آشنایی با خودرمزگذارها
خودرمزگذار یا اتوانکدر (autoencoder) چیست؟ اجزای اصلی یک خودرمزگذار کدامند؟ معماریهای مختلف خودرمزگذارها چگونه هستند؟ کاربرد خودرمزگذارها در چه مواردی است؟ در این مقاله از مجله همرویش، به دنبال پاسخ این سوالات خواهیم بود.
خودرمزگذار چیست؟
خودرمزگذارها یا اتوانکدرها (Autoencoders)، یک روش یادگیری بدون نظارت به حساب میآیند که در آن، از شبکههای عصبی برای یادگیری یک بازنمایی (representation learning) استفاده میکنیم.
به عبارت دیگر، خودرمزگذار، یک شبکه عصبی مصنوعی بدون نظارت است که نحوه فشردهسازی (compress) و رمزگذاری (encode) موثر دادهها را میآموزد و سپس یاد میگیرد که چگونه دادهها را از بازنمایی رمزگذاری شدهی کاهش یافته، به یک بازنمایی که تا حد امکان نزدیک به ورودی اصلی است، بازسازی (reconstruct) کند.
در شکل زیر، نمونهای از تصویر ورودی-خروجی از مجموعه داده MNIST به یک خودرمزگذار نشان داده شده است.

هم رویش منتشر کرده است:
آموزش شبکه عصبی مصنوعی -- از صفر به زبان ساده
اجزای اصلی خودرمزگذار
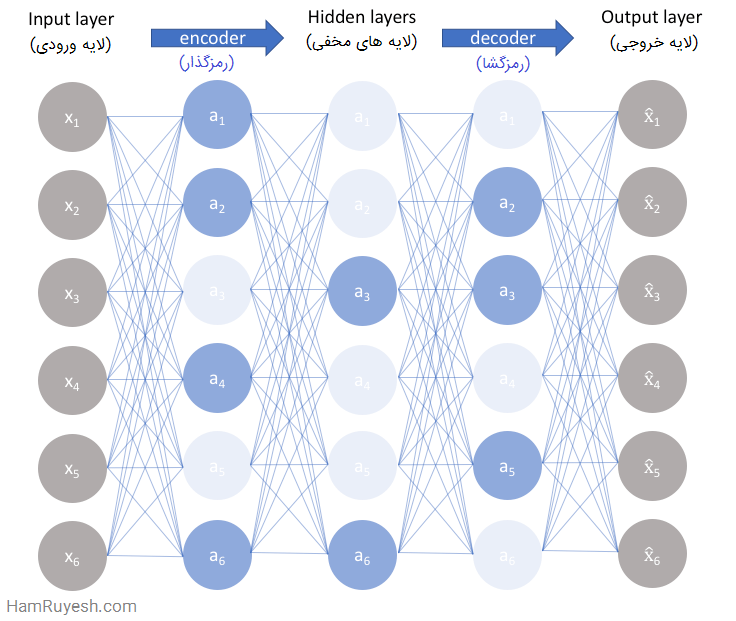
خودرمزگذارها از چهاربخش اصلی تشکیل شدهاند:
1- رمزگذار (Encoder)
در این بخش، مدل یاد میگیرد که چگونه ابعاد ورودی را کاهش دهد و دادههای ورودی را به یک بازنمایی رمزگذاری شده فشرده تبدیل کند.
2- تنگه یا گلوگاه (Bottleneck)
لایهای که شامل بازنمایی فشرده از دادههای ورودی است. این کمترین ابعاد ممکن از دادههای ورودی است.
3- رمزگشا (Decoder)
در این بخش، مدل یاد میگیرد که چگونه دادهها را از بازنمایی رمزگذاری شده بازسازی کند و این بازسازی تا جایی که ممکن است باید به ورودی اصلی نزدیک باشد.
4- تلفات بازسازی (reconstruction loss)
روشی است که میزان خوب بودن عملکرد رمزگشا و میزان نزدیکی خروجی به ورودی اصلی را اندازه گیری میکند.
ساختار کلی خودرمزگذار
به طور مشخص، ما معماری شبکه عصبی را طوری طراحی میکنیم که یک گلوگاه در شبکه ایجاد شود. اینگونه، شبکه مجبور به تولید یک بازنمایی فشرده از ورودی اصلی خواهد شد.
اگر ویژگیهای ورودی، هر کدام مستقل از یکدیگر باشند، این فشردهسازی و بازسازی متعاقب آن، کار بسیار دشواری خواهد بود. با این حال، اگر نوعی ساختار در دادهها وجود داشته باشد (یعنی همبستگی بین ویژگیهای ورودی)، این ساختار را میتوان آموخت و در نتیجه هنگام عبور دادن ورودی از گلوگاه شبکه، از آن استفاده کرد.

همانطور که در تصویر بالا نشان داده شده است، میتوانیم یک مجموعه داده بدون برچسب را برداریم و آن را به عنوان یک مسئله یادگیری تحت نظارت، چارچوببندی کنیم که وظیفه دارد را که یک بازسازی (reconstruction) از ورودی اصلی یعنی x هست، در خروجی تولید کند. این شبکه را میتوان با به حداقل رساندن خطای بازسازی، یعنی ، که اختلاف بین ورودی اصلی ما و بازسازی متعاقب آن را اندازه گیری میکند، آموزش داد.
گلوگاه، یک ویژگی کلیدی در طراحی شبکه ما به حساب میآید. بدون وجود گلوگاه اطلاعات، شبکه ما به راحتی میتوانست یاد بگیرد که مقادیر ورودی را با گذراندن آنها از شبکه، به خاطر بسپارد (همانگونه که در تصویر زیر نشان داده شده است).

یک گلوگاه، مقدار اطلاعاتی که میتواند از کل شبکه عبور کند را محدود کرده و شبکه را وادار به ایجاد یک فشردهسازی آموخته شده از دادههای ورودی میکند.
توجه: در حقیقت، اگر بخواهیم یک شبکه خطی بسازیم (یعنی بدون استفاده از توابع فعالسازی غیر خطی در هر لایه)، کاهش ابعادی را مشاهده میکنیم که مشابه آن در PCA (تجزیه مولفههای اصلی) مشاهده شده است. بحث جفری هینتون (Hinton) در این زمینه را از اینجا ببینید.
مدل ایده آل خودرمزگذار، بین موارد زیر در تعادل است:
- به اندازه کافی به ورودیها حساس است تا یک بازسازی دقیق را ایجاد کند.
- به اندازه کافی به ورودیها غیرحساس است تا مدل، به سادگی دادههای آموزشی را به خاطر نسپارد یا بیش برازش رخ ندهد.
این تعادل یا مصالحه، مدل را مجبور میکند که فقط آن تغییراتی را در دادهها حفظ کند که برای بازسازی ورودی، بدون نگه داشتن اضافات درون ورودی، مورد نیاز است. در بیشتر موارد، این کار شامل ایجاد یک تابع ضرر یا تابع تلفات (loss function) است که در آن، یک عبارت، مدل ما را تشویق میکند تا نسبت به ورودیها حساس باشد (یعنی تلفات بازسازی ) و یک عبارت دوم که از به خاطر سپردن یا بیش برازش جلوگیری میکند (یعنی یک تنظیم کننده اضافه شده).

ما معمولاً یک پارامتر مقیاسدهی را در جلوی عبارت تنظیمسازی (regularization) اضافه میکنیم تا بتوانیم تعادل بین دو هدف را تنظیم کنیم.
در این مقاله، برخی از معماریهای استاندارد خودرمزگذار را برای اعمال این دو محدودیت و تنظیم تعادل، مورد بحث قرار میدهیم. در سایر مقالات، در مورد خودرمزگذارهای تغییر پذیر که بر اساس مفاهیم مورد بحث در اینجا برای ارائه یک مدل قویتر ایجاد میشوند، بحث خواهیم کرد.
معماریهای استاندارد خودرمزگذار
خودرمزگذار ناقص (Undercomplete autoencoder)
سادهترین معماری برای ساخت خودرمزگذار، محدود کردن تعداد گرههای موجود در لایه (های) مخفی شبکه است که مقدار اطلاعاتی عبوری از شبکه را محدود میکند.
با جریمه کردن شبکه با توجه به خطای بازسازی، مدل ما میتواند مهمترین ویژگیهای دادههای ورودی و بهترین نحوه بازسازی ورودی اصلی از یک حالت “رمزگذاری شده” را یاد بگیرد. در حالت ایده آل، این رمزگذاری، ویژگیهای نهفته (latent attributes) دادههای ورودی را یاد میگیرد و توصیف میکند.

از آنجا که شبکههای عصبی قادر به یادگیری روابط غیر خطی هستند، میتوان این موضوع را به عنوان یک تعمیم (غیرخطی) قویتر از PCA در نظر گرفت. در حالی که PCA تلاش میکند ابرصفحهای با ابعاد کمتر را کشف کند که دادههای اصلی را توصیف میکند، خودرمزگذارها قادر به یادگیری خمینههای غیرخطی هستند (یک خمینه یا manifold، به زبان ساده، به صورت یک سطح پیوسته و غیر متقاطع تعریف میشود). تفاوت این دو روش در شکل زیر نشان داده شده است.

برای دادههای با ابعاد بالاتر، خودرمزگذارها قادر به یادگیری یک بازنمایی پیچیده از دادهها (خمینه) هستند که میتواند برای توصیف مشاهدات در ابعاد کمتر استفاده شود و به صورت متناظر، در فضای ورودی اصلی رمزگشایی شود.

یک خودرمزگذار ناقص، هیچ عبارت تنظیمسازی صریحی ندارد؛ ما به سادگی مدل خود را با توجه به تلفات بازسازی آموزش میدهیم. بنابراین، تنها راه ما برای اطمینان از اینکه مدل، دادههای ورودی را به خاطر نمیسپارد، این است که مطمئن شویم تعداد گرهها را در لایه (های) مخفی، به اندازه کافی محدود کردهایم.
برای خودرمزگذارهای عمیق، باید از ظرفیت مدلهای رمزگذار و رمزگشای خود نیز مطلع باشیم. حتی اگر “لایه گلوگاه” فقط یک گره مخفی باشد، هنوز هم برای مدل ما این امکان وجود دارد که دادههای آموزشی را به خاطر بسپارد؛ به شرطی که مدلهای رمزگذار و رمزگشا دارای توانایی کافی برای یادگیری برخی از توابع دلخواه باشند که بتوانند دادهها را به یک اندیس نگاشت کنند.
هم رویش منتشر کرده است:
آموزش ساخت شبکه عصبی با پایتون (و دیگر زبانها) از صفر
با توجه به این واقعیت که دوست داریم مدل ما ویژگیهای نهفته درون دادههایمان را کشف کند، باید اطمینان حاصل کنیم که مدل خودرمزگذار، نمی تواند یک روش کارآمد برای به خاطر سپردن دادههای آموزشی یاد بگیرد.
مشابه مسائل یادگیری تحت نظارت، میتوانیم از اشکال مختلف تنظیمسازی در شبکه به منظور تشویق خواص خوب تعمیم استفاده کنیم؛ این تکنیکها در ادامه مورد بحث قرار گرفتهاند.
خودرمزگذارهای پراکنده (Sparse autoencoders)
خودرمزگذارهای پراکنده یک روش جایگزین برای معرفی یک گلوگاه اطلاعات بدون نیاز به کاهش تعداد گرهها در لایههای مخفی به ما ارائه میدهند. در عوض، تابع تلفات خود را طوری ایجاد میکنیم که فعالسازیهای درون یک لایه را جریمه کنیم.
به ازای هر مشاهده، شبکه خود را تشویق میکنیم تا یک رمزگذاری و رمزگشایی را یاد بگیرد که فقط متکی بر فعال کردن تعداد کمی از نورونها است. شایان ذکر است که این، یک رویکرد متفاوت نسبت به تنظیمسازی است، زیرا ما معمولا وزنهای یک شبکه را تنظیم میکنیم، نه فعالسازیها را.
یک خودرمزگذار پراکنده عمومی، در شکل زیر نمایش داده شده است که در آن، میزان شفافیت یا تیرگی یک گره، متناظر با سطح فعالسازی است. باید توجه داشته باشید که گرههای یک مدل آموزش دیده که فعالسازی را انجام میدهند، وابسته به دادهها هستند؛ ورودیهای مختلف منجر به فعال شدن گرههای مختلف در طول شبکه میشود.
یکی از نتایج این واقعیت، این است که ما به شبکه خود اجازه میدهیم تا گرههای لایه مخفی را نسبت به ویژگیهای خاص دادههای ورودی حساس کند. در حالی که یک خودرمزگذار ناقص، از کل شبکه برای هر مشاهده استفاده میکند، یک خودرمزگذار پراکنده مجبور میشود ناحیههای شبکه را بسته به دادههای ورودی، به صورت انتخابی فعال کند.
در نتیجه، ما ظرفیت شبکه را برای به خاطر سپردن دادههای ورودی محدود کردهایم، بدون اینکه قابلیت شبکه برای استخراج ویژگیها از دادهها محدود شود. این موضوع، به ما این امکان را میدهد که بازنمایی وضعیت نهفته و تنظیمسازی شبکه را به طور جداگانه در نظر بگیریم، به طوری که میتوانیم یک بازنمایی وضعیت نهفته (یعنی رمزگذاری ابعاد) را مطابق با آنچه که با توجه به چارچوب دادهها منطقی به نظر میآید، انتخاب کنیم و در عین حال، تنظیمسازی را با قید پراکندگی اعمال کنیم.
دو راه اصلی وجود دارد که میتوانیم از طریق آنها، این قید پراکندگی را اعمال کنیم. هر دو راه، شامل اندازه گیری فعالسازیهای لایه مخفی برای هر دسته آموزشی و اضافه کردن چند عبارت به تابع تلفات برای جریمه کردن فعالسازیهای بیش از حد است. این عبارتها به شرح زیر هستند:
تنظیمسازی L1
میتوانیم یک عبارت به تابع تلفات خود اضافه کنیم که مقدار مطلق بردار فعالسازی a در لایه h را برای مشاهده i جریمه میکند که توسط پارامتر تنظیم λ مقیاس دهی شده است.

واگرایی KL
در اصل، واگرایی KL، اندازه گیری اختلاف بین دو توزیع احتمال است. ما میتوانیم یک پارامتر پراکندگی ρ تعریف کنیم که نشان دهنده فعالسازی متوسط یک نورون روی مجموعهای از نمونهها است. این امید ریاضی را میتوان به صورت زیر محاسبه کرد:

در آن، اندیس j نشان دهنده نورون خاص در لایه h است، و مجموع فعالسازیها برای m مشاهده آموزشی که هر کدام با x نشان داده شده است، محاسبه میشود.
در اصل، با محدود کردن فعالسازی متوسط یک نورون بر روی مجموعهای از نمونهها، نورونها را تشویق میکنیم که فقط برای زیرمجموعهای از مشاهدات شلیک کنند. میتوانیم ρ را به عنوان یک توزیع متغیر تصادفی برنولی توصیف کنیم تا بتوانیم از واگرایی KL استفاده کنیم (که در زیر بسط داده شده) تا توزیع ایده آل ρ را با توزیعهای مشاهده شده در تمام گرههای لایه پنهان مقایسه کنیم.

توجه: توزیع برنولی، “توزیع احتمال یک متغیر تصادفی است که مقدار 1 را با احتمال p و مقدار 0 را با احتمال q = 1 − p میگیرد”. این موضوع به خوبی با ایجاد احتمال شلیک یک نورون مطابقت دارد.
واگرایی KL بین دو توزیع برنولی را میتوان به صورت زیر نوشت:

این عبارت تلفات (loss term)، در شکل زیر برای یک توزیع ایده آل با ρ = 0.2، که متناظر با حداقل مجازات در این نقطه (یعنی صفر) است، نمایش داده شده است.

خودمزگذارهای حذف نویز (Denoising autoencoders)
تا اینجا، مفهوم آموزش یک شبکه عصبی را بیان کردیم که در آن، ورودی و خروجیها یکسان است و مدل ما وظیفه دارد ورودی را در حین عبور از نوعی گلوگاه اطلاعات، تا حد ممکن ]نزدیک به ورودی اصلی[ بازتولید کند.
اگر یادتان باشد، اشاره کردیم که دوست داریم خودرمزگذار ما، به اندازه کافی حساس باشد تا بتواند مشاهده اصلی را بازآفرینی کند، اما نسبت به دادههای آموزشی به اندازه کافی غیرحساس باشد به گونهای که یک مدل رمزگذاری و رمزگشایی قابل تعمیم را یاد بگیرد.
رویکرد دیگر در جهت توسعه یک مدل قابل تعمیم، این است که دادههای ورودی را کمی خراب کنیم اما همچنان دادههای خراب نشده را به عنوان خروجی هدف خود حفظ کنیم.

با این رویکرد، مدل ما نمیتواند به سادگی یک نگاشت بسازد تا دادههای آموزشی را به خاطر بسپارد، زیرا ورودی و خروجی هدف ما دیگر یکسان نیستند.
در عوض، مدل، یک میدان برداری برای نگاشت دادههای ورودی به یک خمینه با ابعاد کمتر را یاد میگیرد (از تصاویر قبلی به یاد بیاورید که یک خمینه، ناحیه با تراکم بالا را توصیف میکند که دادههای ورودی در آن متمرکز هستند)؛ اگر این خمینه، دادههای طبیعی را به درستی توصیف کند، ما نویز اضافه شده را به طور موثری “حذف” کردهایم.

شکل بالا، میدان برداری توصیف شده از طریق مقایسه بازسازی x با مقدار اصلی x را به تصویر کشیده است. نقاط زرد نشان دهنده نمونههای آموزشی قبل از افزودن نویز هستند. همانطور که میبینید، مدل یاد گرفته است که ورودی خراب را در جهت خمینه آموخته شده تنظیم کند.
شایان ذکر است که این میدان برداری به طور معمول فقط در مناطقی که مدل در طول آموزش مشاهده کرده است به خوبی رفتار میکند. در مناطق دور از توزیع دادههای طبیعی، خطای بازسازی بزرگ است و همیشه در جهت توزیع درست نیست.

خودرمزگذارهای انقباضی (Contractive autoencoders)
میتوان انتظار داشت که برای ورودیهای بسیار مشابه، رمزگذاری آموخته شده نیز بسیار مشابه باشد. ما میتوانیم مدل خود را به صراحت آموزش دهیم تا همین طور باشد؛ با نیاز به این که مشتق فعالسازیهای لایه مخفی، نسبت به ورودی کوچک باشد. به عبارت دیگر، برای تغییرات کوچک در ورودی، ما هنوز باید یک وضعیت رمزگذاری بسیار مشابه را حفظ کنیم.
این کاملا شبیه یک خودرمزگذار حذف نویز است، از این نظر که این اغتشاشات کوچک در ورودی، در اصل نویز محسوب میشوند و ما دوست داریم مدل در برابر نویز مقاوم باشد. به عبارت دیگر (با تأکید خودم)، “خودرمزگذارهای حذف نویز باعث میشوند تابع بازسازی (یعنی رمزگشا) در برابر اغتشاشات کوچک اما با اندازه محدود ورودی مقاومت کند، در حالی که خودرمزگذارهای انقباضی، تابع استخراج ویژگی (یعنی رمزگذار) را در برابر اغتشاشات بینهایت کوچک ورودی مقاوم میکنند. ”
از آنجا که ما مدل خود را به طور صریح برای یادگیری یک رمزگذاری تشویق میکنیم که در آن، ورودیهای مشابه دارای رمزگذاریهای مشابه هستند، ما اساسا مدل را مجبور میکنیم که یاد بگیرد چگونه یک همسایگی از ورودیها را به یک همسایگی کوچکتر از خروجیها جمع یا منقبض (contract) کند. توجه کنید که چگونه شیب (یعنی مشتق) دادههای بازسازی شده، اساسا برای همسایگیهای محلی دادههای ورودی، برابر با صفر است.

ما میتوانیم این کار را با ایجاد یک عبارت تلفات انجام دهیم. این عبارت، مشتقات بزرگ از فعالسازیهای لایه مخفی ما را با توجه به نمونههای آموزشی ورودی مجازات میکند؛ در اصل مواردی را جریمه میکند که در آنها، یک تغییر کوچک در ورودی منجر به تغییر بزرگ در فضای رمزگذاری میشود.
از نظر ریاضیاتی، ما میتوانیم عبارت مربوط به تلفات تنظیم خود را به صورت مربع نرم فروبنیوس از ماتریس ژاکوبین J برای فعالسازیهای لایه پنهان با توجه به مشاهدات ورودی، بسازیم.
یک نرم فروبنیوس (Frobenius norm)، اساسا یک نرم L2 برای یک ماتریس است و ماتریس ژاکوبین، به سادگی همه مشتقات جزئی مرتبه اول یک تابع با مقادیر برداری را نشان میدهد (در اینجا، ما یک بردار از نمونههای آموزشی داریم).
برای m مشاهده و n گره لایه مخفی، میتوانیم این مقادیر را به صورت زیر محاسبه کنیم.

به صورت خلاصهتر میتوانیم تابع تلفات کامل خود را به صورت زیر تعریف کنیم.

کاربردهای خودرمزگذارها
شاید از خودتان بپرسید چرا یک شبکه عصبی را فقط برای تولید خروجی تصویر یا دادهای که دقیقاً مشابه ورودی است آموزش میدهیم؟! در ادامه، به رایجترین موارد استفاده از خودرمزگذارها را اشاره میکنیم.
تشخیص ناهنجاری
در آمار، نقاط پرت یا ناهنجاریها، نقاط دادهای هستند که به جمعیت مشخصی تعلق ندارند. این یک مشاهده غیرطبیعی است که با مقادیر دیگر فاصله دارد. یک ناهنجاری، مشاهدهای است که از دادههای خوب ساختار یافته جدا میشود.
وقتی مشاهدات فقط یک دسته اعداد و یک بعدی هستند، تشخیص آنها آسان است، اما وقتی هزاران مشاهده چند بعدی داشته باشید، برای تشخیص این مقادیر به روشهای هوشمندانهتری نیاز خواهید داشت.
حذف نویز از دادهها (نظیر تصاویر یا صدا)

دینویزینگ (Denoising)، فرایند حذف نویز از یک سیگنال است. این سیگنال میتواند یک تصویر، صدا یا یک سند باشد. میتوان یک شبکه خودرمزگذار را به منظور یادگیری نحوه حذف نویز از تصاویر، آموزش داد.
- رنگ آمیزی تصاویر
- بازیابی اطلاعات
خلاصه
خودرمزگذار، یک معماری شبکه عصبی است که قادر به کشف ساختار درون دادهها به منظور ایجاد یک بازنمایی فشرده از ورودی است. خودرمزگذار با یادگیری نحوه نادیده گرفتن نویز در دادهها، میتواند ابعاد آنها را کاهش دهد. در نهایت، فرایند آموزش شامل استفاده از پس انتشار به منظور به حداقل رساندن تلفات بازسازی شبکه خواهد بود.
انواع مختلفی از معماری عمومی خودرمزگذار با هدف اطمینان از اینکه بازنمایی فشرده، نشان دهنده ویژگیهای معنیدار دادههای اصلی ورودی است، وجود دارد. به طور معمول، بزرگترین چالش هنگام کار با خودرمزگذارها این است که کاری کنید تا مدل شما، واقعا یک بازنمایی فضای نهفته معنادار و قابل تعمیم را یاد بگیرد.
از آنجا که خودرمزگذارها نحوه فشردهسازی دادهها را بر اساس ویژگیها (یعنی همبستگی بین بردار ویژگی ورودی) که از دادهها در طول آموزش کشف میشود، میآموزند، این مدلها معمولا فقط قادر به بازسازی دادهها، مشابه کلاس مشاهداتی هستند که مدل در طول آموزش مشاهده کرده است.
کلیدواژگان
اتوانکدر چیست | شبکه عصبی خودرمزگذار متغیر | اتوانکدر یعنی چه | اتوانکدر چیست به زبان ساده | Autoencoder چیست | خودرمزگذارها چیست | خودرمزگذارها چیست به زبان ساده | خودرمزگذارها چیست با مثال | خودرمزگذارها چیست توضیح دهید | اتوانکدر یا خودرمزگذار چیست
منابع
دوره های آموزشی مرتبط
-
 آموزش تنسورفلو __ پیاده سازی شبکه های عصبی با TensorFlow
۹۲,۰۰۰ تومان
آموزش تنسورفلو __ پیاده سازی شبکه های عصبی با TensorFlow
۹۲,۰۰۰ تومان -
 آموزش یادگیری ماشین از صفر --- یادگیری سریع و آسان
۶۸,۰۰۰ تومان
آموزش یادگیری ماشین از صفر --- یادگیری سریع و آسان
۶۸,۰۰۰ تومان







1 دیدگاه برای “اتوانکدر (Autoencoder) یا خودرمزگذار چیست؟ ”
ممنون از ترجمه و بسط خوب آقای مهندس ماجدی نیا