یادگیری ماشین، ابزاری برای تجزیه و تحلیل دادهها است که ساخت مدل تحلیلی را به صورت خودکار انجام میدهد. یادگیری ماشین، شاخهای از هوش مصنوعی، و بر اساس این ایده است که ماشینها میتوانند از دادهها یاد بگیرند، الگوها را تشخیص دهند و بدون هیچ قانون از پیش برنامه ریزی شدهای تصمیم گیری کنند. در این مقاله از مجله همرویش، قصد داریم به بیان مطالب زیر بپردازیم:
- ماشین لرنینگ چیست
- تاریخچه یادگیری ماشین
- روشهای یادگیری ماشین
ابتدا اجازه دهید کمی عمیق تر به تعریف یادگیری ماشین بپردازیم.
ماشین لرنینگ چیست؟

«یادگیری ماشین، یک برنامه کامپیوتری است که گوییم یک وظیفه (T) را با توجه به کسب تجربه (E) و بر اساس عملکرد (P) یاد میگیرد، هرگاه عملکرد آن در انجام وظایف (T) که با (P) اندازه گیری میشود، با تجربه (E) بهبود یابد»
حوزه یادگیری ماشین بسیار وسیع بوده و به سرعت در حال گسترش است. این حوزه، به طور مداوم به زیر شاخهها و انواع مختلف یادگیری ماشین تقسیم میشود. یادگیری ماشین، جنبه مهمی از تحقیق و کسب و کار مدرن است. یادگیری ماشین میتواند با استفاده از الگوریتمها و مدلهای شبکه عصبی، به بهبود تدریجی عملکرد برنامههای کامپیوتری با کمترین میزان دخالت نیروی انسانی کمک کند.
هم رویش منتشر کرده است:
آموزش یادگیری ماشین از صفر --- یادگیری سریع و آسان
همانطور که وقتی انسانها متولد میشوند، در ابتدا قادر به انجام هیچ وظیفه و کار مفیدی نیستند تا زمانی که به مرور آموزش داده شوند، کامپیوترها نیز میتوانند به همان شیوه یاد بگیرند. به عنوان یک مثال ساده، اگر بخواهید یک برنامه کامپیوتری بسازید که بتواند تشخیص دهد یک حیوان، سگ است یا گربه، میتوانید تصاویر زیادی از سگها و گربهها به آن نشان دهید. در نهایت، سیستم کامپیوتری قادر خواهد بود با استفاده از مدلهای آماری مبتنی بر دادههای قبلی، تشخیص دهد که آیا به یک گربه نگاه میکند یا یک سگ.
الگوریتمهای یادگیری ماشین اغلب در چند گونه دسته بندی میشوند. در این مقاله، چهار مورد از رایج ترین گونههای یادگیری ماشین را بررسی میکنیم:
- یادگیری ماشین تحت نظارت
- یادگیری ماشین بدون نظارت
- یادگیری نیمه نظارتی
- یادگیری تقویتی
اما قبل از پرداختن به این حوزهها، اجازه دهید ابتدا یک تاریخچه مختصر از یادگیری ماشین را با هم بررسی کنیم.
تاریخچه یادگیری ماشین
آرتور ساموئل (Arthur Samuel)، از پیشگامان آمریکایی حوزه هوش مصنوعی و بازیهای رایانهای، اصطلاح یادگیری ماشین را در سال 1959 مطرح کرد. ساموئل در همان سال، در حین کار در IBM، تحقیقی را منتشر کرد که در آن توانایی یک کامپیوتر دیجیتالی در رفتار کردن را به این شکل بیان کرده بود، “که اگر توسط انسان یا حیوان انجام شود، به صورت فرآیند یادگیری توصیف می شود”.
او ادعا میکرد که در آن زمان، رایانههایی با توانایی کافی در مدیریت دادهها وجود داشتند که میتوانستند از تکنیکهای یادگیری ماشین بهره ببرند، اما محدود به آگاهی بشر از این تکنیکها بودند.
ساموئل، برنامهای نوشت که با استفاده از برنامه پایهای بازی چکرز (checkers) او، این بازی را در سطح مسابقات قهرمانی انجام میداد. برنامه او، بازی را با استفاده از یک مدل تصمیم گیری مبتنی بر درخت یاد گرفت، در حالی که از چند حرکت قبل، بیشتر موقعیتهای بردن و باختن را تشخیص میداد.
از آنجا که این برنامه کامپیوتری، مقدار بسیار کمی از حافظه رایانه را در اختیار داشت، ساموئل چیزی به نام “هرس آلفا بتا” (alpha-beta pruning) ایجاد کرد. هرس آلفا بتا، یک الگوریتم جستجوی تخاصمی (adversarial) است که معمولاً برای انجام بازیهای دو نفره با ماشین، مانند شطرنج، چکرز و … استفاده میشد. طبق این الگوریتم، ارزیابی یک حرکت، زمانی متوقف میشود که حداقل یک احتمال یافت شود که ثابت کند این حرکت، بدتر از حرکتی است که قبلاً مورد بررسی قرار گرفته است.
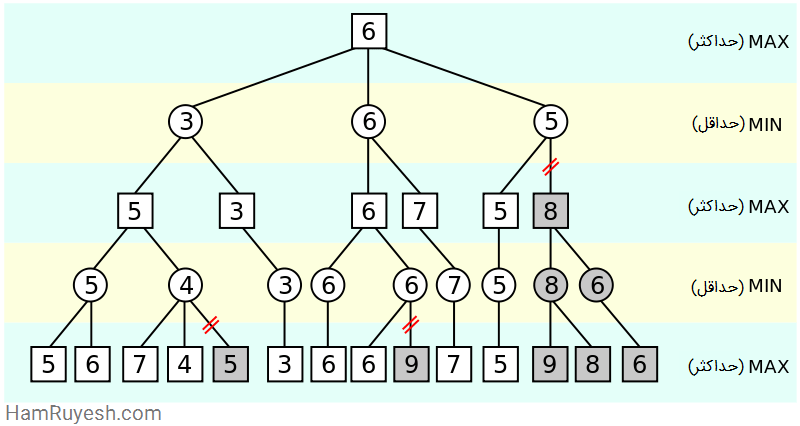
در شکل بالا، تصویری ساده از هرس آلفا بتا را مشاهده میکنیم. گرههای خاکستری شده، گرههایی هستند که برنامه، دیگر آنها را مورد بررسی قرار نمیدهد. حرکتها از چپ به راست ارزیابی میشوند.
ساموئل در نهایت، اینطور نتیجه گیری کرد که با یک قطعیت نسبی، می توان الگوریتمهای یادگیری ایجاد کرد که از یک فرد معمولی، بسیار بهتر عمل کند و در نهایت از نظر اقتصادی، برای حل مشکلات دنیای واقعی، قابل استفاده باشد.
هم رویش منتشر کرده است:
آموزش شبکه عصبی مصنوعی -- از صفر به زبان ساده
در سال 1961، اد فایگنباوم (Ed Feigenbaum) و جولیان فلدمن ( Julian Feldman)، مشغول خلق اولین گلچین هوش مصنوعی (computers and thought، 1961) بودند که از ساموئل خواستند بهترین بازی که برنامه یادگیری او انجام داده بود را به آنها ارائه دهد تا به عنوان ضمیمه به گلچین خود اضافه کنند. ساموئل از این فرصت استفاده کرد و با قهرمان چکرز ایالت کانکتیکات (Connecticut)، که در آن زمان رنک چهارم کشور را در اختیار داشت، مسابقه داد و برنده شد.
در دهههای 1980 و 1990 میلادی، یادگیری ماشین به عنوان یک حوزه جداگانه، مجددا سازماندهی شده و از حوزه هوش مصنوعی جدا شد. این حوزه، تمرکز خود را از رویکردهایی که از هوش مصنوعی به ارث برده بود، دور کرد و به جای آن، بر روی روشها و مدلهای مبتنی بر نظریه آمار و احتمالات تمرکز کرد. افزایش دسترسی به اطلاعات دیجیتالی و معرفی اینترنت، کمک شایانی به تحقیقات یادگیری ماشین کرد.
+ پیش از این آموزش شبکه عصبی LSTM برای پیش بینی قیمت بازار در همرویش منتشر شد. برای دیدن فیلم معرفی این بسته بر روی این لینک (+) و یا پخش کننده پایین کلیک کنید:
برای دریافت بسته کامل آموزش اینجا(+) کلیک کنید.
انواع روش های یادگیری ماشین
اکنون که با تاریخچه مختصری از یادگیری ماشین آشنا شدیم، اجازه دهید به توضیح چهار دسته اصلی این حوزه بپردازیم:
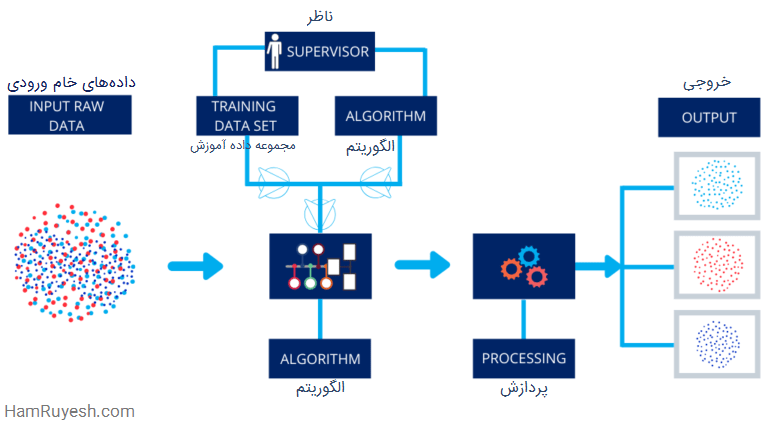
یادگیری ماشین تحت نظارت (Supervised Machine Learning)
این یک الگوریتم است که میتواند دادههای قبلاً آموخته شده با استفاده از مثالهای برچسب دار را به دادههای جدید اعمال کرده و رویدادهای آینده را پیش بینی کند. در این الگوریتم، نتایج آموزش از قبل مشخص شده است، اما سیستم به سادگی یاد میگیرد که چگونه به این نتایج برسد.
دسته بندی (Classification):
فرایندی است که تشخیص میدهد یک مشاهده یا یک داده، به کدام دسته از دستههای موجود تعلق دارد.
در روش دسته بندی، با استفاده از دادهها و مشاهدات قبلی، مشخص میشود که مشاهدات جدید، متعلق به کدام دسته هستند و برچسبهای موجود، به مشاهدات جدید اختصاص داده میشوند. یک مثال از این روش، شناسایی حیوانات از طریق تصاویر است (که آیا این تصویر سگ است یا گربه؟).
این روش در برخی از برنامههای کاربردی شامل تشخیص بیماری در حوزه پزشکی، بازاریابی هدفمند و بانکداری، مورد استفاده قرار میگیرد.
رگرسیون (Regression):
در این روش، از مدلها برای پیش بینی مقادیر پیوسته عددی استفاده میشود. به عنوان مثال، پیش بینی قیمت خودرو با توجه به عواملی مانند اسب بخار، اندازه و …، یکی از نمونههای رایج رگرسیون است.
این روش، شکلی از یادگیری ماشین تحت نظارت است و انواع مختلفی از روشها را شامل میشود که اگر بخواهیم چند مورد از آنها را نام ببریم، میتوانیم به رگرسیون خطی، رگرسیون منطقی (logistic)، رگرسیون درخت تصمیم، رگرسیون جنگل تصادفی و رگرسیون چند جملهای اشاره کنیم.
یادگیری بدون نظارت (Unsupervised Machine Learning)
این یک الگوریتم یادگیری ماشین است که در آن، گروهی از مشاهدات یا دادهها به برنامه داده میشود و برنامه باید الگوها یا روابط موجود در مجموعه دادهها را پیدا کند.
برخلاف یادگیری تحت نظارت، اطلاعات مورد استفاده در یادگیری بدون نظارت، نه طبقه بندی شده و نه برچسب گذاری شده است. این سیستم برای یافتن راه حل صحیح مورد استفاده قرار نمیگیرد، بلکه مجموعه دادهها را بررسی کرده و استنباط خود را بیان میکند.

برخی از رایج ترین الگوریتمهای مورد استفاده در یادگیری ماشین بدون نظارت عبارتند از:
خوشه بندی (Clustering):
وظیفه تحلیل خوشهای این است که مجموعهای از مشاهدات یا دادهها را گروه بندی کند، به گونهای است که اشیاء موجود در یک خوشه، نسبت به سایر گروهها (خوشه ها)، شباهت بیشتری با یکدیگر داشته باشند. این یک تکنیک رایج برای تحلیل دادههای آماری است و عمدتا در تشخیص الگو، تجزیه و تحلیل تصاویر، فشرده سازی دادهها، و بیوانفورماتیک مورد استفاده قرار میگیرد.
لازم به ذکر است که تحلیل خوشهای، یک الگوریتم خاص نیست بلکه عملی است که توسط الگوریتمهای مختلف، قابل دستیابی است. این الگوریتمها میتوانند به طور قابل توجهی در پارامترهای تعریفی خود در مورد آنچه که یک خوشه را واجد شرایط میکند، متفاوت باشند. الگوریتمهای مختلف میتوانند رویکردهای متفاوتی برای شناسایی و گروه بندی خوشهها داشته باشند و بسته به توسعه دهنده یا برنامه کامپیوتری، سطوح مختلفی از عملکرد را خواهند داشت.

یادگیری نیمه نظارتی (Semi-supervised Machine Learning)
این نوع یادگیری ماشین، چیزی بین یادگیری تحت نظارت و یادگیری بدون نظارت است. این موضوع به این دلیل است که این روش، از هر دو نوع داده بدون برچسب و با برچسب برای آموزش استفاده میکند. معمولاً مقدار کمی از دادههای برچسب گذاری شده و مقدار زیادی از دادههای بدون برچسب. استفاده از دادههای بدون برچسب همراه با مقدار کمی از دادههای برچسب دار، میتواند پیشرفت قابل ملاحظهای در دقت یادگیری ماشین ایجاد کند.
یادگیری ماشین تقویتی (Reinforcement Machine Learning)
این روش یادگیری، روشی است که با انجام یکسری اعمال، با محیط خود در تعامل است و خطاها یا بینشها را کشف میکند. این فرایند یادگیری ماشین معمولاً شامل آزمون و خطاهای زیادی است تا دادهها را جمع آوری کند و تصمیمات ایده آل در یک زمینه خاص را تشخیص دهد. یک پاداش ساده به عنوان فیدبک برای ماشین مورد نیاز است تا یاد بگیرد بهترین عمل کدام است.
یادگیری تقویتی به ویژه برای مسائلی مطلوب است که در آنها، یک نوع مصالحه بین پاداش بلند مدت و کوتاه مدت وجود دارد. علاوه بر این، هنگامی که دادههای تاریخی کمی درباره یک مسئله وجود دارد یا اصلا دادهای وجود ندارد، از این روش استفاده میشود؛ زیرا از قبل به هیچ اطلاعاتی نیاز ندارد.
از این نوع یادگیری ماشین میتوان در محیطهای بزرگ در شرایط زیر استفاده کرد:
- روشهای جمع آوری اطلاعات در مورد محیط، تنها به فعل و انفعالات (تعاملات) محدود باشد.
- فقط یک شبیه سازی از محیط ارائه شده باشد
- مدل محیط شناخته شده باشد اما هیچ راه حل تحلیلی در دسترس نباشد.
نکته منفی یادگیری تقویتی این است که اگر مسئله پیچیده باشد، به زمان زیادی برای آموزش نیاز دارد.
نتیجه گیری
چندین الگوریتم دیگر برای یادگیری ماشین وجود دارد، اما در این مقاله تنها چهار مورد از رایج ترین الگوریتمها مورد بررسی قرار گرفتند. توصیه میکنیم مقالات دیگر ما را درباره یادگیری ماشین مطالعه کنید تا درک عمیق تری از موضوع بدست بیاورید.
+ پیش از این آموزش اجرای پروژه یادگیری ماشین با پایتون در همرویش منتشر شد. برای دیدن فیلم معرفی این آموزش بر روی این لینک (+) و یا پخش کننده زیر کلیک کنید:
دریافت این بسته آموزشی در لینک زیر:
آموزش اجرای یک پروژه یادگیری ماشین با پایتون
کلیدواژگان
ماشین لرنینگ چیه | machine learning چیست | یادگیری ماشین چیست | انواع روش های یادگیری ماشین | مدل های یادگیری ماشینی | ماشین لرنینگ چیست