک از موقعیتهای تصویر شناسایی میشود. اطلاعات بهصورت پایینبهبالا جریان دارد، به این صورت که ویژگیهای سطح پایین بهعنوان تشخیصدهندههای لبههای جهتدار عمل میکنند و برای هر کلاس تصویر در خروجی یک امتیاز محاسبه میشود. ReLU، واحد خطی یکسو شده.
پیکسلهای خام احتمالاً نمیتوانند دو مورد آخر را از هم متمایز کنند، درحالیکه دو مورد اول را در یک دسته قرار میدهند. به همین دلیل است که طبقهبندیکنندههای کمعمق (shallow) به یک استخراجکننده ویژگی خوب نیاز دارند که معضل بهگزینی – تغییرناپذیری را حل میکند – که بازنماییهای منتخب را برای جنبههایی از تصویر که برای تمایز مهم هستند تولید میکند، اما نسبت به جنبههای نامربوط مانند حالت قرارگیری حیوان تغییرناپذیر هستند.
برای قدرتمندتر کردن طبقهبندیکنندهها، میتوان از ویژگیهای غیرخطی عمومی مانند روشهای هستهای (kernel methods) استفاده کرد 20. اما ویژگیهای عمومی مانند مواردی که با هسته گاوسی به وجود میآیند به یادگیرنده اجازه نمیدهد که بهخوبی دور از مثالهای آموزشی عمومیت یابد. ۲۱.
گزینه معمول این است که بهصورت دستی طراحی استخراجکننده ویژگی خوب را انجام دهید. که به مقدار قابلتوجهی مهارت مهندسی و تخصص در حوزه نیاز دارد. اما میتوان از این همه اجتناب کرد اگر بتوان ویژگیهای خوب را به طور خودکار با استفاده از یک روش یادگیری همهمنظوره یاد گرفت. این مزیت کلیدی یادگیری عمیق است.
یک معماری یادگیری عمیق یک پشته (stack) چندلایه از ماژولهای ساده است که همه (بیشتر) آنها قابلیت یادگیری دارند و بسیاری از آنها نگاشتهای ورودی – خروجی غیرخطی را محاسبه میکنند. هر ماژول در پشته ورودی خود را تبدیل میکند تا هم گزینشپذیری و هم تغییرناپذیری نمایش را افزایش دهد.
با چندلایه غیرخطی، بهعنوانمثال با عمقی از ۵ تا ۲۰، یک سیستم میتواند توابع بسیار پیچیدهای از ورودیهای خود را پیادهسازی کند. که به طور همزمان حساس به جزئیات کوچک هستند – تمایز ساموییدها از گرگهای سفید – و هم بیتفاوت به تغییرات بزرگ غیرمرتبط مانند پسزمینه، قرارگیری، نور و اشیا اطراف.
هم رویش منتشر کرده است:
آموزش شبکه عصبی مصنوعی — از صفر به زبان ساده
الگوریتم پس انتشار برای آموزش معماری های چند لایه
از اوایل روزهای تشخیص الگو22،23، هدف پژوهشگران بود که مهندسی ویژگی های دستی را با شبکههای چندلایه قابل آموزش جایگزین کنند. اما با وجود سادگی آن، راه حل تا دهه 1980 به طور گسترده ای درک نشده بود. همانطور که مشخص شد، معماریهای چندلایه میتوانند با استفاده از گرادیان کاهشی تصادفی آموزش داده شوند.
تا زمانی که ماژولها نسبت بین توابع هموار(smooth function) ورودیها و وزنهای داخلی خود باشند. میتوان با استفاده از روش پس انتشار، گرادیانها را محاسبه کرد. این ایده که این کار قابل انجام است و کار میکند، در دهههای 1970 و 1980 توسط چندین گروه مستقل کشف شد24–27.
روش پس انتشار برای محاسبه گرادیان یک تابع هدف نسبت به وزنهای یک پشته چندلایه از ماژولها. چیزی بیشتر از کاربرد عملی از قاعده زنجیرهای برای مشتقات است. بینش کلیدی این است که مشتق (یا گرادیان) هدف نسبت به ورودی یک ماژول میتواند با بازگشت از گرادیان نسبت به خروجی آن ماژول (یا ورودی ماژول بعدی) محاسبه شود (شکل ۱).
معادله پس انتشار میتواند به صورت مکرر برای انتقال گرادیان از طریق تمامی ماژولها استفاده شود. از بالا (جایی که شبکه پیشبینی خود را انجام میدهد) تا پایین (جایی که ورودی خارجی تغذیه میشود). با محاسبه این گرادیانها، محاسبه گرادیان نسبت به وزنهای هر ماژول به راحتی انجام میشود.
بسیاری از کاربردهای یادگیری عمیق از معماریهای شبکه عصبی پیشخور (feedforward) (شکل ۱) استفاده میکنند. که یاد میگیرند یک ورودی با اندازه ثابت (مانند تصویر) را به یک خروجی با اندازه ثابت (مانند احتمال برای هر یک از چند دسته) نگاشت کنند.
برای رفتن از یک لایه به لایه بعدی، مجموعهای از واحدها، یک جمع وزن دار از ورودیهای خود را از لایه قبلی محاسبه کرده و نتیجه را از طریق یک تابع غیرخطی عبور می دهند. در حال حاضر، محبوبترین تابع غیرخطی (ReLU) است که به طور ساده یک یکسوساز نیم موج f(z) = max(z, 0) است.
در دهههای گذشته، شبکههای عصبی از توابع غیرخطی هموارتر مانند tanh(z) یا 1 / (1 + (z-))exp استفاده میکردند. اما ReLU به طور معمول در شبکههایی با تعداد لایههای زیاد بسیار سریعتر یاد میگیرد. که امکان آموزش یک شبکه عمیق نظارت شده (supervised) بدون پیشآموزش بدون نظارت (unsupervised) را فراهم میکند.
واحدهایی که در لایه ورودی یا خروجی نیستند به صورت قراردادی واحدهای پنهان نامیده میشوند. لایههای پنهان میتوانند به عنوان یک روش غیرخطی ورودی را به گونهای تغییر دهند که دستهبندیها توسط لایه آخر به صورت خطی قابل جداسازی شوند (شکل ۱).
در اواخر دهه 1990، شبکههای عصبی و انتشار روبهعقب خطاها به طور عمده توسط جامعه یادگیری ماشین کنار گذاشته شد و توسط جوامع بینایی کامپیوتر و تشخیص گفتار نادیده گرفته شد.
به طور گستردهای فکر میشد که یادگیری استخراجکنندههای ویژگی مفید چندمرحلهای با کمترین دانش پیشین غیرممکن است. بهخصوص، به طور معمول فکر میشد که یک نزول گرادیان ساده در مینیممهای محلی ضعیف گیر میافتد – تنظیمات وزنی که هیچ تغییر کوچکی باعث کاهش خطای میانگین نمیشود. منظور جایی هست که در وزنهایی میفتیم که چنان به صفر نزدیک هستند، عملاً جلوی کاهش تدریجی خطای شبکه را میگیرند (توضیح مترجم).
در عمل، وجود مینیمم های محلی ضعیف به ندرت مشکلی برای شبکه های بزرگ محسوب می شود. صرف نظر از شرایط اولیه، سیستم تقریباً همیشه به راه حل هایی با کیفیت بسیار مشابه می رسد. نتایج نظری و تجربی اخیر قویاً نشان می دهد که مینیمم های محلی به طور کلی یک موضوع جدی نیستند. درعوض، منظره مملو از تعداد ترکیبی زیادی از نقاط زینی است که در آن شیب صفر است. و سطح در اکثر ابعاد به سمت بالا و در بقیه ابعاد به پایین خمیده می شود 29،30.
به نظر میرسد این تحلیل نشان میدهد که نقاط زینی با تنها چند جهت انحنای رو به پایین به تعداد بسیار زیادی وجود دارند. اما تقریباً همه آنها مقادیر بسیار مشابه تابع هدف را دارند. بنابراین، مهم نیست که الگوریتم در کدام یک از این نقاط زینی گیر کند.
علاقه به شبکه های پیشخور عمیق در حدود سال 2006 (مراجع 31 تا 34) توسط گروهی از پژوهشگرانی که توسط موسسه کانادایی تحقیقات پیشرفته (CIFAR) گرد هم آمده بودند، احیا شد.
محققان روشهای یادگیری بدون نظارت را معرفی کردند که میتوانست لایههایی از تشخیصدهندههای ویژگی را بدون نیاز به دادههای برچسبدار ایجاد کند. هدف از یادگیری هر لایه تشخیصدهندههای ویژگی این بود که بتوانیم فعالیت تشخیصدهندههای ویژگی (یا ورودیهای خام) را در لایه پایین تر بازسازی یا مدلسازی کنیم.
با “پیش آموزش” (pre-training) چندین لایه از تشخیصدهندههای ویژگی به تدریج پیچیده تر با استفاده از این هدف بازسازی، وزن های یک شبکه عمیق می توانستند به مقادیر معقول مقداردهی شوند. سپس میتوان یک لایه نهایی از واحدهای خروجی را به بالای شبکه اضافه کرد و کل سیستم عمیق را میتوان با استفاده از پسانتشار استاندارد تنظیم کرد.33-35. این برای تشخیص ارقام دست نویس یا برای تشخیص عابران پیاده بسیار خوب کار می کرد. به خصوص زمانی که مقدار داده های برچسب گذاری شده بسیار محدود بود.36.
اولین کاربرد عمده این رویکرد پیشآموزشی در تشخیص گفتار بود و با ظهور واحدهای پردازش گرافیکی سریع (GPU) که برای برنامهنویسی راحت بودند امکانپذیر شد.37 و به محققان این امکان را داد که شبکه ها را 10 یا 20 برابر سریعتر آموزش دهند. در سال ۲۰۰۹، این روش برای نگاشت پنجرههای زمانی کوتاهی از ضرایب استخراج شده از موج صوتی به مجموعهای از احتمالات برای قطعات مختلف گفتار که ممکن است توسط فریم در مرکز پنجره نمایش داده شود، استفاده شد.
این روش نتایجی بینظیر را در معیار شناخت گفتار استاندارد که از دایره واژگان کوچک استفاده میکرد، به دست آورد و به سرعت برای انجام وظایف با دایره واژگان بزرگ نتایجی بینظیر را به ارمغان آورد. تا سال 2012، نسخههایی از شبکه عمیق از سال 2009 توسط بسیاری از گروههای اصلی گفتار در حال توسعه بود.6 و در حال حاضردرگوشی های اندرویدی مستقر شده اند.
برای مجموعه دادههای کوچکتر، پیشآموزش بدون نظارت به جلوگیری ازبیش برازش (overfitting) کمک میکند40. زمانی که تعداد نمونههای برچسبدار کم است یا در یک محیط انتقالی که برای برخی از وظایف ‘منبع’ تعداد زیادی نمونه وجود دارد. اما برای برخی از وظایف مورد نظر تعداد کمی نمونه وجود دارد باعث بهبود قابل توجهی در عمومی سازی میشود. هنگامی که یادگیری عمیق بازسازی شد، معلوم شد که مرحله پیش آموزش فقط برای مجموعه داده های کوچک مورد نیاز است.
با این حال، یک نوع خاص از شبکه های عمیق و پیشخور وجود داشت که آموزش آن بسیار ساده تر و عمومی سازی آن بسیار بهتر از شبکه هایی با اتصال کامل بین لایه های مجاور بود. این شبکه عصبی کانولوشن (ConvNet) بود41،42 . در طول دوره ای که شبکه های عصبی نامناسب بودند، موفقیت های عملی زیادی به دست آورد. اخیراً به طور گسترده توسط جامعه بینایی کامپیوتر پذیرفته شده است.
شبکه عصبی کانولوشن
ConvNet ها برای پردازش داده هایی طراحی شده اند که به صورت آرایه های متعدد ظاهر می شوند. به عنوان مثال یک تصویر رنگی متشکل از سه آرایه دو بعدی شامل مقدار های طیف رنگی پیکسل یا به اصطلاح شدت پیکسل (pixel intensity) در سه کانال رنگی است. بسیاری از حالات داده به شکل آرایه های متعدد هستند: 1D برای سیگنال ها و دنباله ها، از جمله زبان. 2D برای تصاویر یا طیف نگارهای صوتی. و 3D برای ویدیو یا تصاویر حجمی. چهار ایده کلیدی در پشت ConvNet ها وجود دارد که از ویژگی های سیگنال های طبیعی بهره می برند: اتصالات محلی، وزن های مشترک، ادغام و استفاده از چندین لایه.
معماری یک ConvNet معمولی (شکل 2) به صورت مجموعه ای از مراحل، ساختار یافته است. چند مرحله اول از دو نوع لایه تشکیل شده است: لایه های کانولوشن (convolutional layers) و لایه های ادغام (pooling layers). واحدها در یک لایه کانولوشن در فیچرمپ ها سازماندهی می شوند، که در آن هر واحد از طریق مجموعه ای از وزن ها به نام بانک فیلتر (filter bank) به اتصالات محلی در فیچرمپ های لایه قبلی متصل می شود. سپس نتیجه این جمع وزنی محلی از طریق یک واحد غیر خطی مانند ReLU منتقل می شود. همه واحدهای موجود در یک نقشه ویژگی، بانک فیلتر یکسانی دارند. نقشه های ویژگی های مختلف در یک لایه از بانک های فیلتر متفاوتی استفاده می کنند.
دلیل اینکه معماری کانولوشن دوقسمتی است، اولاً در دادههای آرایهای مانند تصاویر، گروههای محلی مقادیر، اغلب همبستگی بالایی دارند و موتیفهای محلی متمایز را تشکیل میدهند که بهراحتی شناسایی میشوند. دوم، آمار محلی تصاویر و سایر سیگنالها نسبت به مکان تغییر نمیکند. بهعبارتدیگر، اگر یک موتیف بتواند در یک قسمت از تصویر ظاهر شود، میتواند درهرجایی ظاهر شود. ازاینرو ایده واحدهایی در مکانهای مختلف که وزنهای یکسانی دارند و الگوی یکسانی را درقسمتهای مختلف آرایه تشخیص میدهند، به وجود میآید. از نظر ریاضی، عملیات فیلترکردن که توسط فیچرمپ انجام میشود، یک کانولوشن گسسته است، ازاینرو به این نام میگویند.
اگرچه نقش لایه کانولوشن شناسایی پیوندهای محلی ویژگی ها از لایه قبلی است، نقش لایه ادغام این است که ویژگی های مشابه معنایی را در یک لایه ادغام کند. از آنجایی که موقعیتهای نسبی ویژگیهایی که یک موتیف را تشکیل میدهند میتواند تا حدودی متفاوت باشد، تشخیص مطمئن موتیف میتواند با دانهبندی موقعیت هر ویژگی انجام شود. یک واحد ادغام معمولی حداکثر یک اتصال محلی از واحدها را در یک فیچرمپ (یا در چند فیچرمپ) محاسبه می کند.
واحدهای ادغام مجاور ورودیهایی را از اتصالاتی دریافت میکنند که بیش از یک ردیف یا ستون جابجا شدهاند. در نتیجه ابعاد نمایش کاهش مییابد و تغییر ناپذیری نسبت به جابجاییها و تغییرات کوچک ایجاد میشود. دو یا سه مرحله کانولوشن، غیر خطی بودن و ادغام روی هم قرار می گیرند و به دنبال آن لایه های پیچیده تر و کاملاً به هم متصل می شوند. پس انتشار گرادینت ها از طریق ConvNet به سادگی انتشار از طریق یک شبکه عمیق معمولی است که به تمام وزن ها در تمام بانک های فیلتر اجازه می دهد تا آموزش داده شوند.
شبکههای عصبی عمیق از این ویژگی بهره میبرند که بسیاری از سیگنالهای طبیعی سلسلهمراتب ترکیبی از سیگنالهای سطح پایین هستند که در آن ویژگیهای سطح بالاتر با ترکیبکردن سیگنالهای سطح پایینتر به دست میآیند. در تصاویر، ترکیبهای محلی لبهها، موتیفها را تشکیل میدهند، موتیفها در قطعات جمع میشوند و قطعات اشیا را تشکیل میدهند. سلسلهمراتب مشابهی در گفتار و متن از صداها گرفته تا تلفنها، واجها، هجاها، کلمات و جملات وجود دارد. ادغام اجازه میدهد زمانی که عناصر در لایه قبلی در موقعیت و ظاهر متفاوت پدیدار میشوند، بازنماییها تغییر بسیار کمی کنند.
تمامی لایههای کانولوشنال و ادغام در شبکههای کانولوشنال (ConvNets) مستقیماً تحت تأثیر مفاهیم کلاسیک سلولهای ساده و سلولهای پیچیده در علوم ادراک بصری قرار میگیرند43. ساختار کلی آن به یاد سلسله مراتب LGN-V1-V2-V4-IT در مسیر شکمی قشر بصری (visual cortex ventral) (مسیر ونترال مسیر بصری قشر بصری است که در پردازش و تشخیص ویژگیهای بصری مانند شکلها، رنگها و الگوها نقش دارد. این مسیر از قسمت پشتی قشر بصری شروع شده و از طریق مناطق مختلفی از مغز عبور کرده و در نهایت به قشر بصری ونترال در قسمت شکمی مغز میرسد. مترجم.) میاندازد44.
وقتی به مدلهای ConvNet و میمونها تصویر یکسان نشان داده میشود، فعالسازی واحدهای سطح بالا در ConvNet نیمی از واریانس مجموعههای تصادفی از 160 نورون در (inferotemporal cortex) (قشری که نقش بسیار مهمی برای شناخت بصری اشیا ایفا می کند. مترجم.) را توضیح میدهد45. شبکههای کانولوشنی ریشههای خود را در نئوکوگنیترون (neocognitron46) دارند. معماری آن تا حدی مشابه بود، اما الگوریتم یادگیری نظارت شده از ابتدا تا انتها مانند پس انتشار نداشت. یک شبکه کانولوشنی یک بعدی اولیه به نام شبکه عصبی با تاخیر زمانی (time-delay neural net) برای تشخیص واجها و کلمات ساده استفاده شد47,48.
کاربردهای متعددی از شبکههای کانولوشن به اوایل دهه 1990 برمیگردد که با شبکههای عصبی با تأخیر زمانی برای تشخیص گفتار شروع شد.47 و خواندن اسناد کتبی 42. سیستم خواندن سند (document) از یک ConvNet استفاده می کند که به طور مشترک با یک مدل احتمالی آموزش داده شده است که محدودیت های زبان را پیاده سازی می کند. در اواخر دهه 1990، این سیستم بیش از 10٪ از کل چک ها را در ایالات متحده می خواند. تعدادی از سیستم های تشخیص کاراکتر نوری و تشخیص دست خط مبتنی بر ConvNet بعداً توسط مایکروسافت به کار گرفته شد. 49. ConvNet ها همچنین در اوایل دهه 1990 برای تشخیص اشیا در تصاویر طبیعی، از جمله صورت و دست50,51 و برای تشخیص چهره52 آزمایش شدند.
درک تصویر با شبکه کانولوشن عمیق
از اوایل دهه 2000، ConvNets با موفقیت زیادی در تشخیص، تقسیم بندی و شناخت اشیاء و مناطق در تصاویر استفاده شده است. همه اینها کارهایی بودند که داده های برچسب گذاری شده در آنها نسبتاً فراوان بود. مانند تشخیص علائم راهنمایی و رانندگی53، تقسیم بندی تصاویر بیولوژیکی54 مخصوصا برای نقشه برداری از اتصالات ساختاری در بین سلولهای عصبی و مغز (connectomics) 55و تشخیص چهره، متن، عابران پیاده و بدن انسان در تصاویر طبیعی36،50،51،56-58. یکی از موفقیتهای عملی اخیر ConvNets، تشخیص چهره است59.
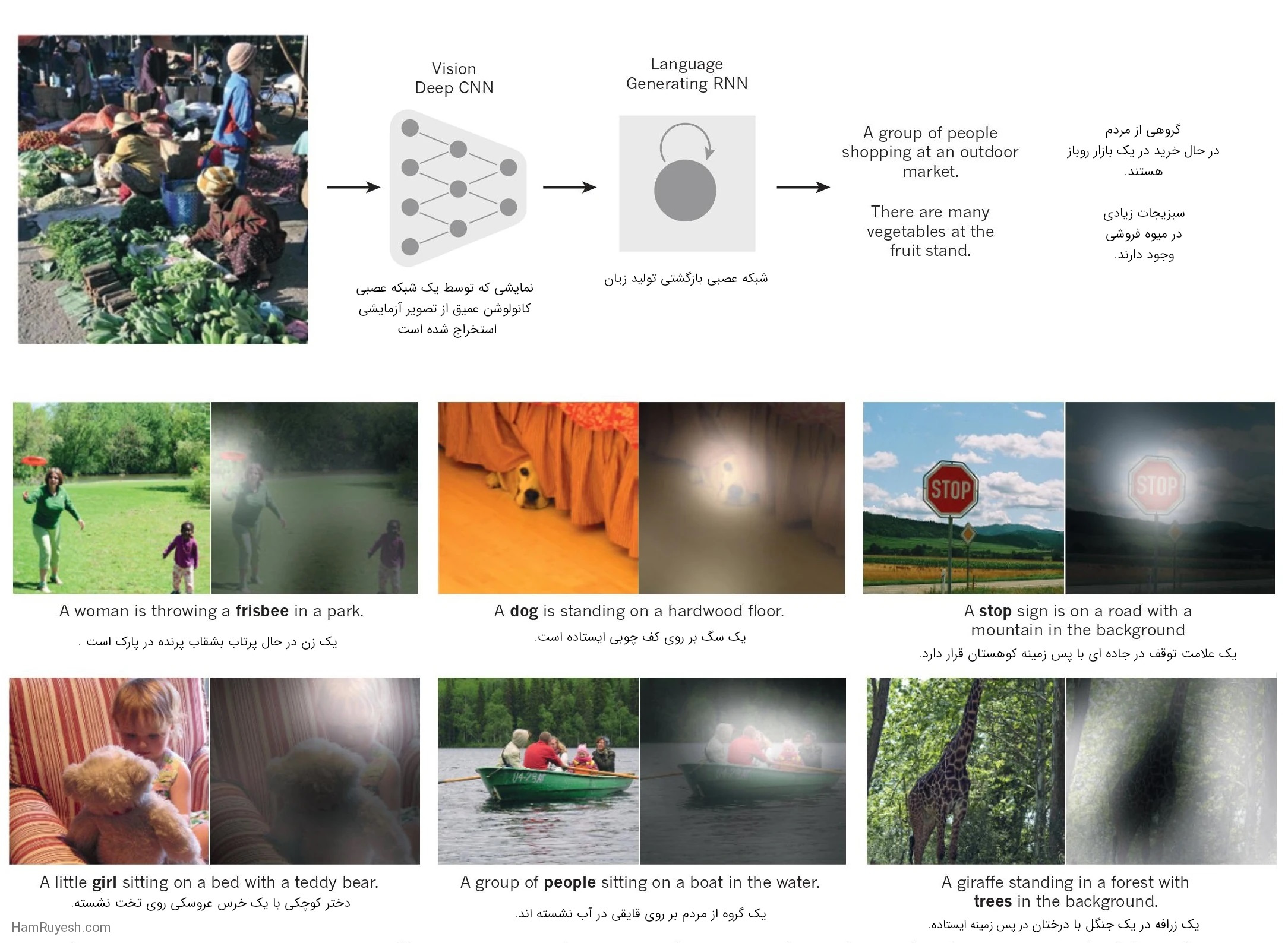
زیرنویسها توسط یک شبکه عصبی بازگشتی (RNN) تولید میشوند. آنها نمایشی که توسط یک شبکه عصبی کانولوشن عمیق(CNN) از تصویر آزمایشی استخراج شده است را به عنوان ورودی اضافی دریافت میکند. در این روش، RNN برای ‘ترجمه’ نمایشهای سطح بالای تصاویر به زیرنویسها آموزش دیده است (بالا). با اجازه از مرجع ۱۰۲ تکثیر شده است. وقتی به شبکه عصبی بازگشتی (RNN) این امکان داده می شود که توجه خود را بر روی مکان مختلفی در تصویر ورودی متمرکز کند (وسط و پایین؛ تکه های روشنتر بیشتر توجه دریافت کردهاند). در هنگام تولید هر کلمه (bold)، ما متوجه شدیم که از این قابلیت برای دستیابی به ترجمه بهتر تصاویر به زیرنویس استفاده میکند.
نکته مهم این است که تصاویر را می توان در سطح پیکسل برچسب گذاری کرد که کاربردهایی در فناوری از جمله روبات های متحرک خودگردان و ماشین های خودران60،61. شرکتهایی مانند Mobileye و NVIDIA از چنین روشهای مبتنی بر ConvNet در سیستمهای بینایی آتی خود برای خودروها استفاده میکنند. دیگر کاربردهایی که اهمیت پیدا میکنند، درک زبان طبیعی14و تشخیص گفتارهستند7.
علیرغم این موفقیتها، ConvNets تا زمان رقابت ImageNet در سال 2012 تا حد زیادی توسط جوامع بینایی کامپیوتر و یادگیری ماشین کنار گذاشته شد. وقتی شبکههای کانولوشنی عمیق بر روی مجموعهای از حدود یک میلیون تصویر از وب که شامل ۱۰۰۰ کلاس مختلف بود، استفاده شد. آنها به نتایج فوق العاده ای دست یافتند و تقریباً میزان خطای بهترین رویکردهای رقابتی را به نصف کاهش دادند.1.
این موفقیت ناشی از استفاده کارآمد از پردازندههای گرافیکی، ReLUs، یک تکنیک منظمسازی جدید به نام رها کردن (Dropout) است62و تکنیک هایی برای تولید نمونه های آموزشی بیشتر با تغییر شکل نمونه های موجود. این موفقیت انقلابی در بینایی کامپیوتر به وجود آورده است. ConvNets در حال حاضر رویکرد غالب برای تقریباً تمام وظایف شناسایی و تشخیص است4،58،59،63-65 و به عملکرد انسان در برخی از وظایف نزدیک شود. یک نمایش خیرهکننده اخیر، ترکیب ConvNets و ماژولهای شبکه بازگشتی برای تولید زیرنویسهای تصویر است (شکل 3).
معماریهای ConvNet اخیر دارای 10 تا 20 لایه ReLU، صدها میلیون وزن و میلیاردها اتصال بین واحدها هستند. در حالی که آموزش چنین شبکه های بزرگی تا همین دو سال پیش می توانست هفته ها طول بکشد. پیشرفت در سخت افزار، نرم افزار و موازی سازی الگوریتم (algorithm parallelization) زمان آموزش را به چند ساعت کاهش داده است.
عملکرد سیستم های بینایی مبتنی بر ConvNet باعث شده است که اکثر شرکت های فناوری بزرگ از جمله گوگل، فیس بوک، مایکروسافت، آیبیام، یاهو، توییتر، ادوبی، همانند تعداد رو به افزایشی از شرکتهای نوپا، پروژههای تحقیق و توسعه برای جایگیرکردن محصولات و خدمات درک تصویر مبتنی بر ConvNet راهاندازی کنند.
ConvNet ها به راحتی قابل پیاده سازی سخت افزاری کارآمد در تراشه ها یا آرایه های دریچه ی برنامه پذیر میدانی (field programmable gate arrays) هستند.66،67. تعدادی از شرکتها مانند NVIDIA، Mobileye، Intel، Qualcomm و Samsung در حال توسعه تراشههای ConvNet برای فعال کردن کاربرد بینایی بیدرنگ (real-time vision) در گوشیهای هوشمند، دوربینها، روباتها و خودروهای خودران هستند.
هم رویش منتشر کرده است:
شبکه عصبی کانولوشن به زبان ساده
بازنمایی های توزیع شده و پردازش زبان
نظریه یادگیری عمیق نشان می دهد که شبکه های عمیق دو مزیت نمایی متفاوت نسبت به الگوریتم های یادگیری کلاسیک دارند که از نمایش های توزیع شده استفاده نمی کنند.21. هر دوی این مزیتها از قدرت ترکیب ناشی میشوند و به توزیع تولید داده مبتنی بر دادههای زیرین که ساختار جزئی مناسبی دارد بستگی دارد.40.
اول، یادگیری بازنمایی های توزیع شده، عمومی سازی ترکیبات جدیدی از مقادیر ویژگی های آموخته شده را فراتر از آنچه در طول آموزش مشاهده می شود، امکان پذیر می کند. (به عنوان مثال، 2n ترکیب با n ویژگی دودویی امکانپذیر است)68,69. دوم، ترکیب لایههای نمایش در یک شبکه عمیق، یک مزیت نمایی دیگر را به همراه دارد70 (نمایی در عمق).
لایههای پنهان یک شبکه عصبی چندلایه یاد میگیرند که ورودیهای شبکه را به گونهای بازنمایی کنند که پیشبینی خروجیهای هدف را آسان میکند. این موضوع به خوبی توسط آموزش یک شبکه عصبی چندلایه برای پیشبینی کلمه بعدی در یک دنباله از کلمات قبلی نشان داده شده است. هر کلمه در متن به عنوان یک بردار یک از N به شبکه ارائه می شود، یعنی یک جزء دارای مقدار 1 و بقیه 0 هستند. در لایه اول، هر کلمه الگوی متفاوتی از بردار های کلمه ایجاد می کند (شکل 4).
در یک مدل زبان، لایه های دیگر شبکه یاد می گیرند که بردارهای کلمه ورودی را به یک بردار کلمه خروجی برای کلمات بعدی پیش بینی شده تبدیل کند. این می تواند برای پیش بینی احتمال ظاهر شدن هر کلمه در واژگان به عنوان کلمه بعدی استفاده شود. شبکه بردارهای کلمه ای را می آموزد که شامل بسیاری از مؤلفه های فعال است که هر کدام می توانند به عنوان ویژگی جداگانه کلمه تفسیر شوند. همانطور که ابتدا در زمینه یادگیری بازنمایی های توزیع شده برای نمادها نشان داده شد27. این ویژگی های معنادار به وضوح در ورودی وجود نداشت. آنها با روش یادگیری به عنوان یک راه خوب برای فاکتورگرفتن روابط ساختارمند بین نمادهای ورودی و خروجی در چندین «قوانین خرد» کشف شدند.
زمانی که دنبالههای کلمات از مجموعه بزرگی ازنوشته های یک متن واقعی میآیند و قوانین خرد اتکا ناپذیرند، بردارهای یادگیری کلمه نیز بسیار خوب کار میکنند.71. برای مثال، هنگامی که برای پیشبینی کلمه بعدی در یک خبر آموزش داده می شوند، بردارهای کلمه یادگرفته شده برای سهشنبه و چهارشنبه بسیار شبیه هستند. همانطور که بردارهای کلمه برای سوئد و نروژ نیز مشابه هستند. چنین نمایشهایی، نمایشهای توزیعشده نامیده میشوند. زیرا عناصر آنها (ویژگیها) انحصاری نیستند و بسیاری از پیکربندیهای آنها با تغییراتی که در دادههای جدید مشاهده میشود مطابقت دارد. این بردارهای کلمه از ویژگی های آموخته شده (learned features) تشکیل شده اند که از قبل توسط متخصصان تعیین نشده اند. اما به طور خودکار توسط شبکه عصبی کشف شده اند. نمایش برداری از کلمات آموخته شده از متن درحال حاضربه طورگسترده دربرنامه های کاربردی زبان طبیعی استفاده می شود14،17،72-76.
موضوع بازنمایی در قلب مباحثات بین نمونه های الهام گرفته از منطق و شبکه عصبی برای شناخت قرار دارد. درالگو های الهام گرفته از منطق، یک نمونه از یک نماد چیزی است که تنها ویژگی آن این است که با سایر نمونه های آن نماد یکسان یا غیر یکسان است وهیچ ساختار داخلی مرتبط با استفاده از آن ندارد. و برای استدلال با نمادها، آنها باید به متغیرها در قواعد منتخب منطقی و عقلانی برای استنتاج وابسته باشند. درمقابل، شبکههای عصبی فقط از بردارهای فعالیت بزرگ، ماتریسهای وزن (weight) بزرگ واسکالرهای غیرخطی استفاده میکنند تا نوعی استنتاج سریع را انجام دهند که مبنای استدلال بدون دردسربرای قضاوت صحیح است.
قبل از معرفی مدل های زبان عصبی 71، رویکرد استاندارد برای مدلسازی آماری زبان، استفاده از بازنمایی های توزیعشده نبود. این رویکرد مبتنی بر شمارش فراوانیهای تکرار وقوع دنبالههای نماد کوتاه تا طول N (به نام N-گرم) بود. تعداد N-گرم های ممکن به ترتیب VN است، که درآن V اندازه واژگان است. بنابراین زمینه مورد نظر برای تعداد انگشت شماری از کلمات، مجموعه آموزشی بسیار بزرگ است. N-گرم ها هر کلمه را به عنوان یک واحد اتمی در نظر می گیرند. بنابراین نمی توانند در میان دنباله های کلمات که از لحاظ معنا به هم مرتبط هستند عمومی سازی کنند. در حالی که مدل های زبان عصبی این کار را انجام می دهند، زیرا هر کلمه را با بردار ویژگی های ارزشمند واقعی مرتبط می کنند و در آن فضای برداری کلمات با ارتباط معنایی به یکدیگر نزدیک می شوند. (شکل 4).
شبکه های عصبی بازگشتی
زمانی که انتشار روبهعقب خطاها که بهاختصار “پس انتشار” (backpropagation) نامیده می شود برای اولین بار معرفی شد. هیجانانگیزترین کاربرد آن برای آموزش شبکههای عصبی بازگشتی (RNN) بود. برای کارهایی که شامل ورودی های متوالی هستند، مانند گفتار و زبان، اغلب بهتر است از RNN ها استفاده کنید (شکل 5). RNN ها یک دنباله ورودی را پردازش می کنند و همزمان در واحدهای پنهان خود یک “بردار حالت” را حفظ می کنند که به طور ضمنی حاوی اطلاعاتی درباره تاریخچه همه عناصر گذشته آن دنباله است. هنگامی که خروجی های واحدهای پنهان را در مراحل گسسته و مختلف زمانی در نظر می گیریم. انگار که خروجی های نورون های مختلف در یک شبکه چند لایه عمیق هستند (شکل 5، سمت راست)، روشن می شود که چگونه می توانیم پس انتشار را برای آموزش RNN ها اعمال کنیم.
RNNها سیستمهای پویای بسیار قدرتمندی هستند. اما آموزش آنها مشکلساز بوده است، زیرا گرادیانهای پس انتشار در هر مرحله زمانی تقویت یا محو (Vanishing Gradient) میشوند. بنابراین در طی چندین مرحله معمولاً منفجر یا ناپدید میشوند.77,78.
به لطف پیشرفت در معماری79،۸۰ و راه های آموزش RNN ها 81,82. آنها در پیش بینی کاراکتر بعدی در متن۸۳ یا کلمه بعدی در یک دنباله75 بسیار خوب هستند. اما می توانند برای کارهای پیچیده تر نیز استفاده شوند. برای مثال، پس از خواندن یک جمله انگلیسی کلمه به کلمه، میتوان یک شبکه رمزگذار(encoder) انگلیسی را آموزش داد تا بردار حالت نهایی در واحدهای پنهان، نمایش خوبی از اندیشهای که توسط جمله بیان شده است، باشد.
سپس این بردار اندیشه می تواند به عنوان حالت پنهان اولیه (یا به عنوان ورودی اضافی) یک شبکه رمزگشا (decoder) فرانسوی که به صورت مشترک آموزش داده شده است، استفاده شود. این شبکه یک توزیع احتمال را برای اولین کلمه ترجمه شده فرانسوی خروجی می دهد. اگر یک کلمه اول خاص از این توزیع انتخاب شود و به عنوان ورودی به شبکه رمزگشا ارائه شود. آنگاه توزیع احتمال برای کلمه دوم ترجمه و به همین ترتیب تا زمانی که یک نقطه تمامکننده انتخاب شود، تولید خواهد شد17،۷۲،۷۶.
بطور کلی، این فرایند دنبالههایی از کلمات فرانسوی را بر اساس یک توزیع احتمالی تولید میکند که وابسته به جمله انگلیسی است. این روش نسبتاً ساده برای انجام ترجمه ماشینی بهسرعت با روشهای پیشرفته رقابت میکند. این موضوع شبهههای جدی را درباره اینکه آیا درک یک جمله به چیزی شبیه به عبارات نمادین درونی نیاز دارد که با استفاده از قوانین استنتاج تغییر میکنند، به وجود میآورد. این با دیدگاهی که استدلال روزمره شامل بسیاری از تشابههای همزمان است که هرکدام یک نتیجهگیری میکنند، سازگارتر است.
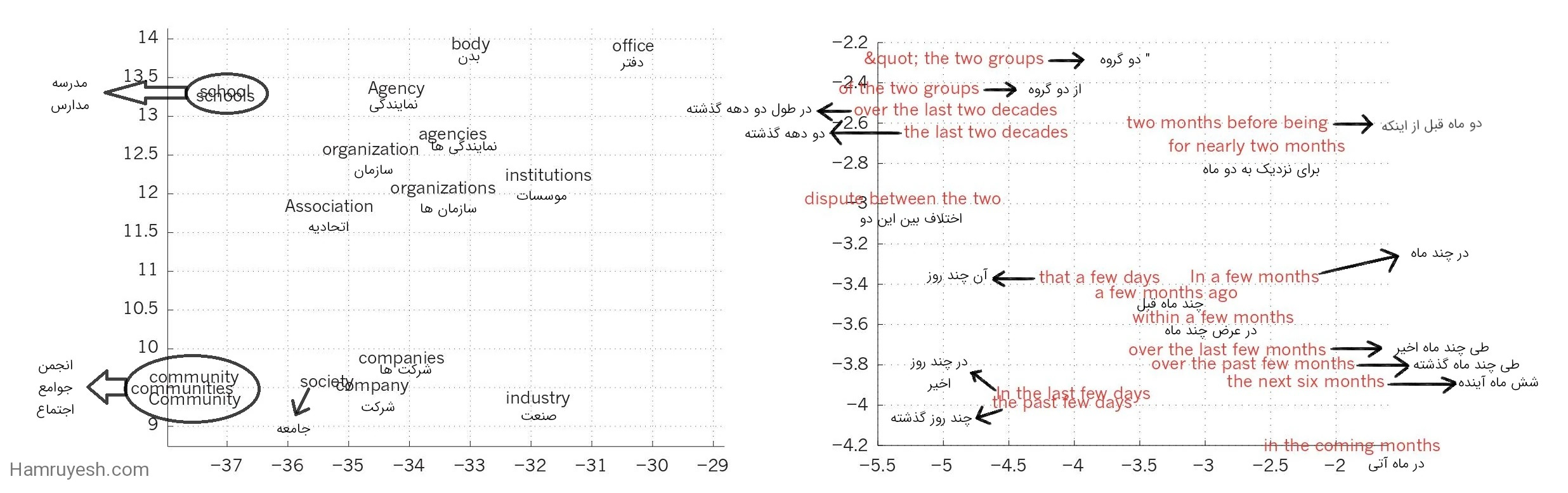
سمت چپ تصویری از نمایش کلماتی است که برای مدلسازی زبان یاد گرفته شدهاند. آنها به صورت غیرخطی با استفاده از الگوریتم t-SNE به صورت دو بعدی تصویربرداری شدهاند تا قابل مشاهده باشند103. سمت راست نمایشی دوبعدی از عباراتی است که توسط یک شبکه عصبی بازگشتی رمزگذار-رمزگشا انگلیسی به فرانسوی آموخته شدهاند75.
میتوان مشاهده کرد که کلمات یا دنبالههای کلماتی که از نظر معنایی مشابهت دارند، به صورت نمایشهای نزدیک به هم نگاشت میشوند. نمایشهای توزیع شده کلمات با استفاده از الگوریتم پس انتشاربرای یادگیری مشترک نمایشی برای هر کلمه و تابعی که مقدار مورد نظر مانند کلمه بعدی در یک دنباله (برای مدلسازی زبان) یا یک دنباله کامل از کلمات ترجمه شده (برای ترجمه ماشینی) را پیشبینی میکند، به دست میآیند.
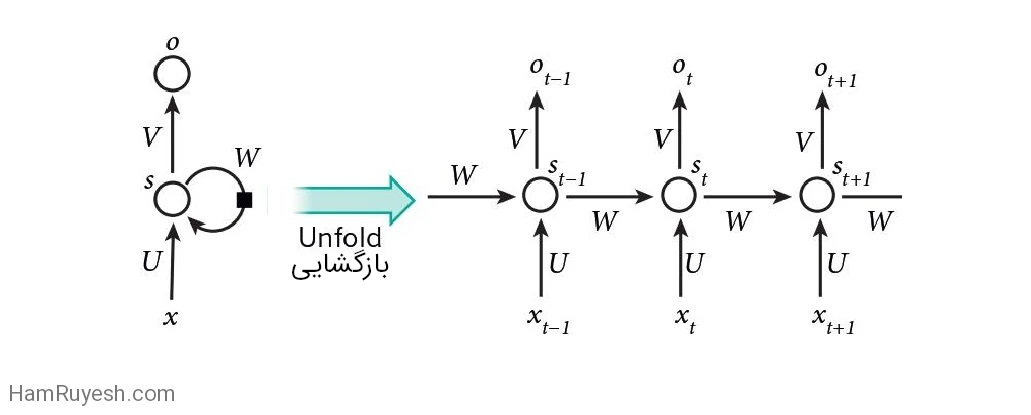
سلولهای عصبی مصنوعی (به عنوان مثال، واحدهای پنهان که تحت گره s با مقادیر st در زمان t قرار دارند). ورودیها را از سایر سلولهای عصبی در گامهای زمانی قبلی دریافت میکنند (این با مربع سیاه که نمایانگر تأخیر یک گام زمانی است، در سمت چپ نمایش داده شده است). به این ترتیب، یک شبکه عصبی بازگشتی میتواند یک دنباله ورودی با عناصر xt را به یک دنباله خروجی با عناصر ot ترسیم کند. به طوری که هر ot به تمام ‘xt قبلی (برای tʹ ≤ t) وابسته است.
پارامترهای یکسان (ماتریسهای U، V، W) در هر مرحله زمانی استفاده میشوند. معماریهای دیگری نیز ممکن است وجود داشته باشند، از جمله نوعی که در آن شبکه میتواند دنبالهای از خروجیها (به عنوان مثال، کلمات) را تولید کند. هر کدام از این خروجیها به عنوان ورودی برای مرحله زمانی بعدی استفاده میشود. الگوریتم پس انتشار(شکل ۱) میتواند به طورمستقیم برروی گراف محاسباتی شبکهی بازشده درسمت راست اعمال شود تا مشتق خطای کل (به عنوان مثال، لگاریتم احتمال تولید دنباله درست خروجیها) نسبت به تمام حالتها (st) و پارامترها محاسبه شود.
به جای ترجمه معنای یک جمله فرانسوی به یک جمله انگلیسی، می توان یاد گرفت که معنای یک تصویر را به یک جمله انگلیسی ترجمه کند (شکل 3). رمزگذار در اینجا یک ConvNet عمیق است که پیکسل ها را به یک بردار فعالیت در آخرین لایه پنهان خود تبدیل می کند. رمزگشا یک RNN شبیه به آنهایی است که برای ترجمه ماشینی و مدل سازی زبان عصبی استفاده می شود. اخیراً علاقه زیادی به چنین سیستم هایی وجود داشته است (نمونه های ذکر شده در شماره 86 را ببینید).
RNN ها، پس از باز شدن در زمان (شکل 5)، می توانند به عنوان شبکه های پیشخور بسیار عمیقی دیده شوند که در آن همه لایه ها وزن های مشترک دارند. اگرچه هدف اصلی آنها یادگیری وابستگی های طولانی مدت است. شواهد نظری و تجربی نشان می دهد که یادگیری ذخیره سازی اطلاعات برای مدت طولانی دشوار است.78.
برای اصلاح آن، یک ایده این است که شبکه را با یک حافظه صریح (explicit memory) تقویت کنیم. اولین پیشنهاد از این دست، شبکههای حافظه طولانی کوتاهمدت (LSTM) است که از واحدهای مخفی خاصی استفاده میکنند که رفتار طبیعی آنها به خاطر سپردن ورودیها برای مدت طولانی است. 79. یک واحد ویژه به نام سلول حافظه مانند یک انباشتگر (accumulator) یا یک (gated leaky neuron)عمل می کند. این واحد در مرحله زمانی بعد به خود اتصال دارد که وزنی برابر یک دارد، بنابراین وضعیت با ارزش واقعی خود را کپی میکند و سیگنال خارجی را جمعآوری میکند. اما این اتصال به خود به صورت ضربی توسط یک واحد دیگر که یاد میگیرد که چه زمانی محتوای حافظه را پاک کند، قطع میشود.
متعاقباً ثابت شد که شبکههای LSTM نسبت به RNNهای معمولی مؤثرتر هستند، بهویژه زمانی که چندین لایه برای هر مرحله زمانی داشته باشند.87 ، که این یک سیستم تشخیص گفتار را فعال می کند که از صوت تا توالی کاراکترها درنوشتار را شامل می شود. شبکههای LSTM یا فرم های مرتبط از واحدهای دروازه ای (gated units) نیز در حال حاضر برای شبکههای رمزگذار و رمزگشا استفاده میشوند که در ترجمه ماشینی بسیار خوب عمل میکنند.17،72،76.
علاوه بر حفظ کردن ساده، ماشینهای تورینگ عصبی (neural turing machine) و شبکههای حافظه برای وظایفی استفاده میشوند که به طور معمول نیاز به استدلال و دستکاری نمادها (symbol manipulation) دارند. ماشینهای تورینگ عصبی میتوانند “الگوریتمها” را یاد بگیرند. به علاوه، آنها میتوانند یاد بگیرند که یک لیست مرتب شده از نمادها را خروجی دهند. وقتی ورودی آنها شامل یک دنبالهی نامرتب از نماد ها همراه با یک مقدار واقعی است که اولویت آن ها در لیست80 را نشان میدهد. شبکههای حافظه میتوانند آموزش داده شوند تا وضعیت جهان را در یک محیط مشابه بازی ماجراجویی متنی (Text Adventure Game) پیگیری کنند. و پس از خواندن یک داستان، بتوانند به سوالاتی که نیاز به استنتاج پیچیده دارند، پاسخ دهند90. در یک مثال آزمایشی، شبکه یک نسخه ۱۵ جملهای از کتاب “ارباب حلقهها” را مشاهده میکند و به سوالاتی مانند “فرودو در کجاست؟” به درستی پاسخ میدهد89.
آینده یادگیری عمیق
یادگیری بدون نظارت91-98 دراحیای علاقه به یادگیری عمیق تأثیر مهمی داشت، اما از آن زمان تحت الشعاع موفقیت های یادگیری نظارت شده قرار گرفت. اگرچه در این بررسی روی آن تمرکز نکردهایم، اما انتظار داریم که یادگیری بدون نظارت در بلندمدت بسیار مهمتر شود. یادگیری انسان و حیوان عمدتاً بدون نظارت است: ما ساختار جهان را با مشاهده آن کشف میکنیم، نه با اینکه نام هر شیء را بشنویم.
بینایی انسان یک فرآیند فعال است که به طور متوالی (optic array) (محرک های سیستم چشمی که از نورهای محیطی برای روشن نمودن یک فضا تشکیل شده است که شامل پرتو های همگرا است. مترجم.) را به صورت هوشمندانه و با توجه به وظیفهای که دارد نمونهبرداری میکند. این فرآیند با استفاده از یک گوده مرکزی کوچک (small fovea) با وضوح بالا و محیطی بزرگ با وضوح پایین، انجام میشود.
انتظار داریم بخش قابل توجهی از پیشرفت آینده در حوزه بینایی از سیستمهایی بیاید که به صورت انتها به انتها (end-to-end) آموزش دیده شدهاند. سیستمهایی که ConvNets را با RNNs ترکیب کرده و از یادگیری تقویتی برای تصمیمگیری درباره جایی که باید نگاه کنند، استفاده میکنند. سیستم های ترکیبی از یادگیری عمیق و یادگیری تقویتی در مراحل ابتدایی خود هستند. اما در حال حاضر از سیستم های بینایی غیرفعال99 در کارهای طبقه بندی و ایجاد نتایج چشمگیر در یادگیری بازی های ویدیویی مختلف100 بهتر عمل می کنند.
درک زبان طبیعی حوزه دیگری است که یادگیری عمیق در چند سال آینده تأثیر زیادی در آن ایجاد می کند. ما انتظار داریم سیستمهایی که از RNN برای درک جملات یا اسناد استفاده میکنند، زمانی که استراتژیهایی را برای توجه انتخابی به یک بخش در یک زمان بیاموزند، بسیار بهتر خواهند شد.76،86.سیستمهایی که از شبکههای عصبی بازگشتی برای درک جملات یا سندات کامل استفاده میکنند. هنگامی که استراتژیهایی برای به صورت انتخابی توجه کردن به یک بخش در یک زمان یاد بگیرند، بهبود چشمگیری خواهند داشت.
در نهایت، پیشرفت عمده در هوش مصنوعی از طریق سیستم هایی حاصل خواهد شد که یادگیری بازنمایی را با استدلال پیچیده ترکیب می کنند. اگرچه یادگیری عمیق و استدلال ساده برای مدت طولانی برای تشخیص گفتار و دست خط استفاده شده است. برای جایگزینی دستکاری عبارات نمادین مبتنی بر قوانین با عملیات بر روی بردارهای بزرگ، نیاز به الگوهای جدیدی وجود دارد101.
کلیدواژگان
یادگیری عمیق | دیپ لرنینگ | deep learning |یادگیری عمیق چیست | کاربرد های یادگیری عمیق | یادگیری ماشین | ConvNet | شبکه کانولوشن | شبکه عصبی | شبکه های عمیق | deep learning چیست | دیپ لرنینگ چیست | شبکه های عصبی بازگشتی چیست | شبکه های عصبی بازگشتی | شبکه عصبی بازگشتی
![]()
![]()
![]()
![]()