
هم رویش منتشر کرده است:
آموزش یادگیری ماشین از صفر — یادگیری سریع و آسان
اعتبارسنجی متقابل (cross-validation) چیست؟
بر اساس ویکیپدیا، اعتبارسنجی (cross-validation) متقابل (که در آمار به آن تخمین چرخشی یا آزمایش خارج از نمونهگیری نیز گفته میشود)، به تکنیکهای اعتبارسنجی مدلهای مختلف اطلاق میشود که معیاری کمی از نتایج تحلیلهای آماری ایجاد میکنند بهطوری که مدلهای تولید شده قادر به تعمیم (generalize) به یک مجموعهداده مستقل یا یک مجموعهداده نگهدارنده است. مدلی که دارای حالت بیش برازش (overfit) است در دنیای واقعی دارای محدودیتهایی است و ارزش بسیاری ندارد. اما چنین مدلهایی گاهی اوقات میتوانند نتایج خوبی در مجموعهداده اعتبار (validation dataset) به دست آورند. این سناریو به طور خاص برای حالتی است که مجموعه آموزش و آزمایش از نظر اندازه کوچکتر باشند؛ بنابراین در چنین شرایطی، بسیار مهم است که اعتبارسنجی متقابل را در مجموعه آموزشی انجام دهیم، یعنی باید اعتبارسنجی متقابل را برای کل مجموعهداده اجرا کنیم.
چگونه میتوان اعتبارسنجی متقابل را با تکنیکهای مختلف انجام داد؟
روشهای مختلفی برای چگونگی انجام اعتبارسنجی متقابل وجود دارد که ما میتوانیم بر اساس مدل، موجودیت دادهها، و نوع مشکلی که با آن روبهرو هستیم، یکی از انواع این روشها را انتخاب کنیم و تصمیم بگیریم که کدام یک، بهتر از بقیه برای وضعیت ما مناسب خواهد بود. برخی از مهمترین تکنیکها در این زمین به شرح زیر است:
هم رویش منتشر کرده است:
آموزش اجرای یک پروژه یادگیری ماشین با پایتون
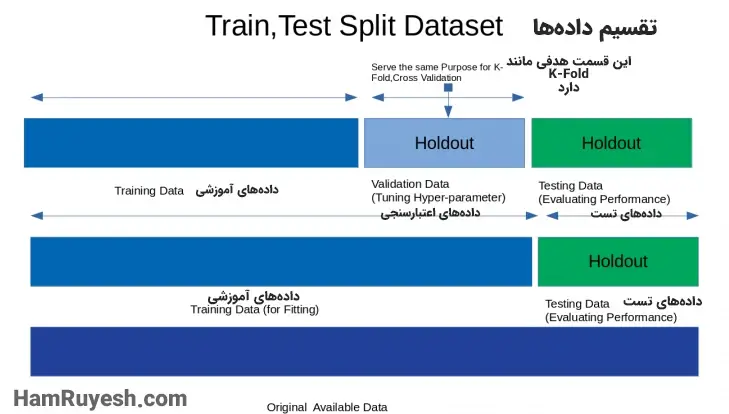
1. روش اعتبارسنجی Holdout
این روش رایجترین روش مورداستفاده برای اعتبارسنجی متقابل (cross-validation) است. ما کل مجموعهداده را به دو بخش نابرابر تقسیم میکنیم که بخش بیشتری از دادهها برای آموزش و قسمت دیگر دادهها برای اعتبارسنجی مدل استفاده میشوند. یعنی اطمینان حاصل شود که کاهش در تابع هدف، با پیشبینیها مطابقت دارد و حالتی از بیش برازش نیست. مثال مناسبی برای این روش، تقسیم دادهها به دو بخش 70 و 30 درصدی است. 70 درصد داده ها برای آموزش فرایندها و مدل استفاده خواهند شد در حالی که 30 درصد دیگر برای اعتبارسنجی مدل مورد استفاده قرار خواهند گرفت. این حالت در شکل زیر مشخص شده است:
قطعه کدی کوچک برای این پیادهسازی:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
iris=load_iris()
X=iris.data
Y=iris.target
linear_reg=LogisticRegression()
# the actual splitting happens here
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)
linear_reg.fit(x_train,y_train)
predictions=linear_reg.predict(x_test)
print("Accuracy score on training set is {}".format(accuracy_score(linear_reg.predict(x_train),y_train)))
print("Accuracy score on test set is {}".format(accuracy_score(predictions,y_test)))
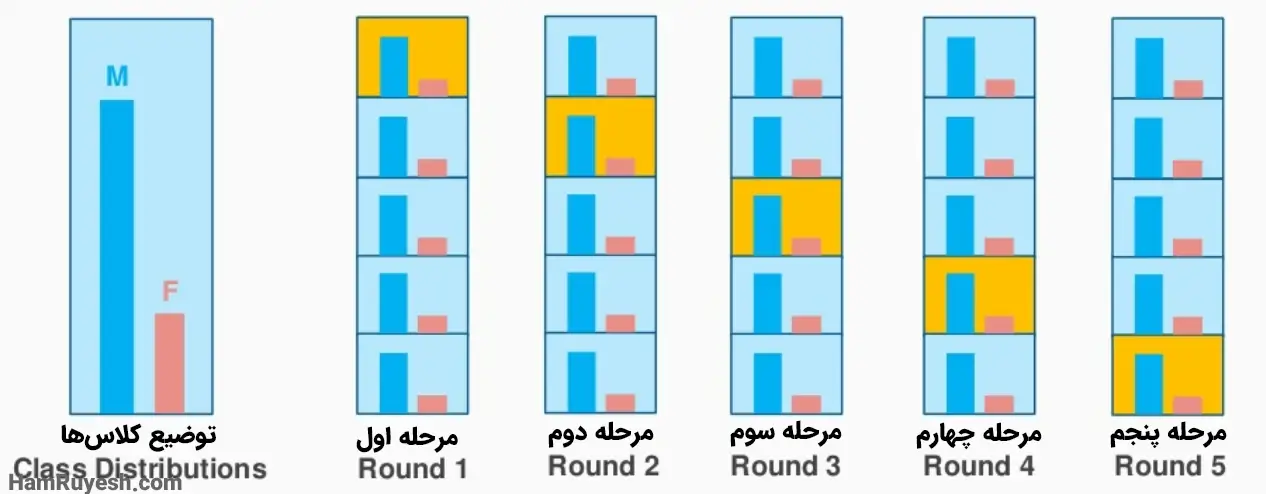
2. اعتبارسنجی Stratified K-Fold
طبقهبندی زمانی استفاده میشود که مجموعهدادهها حاوی کلاسهای نامتعادل باشند؛ بنابراین، اگر با یک تکنیک معمولی اعتبارسنجی متقابل انجام دهیم، ممکن است نمونههایی فرعی تولید شود که دارای توزیع متفاوتی از کلاسها هستند. برخی از نمونههای نامتعادل ممکن است نمرات فوقالعاده بالایی ایجاد کنند که منجر به نمره بالای اعتبارسنجی میشود و در نتیجه وضعیت نامطلوبی رخ میدهد؛ بنابراین ما زیر نمونههای طبقهبندیشدهای ایجاد میکنیم که فرکانس را در کلاسهای متفاوت حفظ میکنند و به ما تصویر واضحی از عملکرد مدل را تحویل میدهند.
شکل قرار داده شده همین موضوع را با تصویری ساده بیان میکند.
قطعه کدی برای استفاده از این پیادهسازی:
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold,cross_val_score
from sklearn.linear_model import LogisticRegression
iris=load_iris()
X=iris.data
Y=iris.target
linear_reg=LogisticRegression()
Stratified_cross_validate=StratifiedKFold(n_splits=5)
score=cross_val_score(linear_reg,X,Y,cv=Stratified_cross_validate)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))
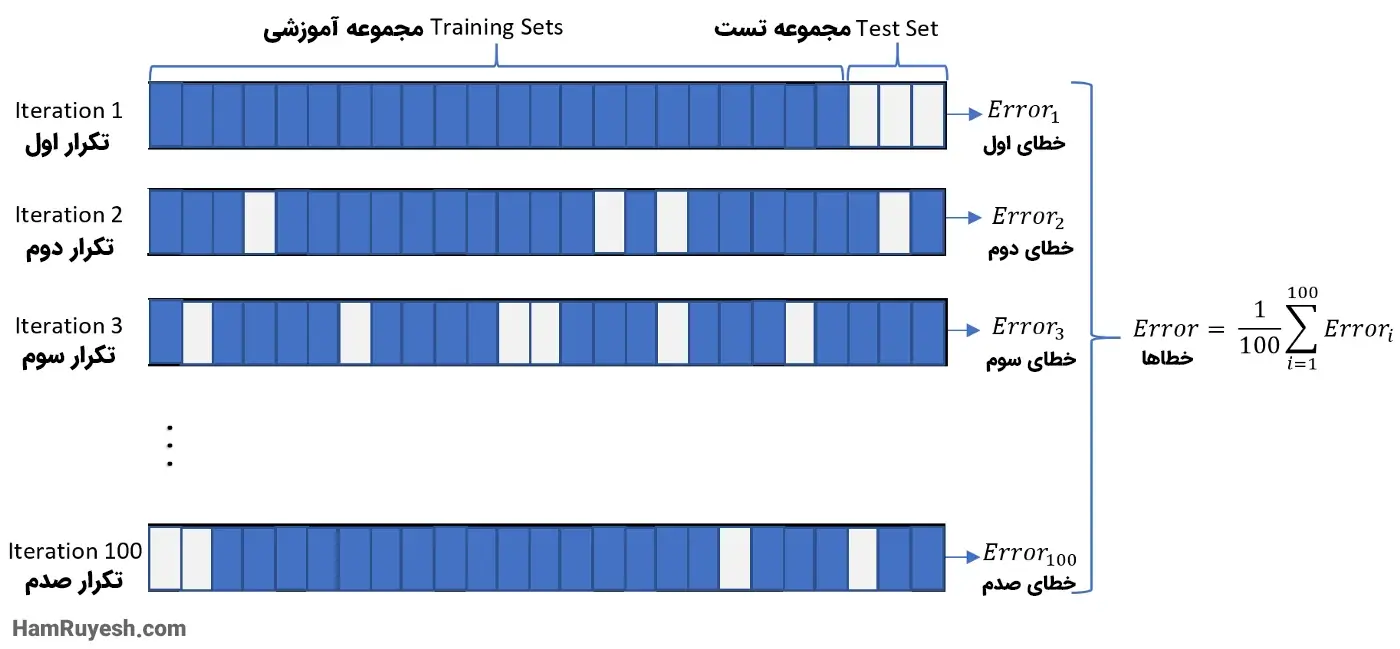
3. اعتبارسنجی متقابل Leave P Out
حذف P (Leave P) یکی از تکنیکهای جامع اعتبارسنجی متقابل (cross-validation) است که در آن از کل مجموعهداده برای چرخههای آموزش و اعتبارسنجی استفاده میشود. برای مثال فرض کنید ما تعداد 1000 داده در دیتاست خود داریم، اگر مقدار P را برابر 100 قرار دهیم، 100 عدد از داده ها برای اعتبارسنجی و 900 عدد از داده ها برای مقاصد آموزشی استفاده خواهند شد.تصویر زیر اعتبارسنجی متقابل P را نشان میدهد.

قطعه کدی برای استفاده از این روش:
from sklearn.model_selection import LeavePOut,cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
iris=load_iris()
X=iris.data
Y=iris.target
leave_p_out=LeavePOut(p=2)
leave_p_out.get_n_splits(X)
random_forrest_classifier=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)
score=cross_val_score(random_forrest_classifier,X,Y,cv=leave_p_out)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))
4. اعتبارسنجی متقابل Monte Carlo / تقسیم
این نوع اعتبارسنجی متقابل (cross-validation) بهعنوان یک استراتژی اعتبارسنجی متقابل انعطافپذیر استفاده میشود. با استفاده از این تکنیک، دادهها را به طور تصادفی به تعدادی پارتیشن تقسیم میکنیم، البته که ما خودمان درصد مجموعه آموزشی و اعتبارسنجی را تنظیم میکنیم، اما پارتیشنها به صورت تصادفی ایجاد میشوند. برای درک بهتر، تصویر زیر این تکنیک را به صورت بصری نمایش داده است:
قطعه کدی برای استفاده از این پیادهسازی:
from sklearn.model_selection import cross_val_score,ShuffleSplit
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
linear_regression=LogisticRegression()
shuffle_split=ShuffleSplit(test_size=0.3,train_size=0.5,n_splits=10)
cross_val_scores=cross_val_score(linear_regression,iris.data,iris.target,cv=shuffle_split)
print("cross Validation cross_val_scores:n {}".format(cross_val_scores))
print("Average Cross Validation score :{}".format(cross_val_scores.mean()))
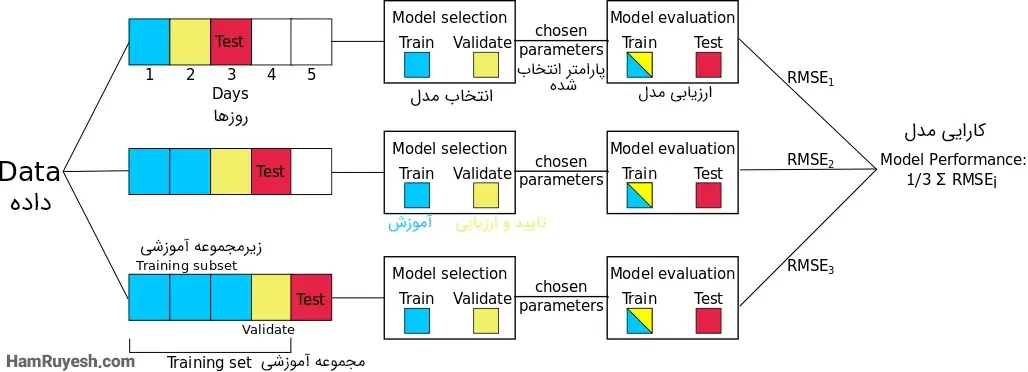
5. اعتبارسنجی متقابل Time Series
تکنیکهای عادی اعتبارسنجی متقابل برای وقتی که با مجموعهدادههای بر پایه زمان کار میکنیم مناسب نیستند. مجموعهدادههای بر پایه زمان را نمیتوان به صورت تصادفی تقسیم کرد و برای آموزش و اعتبارسنجی مدل استفاده کرد، به این دلیل که شاید بخش مهمی از اطلاعات مانند اطلاعات فصلی (seasonality که در واقع مشخصه یک سری زمانی است که دادهها در آن تغییرات منظم و قابلپیشبینی ای را تجربه میکنند) و غیره. با وجود مهم بودن ترتیب دادهها، تقسیم دادهها در هر بازه معینی دشوار است. برای مقابله با این مشکل میتوانیم از اعتبارسنجی متقابل سری زمانی استفاده کنیم.
در این نوع اعتبارسنجی متقابل، ما یک نمونه کوچک از دادهها (به صورت دستنخورده و با حفظ ترتیب) را میگیریم و سعی میکنیم نمونه بعدی را برای اعتبارسنجی پیشبینی کنیم. این عمل بهعنوان زنجیره پیشرو یا زنجیرهسازی جلوسو (forward chaining) و یا اعتبارسنجی متقابل متحرک (rolling cross validation) نیز شناخته میشود. ازآنجاییکه ما به طور مداوم در حال آموزش و اعتبارسنجی مدل بر روی مقادیر کوچک داده هستیم، مطمئناً میتوانیم یک مدل خوب پیدا کنیم که بتواند نتیجه خوبی را در این نمونههای چرخشی ارائه دهد. تصویر زیر نحوه پیادهسازی این تکنیک روی نمونهای از داده را نشان میدهد:
قطعه کد این اعتبارسنجی:
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4], [77,33]])
y = np.array([1, 2, 3, 4, 5, 6, 7])
rolling_time_series = TimeSeriesSplit()
print(rolling_time_series)
for current_training_samples, current_testing_samples in rolling_time_series.split(X):
print("TRAIN:", current_training_samples, "TEST:", current_testing_samples)
X_train, X_test = X[current_training_samples], X[current_testing_samples]
y_train, y_test = y[current_training_samples], y[current_testing_samples]
6. اعتبارسنجی متقابل K Fold
این اعتبارسنجی یکی از معروفترین تکنیکها برای پیادهسازی اعتبارسنجی متقابل است. تمرکز اصلی در این روش بر روی ایجاد “fold”های مختلف دادهها (معمولاً در اندازه برابر) است که ما از آنها برای اعتبارسنجی مدل استفاده میکنیم و بقیه دادهها برای فرایند آموزش استفاده میشوند. همه این فولدها به طور مکرر برای فرایند اعتبارسنجی و برای آموزش نمونه دادهها، با همدیگر ترکیب و سپس استفاده میشوند. همانطور که از نام آن مشخص است، چرخههای آموزشی در این تکنیک به تعداد K بار تکرار میشوند و دقت نهایی با گرفتن میانگین از اجراهای اعتبارسنجی دادهها محاسبه میشود. تصویر زیر اعتبارسنجی k fold را برای نمونه داده شده نشان میدهد:
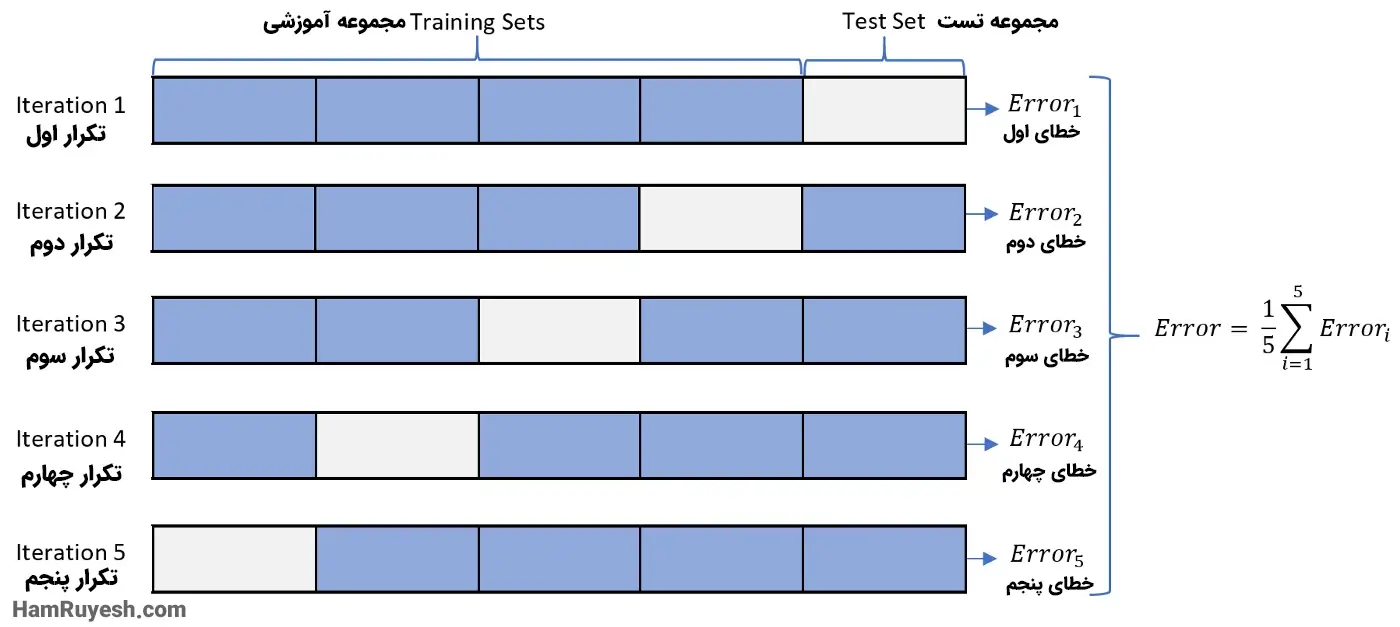
قطعه کدی برای استفاده از این روش:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,KFold
from sklearn.linear_model import LogisticRegression
iris=load_iris()
features=iris.data
outcomes=iris.target
logreg=LogisticRegression()
K_fold_validation=KFold(n_splits=5)
score=cross_val_score(logreg,features,outcomes,cv=K_fold_validation)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))
نتیجهگیری
ما تکنیکهایی را برای اعتبارسنجی متقابل مدلهای یادگیری ماشین بررسی کردیم، اینها تنها برخی از تکنیکهای برجسته هستند و مشخصاً روشهای دیگری نیز در این زمینه وجود دارد. انتخاب انواع روشهای اعتبارسنجی متقابل به طور گستردهای به نوع پیادهسازی، دادههای در دسترس، نوع محاسبات و رایانش و غیره بستگی دارد. البته که در برخی مواقع فرصتی برای ترکیب چندین روش مختلف برای بالا بردن اطمینان به نتایج حاصل شده و قابلیت تکرار آنها وجود دارد. امیدواریم این مقاله به شما کمک کند تا مدلهایی بهتر و بدون نقص ایجاد کنید و بتوانید مشکلات دنیای واقعی و جامعه را حل کنید.
کلیدواژگان
اعتبارسنجی متقابل | اعتبارسنجی متقابل چیست | اعتبارسنجی متقابل در یادگیری ماشین | cross-validation | cross validation | کراس ولیدیشن | روشهای اعتبارسنجی متقابل | بهترین روش اعتبارسنجی متقابل | اعتبارسنجی متقابل در یادگیری ماشین | مفهوم اعتبارسنجی متقابل | اعتبارسنجی متقابل چیست | اعتبارسنجی متقابل در یادگیری ماشین
منبع
Top Techniques for Cross-validation in Machine Learning NFT Work?







2 دیدگاه برای “بهترین روشهای اعتبارسنجی متقابل در یادگیری ماشین ”
ممنون از زحماتتون. نوشته خوب و مفیدیه. راستی پیشنهاد می کنم hyperpatameter رو فراپارامتر ترجمه کنیم نه ابرپارامتر. ابرپارامتر یه مقدار حس برتری و اهمیت ایجاد می کنه.
ممنونم از بازخورد شما مهندس آصفی عزیز. بله حتما رعایت میشه.